 A L I D A
A L I D A
4. Keyframes
4.1. Inverse Depth Update
To be added
4.2. Immature Point Activation
To be added
4.3. Sliding Window Optimization
4.3.1. Error Function Formulation

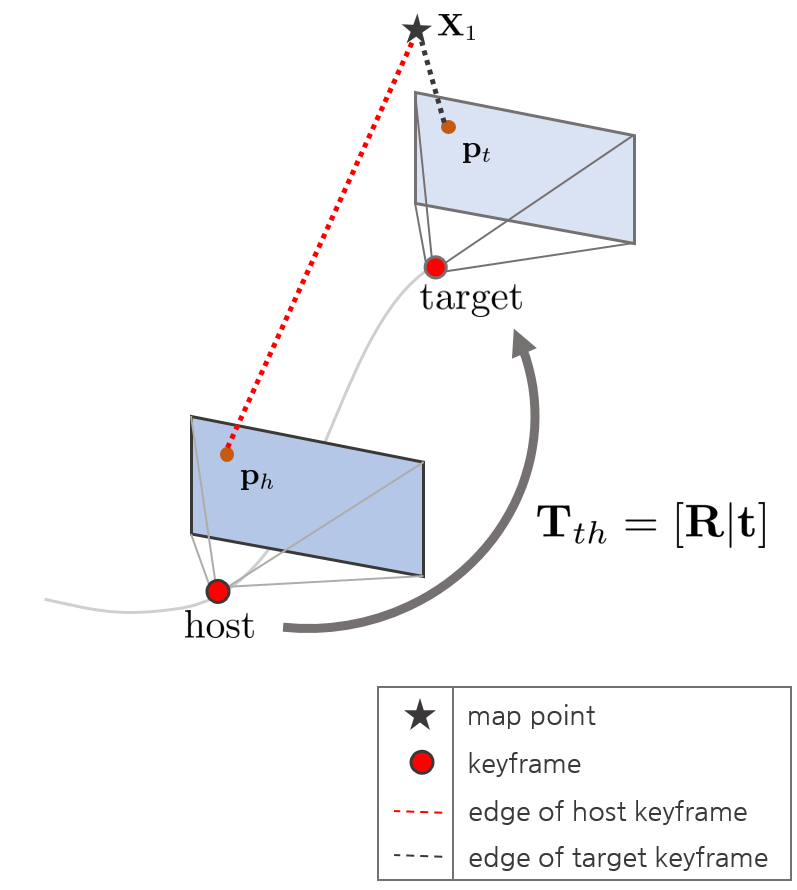
특정 프레임이 키프레임으로 결정되면 sliding window 내부의 키프레임들과 새로운 키프레임 사이에 에러함수를 업데이트해야 한다. 이 때, 키프레임 뿐만 아니라 이와 연결되어 있는 맵 상의 포인트들까지 같이 최적화하는 Local Bundle Adjustment (LBA)를 수행한다.

주목할 점은 하나의 맵포인트가 두 개의 키프레임(host, target)과 연결되어 최적화된다는 점이다. 여기서 host 키프레임은 해당 맵포인트를 가장 먼저 발견한 키프레임이고 target 키프레임은 이후에 발견한 키프레임을 의미한다.

또한 최적화 과정에서 연산량을 줄이기 위해 Jacobian을 계산할 때 카메라의 월드좌표계를 기준으로 계산한 Jacobian $\frac{\partial \mathbf{r}}{\partial \xi_{wh}},\frac{\partial \mathbf{r}}{\partial \xi_{wt}}$을 사용하지 않고 host, target 키프레임 간 상대 포즈를 기준으로 계산한 Jacobian $\frac{\partial \mathbf{r}}{\partial \xi_{th}}$를 사용한다. 따라서 해당 Jacobian을 사용하여 두 키프레임의 월드좌표계 기반 카메라 포즈 $\mathbf{T}_{wh}, \mathbf{T}_{wt}$를 최적화하기 위해 Adjoint Transformationd르 사용한다. (추후 섹션에서 설명)
sliding window optimization을 수행하기 위해 우선 에러함수를 설정해야 한다. 이 때, 에러함수의 파라미터는 pose(6) + photometric(2) + camera intrinsic(4) + idepth(N)로써 총 12+N개의 파라미터가 최적화에 사용된다. 참고로 Initialization 과정에서는 camera intrinsic(4)를 제외한 8+N개의 파라미터가 최적화되었다. 즉, camera intrinsic ($(f_{x}, f_{y}, c_{x}, c_{y})$)를 제외하고 Jacobian은 이전과 동일하다.

에러(residual)은 다음과 같이 설정할 수 있다.
$$\mathbf{r} = \mathbf{I}_{t}(\mathbf{p}_{t}) - \exp(a)( \mathbf{I}_{h}(\mathbf{p}_{h}) - b_{0}) - b$$
- $\mathbf{p}_{t} = \pi(\exp(\xi^{\wedge}_{th})\mathbf{X}_{1}) = \pi(\exp(\xi^{\wedge}_{th})\pi^{-1}(\mathbf{p}_{h}))$

이 때, residual은 한 점이 아닌 8-point patch 점들의 에러 합을 의미한다. 최종적으로 huber norm까지 적용된 에러함수는 다음과 같다.
$$\text{H}(\mathbf{r}) = w_{h}\mathbf{r}^{2}$$
해당 에러함수가 최소가 되는 파라미터를 찾기 위해 $f(\mathbf{x})^{T}f(\mathbf{x}) = \text{H}(\mathbf{r})$를 만족하는 $f(\mathbf{x})$를 최소화하는 문제로 변경하면 다음과 같다.
$$f(\mathbf{x}) = \sqrt{w_{h}} \ \mathbf{r} = \sqrt{w_{h}}(\mathbf{I}_{2}(\mathbf{p}_{2}) - \exp(a)(\mathbf{I}_{1}(\mathbf{p}_{1}-b_{0})) - b)$$
에러함수 $f(\mathbf{x})$에 state variable $\mathbf{x}$은 다음과 같다
$$f(\mathbf{x}) = \sqrt{w_{h}} \ \mathbf{r} = \sqrt{w_{h}}(\mathbf{I}_{t}(\mathbf{p}_{t}) - \exp(a)(\mathbf{I}_{h}(\mathbf{p}_{h}-b_{0})) - b)$$
$$\mathbf{x} = [ \ \rho^{(1)}_{1}, \cdots, \rho^{(N)}_{1}, \delta \xi^{T}, a, b, \mathbf{c} \ ]^{T}_{(N+12) \times 1}$$
- $\rho_{1}^{(i)}$ : 1번 이미지에서 i번째 inverse depth 값 (N개)
- $\delta \xi$ : 두 카메라 간 상대 포즈 변화량 (twist) (6차원 벡터) (6개)
- $a,b$ : 두 이미지 간 exposure time을 고려하여 이미지 밝기를 조절하는 파라미터 (2개)
- $\mathbf{c}$ : 카메라 내부 파라미터 (fx,fy,cx,cy) (4개)
Initialization 과정과 달리 에러함수 $\mathbf{x}$에 camera intrinsic $\mathbf{c}$가 포함된 것을 알 수 있다. Initialization 과정에서 이미 아래와 같이 최적화에 필요한 Jacobian들을 유도하였다.
idepth(N)
$$\frac{\partial f(\mathbf{x})}{\partial \rho_{1}} = \sqrt{w_{h}}\rho_{1}^{-1}\rho_{2}(\nabla \mathbf{I}_{x}f_{x}(t_{x}-u_{2}^{'}t_{z}) + \nabla \mathbf{I}_{y}f_{y}(t_{y} - v_{2}^{'}t_{z}))$$
pose(6)
$$\frac{\partial f(\mathbf{x})}{\partial \delta \xi} =\sqrt{w_{h}}
\begin{bmatrix}
\nabla \mathbf{I}_{x}\rho_{2}f_{x} \\
\nabla \mathbf{I}_{y}\rho_{2}f_{y} \\
-\rho_{2}(\nabla \mathbf{I}_{x}f_{x}u_{2}^{'} + \nabla \mathbf{I}_{y}f_{y}v_{2}^{'}) \\
-\nabla \mathbf{I}_{x}f_{x}u_{2}^{'}v_{2}^{'} -\nabla \mathbf{I}_{y}f_{y}(1+v_{2}^{'2}) \\
\nabla \mathbf{I}_{x}f_{x}(1+u_{2}^{'2}) + \nabla \mathbf{I}_{y}f_{y}u_{2}^{'}v_{2}^{'} \\
-\nabla \mathbf{I}_{x}f_{x}v_{2}^{'} + \nabla \mathbf{I}_{y}f_{y}u_{2}^{'}\\
\end{bmatrix}^{T}$$
photometric(2)
$$\frac{\partial f(\mathbf{x})}{\partial a} = - \sqrt{w_{h}} \exp(a)\mathbf{I}_{1}(\mathbf{p}_{1})$$
$$\frac{\partial f(\mathbf{x})}{\partial b} = - \sqrt{w_{h}}$$
하지만 sliding window optimization 과정에서는 추가적으로 Jacobian of Camera Intrinsic
$\frac{\partial f(\mathbf{x})}{\partial \mathbf{c}}$을 유도해야 한다.
4.3.2. Derivate Jacobian of Camera Intrinsics
$\frac{\partial f(\mathbf{x})}{\partial \mathbf{c}}$는 다음과 같이 분해할 수 있다.
$$\frac{\partial f(\mathbf{x})}{\partial \mathbf{c}}
=
\frac{\partial f(\mathbf{x})}{\partial \mathbf{p}_{t}}
\frac{\partial \mathbf{p}_{t}}{\partial \mathbf{c}}
$$
이 때, $f(\mathbf{x}) = \sqrt{w_{h}} \ \mathbf{r}$이므로 간결하게 residual 항으로 표현하면 다음과 같다.
$$\frac{\partial \mathbf{r}}{\partial \mathbf{c}}
=
\frac{\partial \mathbf{r}}{\partial \mathbf{p}_{t}}
\frac{\partial \mathbf{p}_{t}}{\partial \mathbf{c}}
$$
$\frac{\partial \mathbf{r}}{\partial \mathbf{p}_{t}}$는 Initialization 섹션에서 다음과 같이 이미 유도하였다.
$$\frac{\partial\mathbf{r}}{\partial \mathbf{p}_{t}} = \frac{\partial \mathbf{I_{t}}(\mathbf{p_{t}})}{\partial \mathbf{p}_{t}} = [ \ \nabla \mathbf{I}_{x} \ \ \nabla \mathbf{I}_{y} \ ]$$
그리고 $\frac{\partial \mathbf{p}_{t}}{\partial \mathbf{c}}$는 다음과 같이 유도할 수 있다.
\begin{equation*}
\begin{aligned}
\frac{\partial \mathbf{p}_{t}}{\partial \mathbf{c}}
&=
\begin{bmatrix}
\frac{\partial u_{t}}{\partial f_{x}} & \frac{\partial u_{t}}{\partial f_{y}}
& \frac{\partial u_{t}}{\partial c_{x}}
& \frac{\partial u_{t}}{\partial c_{y}}
\\
\frac{\partial v_{t}}{\partial f_{x}} & \frac{\partial v_{t}}{\partial f_{y}}
& \frac{\partial v_{t}}{\partial c_{x}}
& \frac{\partial v_{t}}{\partial c_{y}}
\end{bmatrix} \\
&=
\begin{bmatrix}
\bar{u}_{t} + f_{x}\frac{\partial \bar{u}_{t}}{\partial f_{x}}
& f_{x}\frac{\partial \bar{u}_{t}}{\partial f_{y}}
& f_{x}\frac{\partial \bar{u}_{t}}{\partial c_{x}} + 1
& f_{x}\frac{\partial \bar{u}_{t}}{\partial c_{y}}
\\
f_{y}\frac{\partial \bar{v}_{t}}{\partial f_{x}}
& \bar{v}_{t} + f_{y}\frac{\partial \bar{v}_{t}}{\partial f_{y}}
& f_{y}\frac{\partial \bar{v}_{t}}{\partial c_{x}}
& f_{y}\frac{\partial \bar{v}_{t}}{\partial c_{y}}+1
\end{bmatrix}
\end{aligned}
\end{equation*}
\begin{equation*}
\begin{aligned}
\because
u_{t} = f_{x}\bar{u}_{t} + c_{x} \\
v_{t} = f_{y}\bar{v}_{t} + c_{y}
\end{aligned}
\end{equation*}
다음 순서로 \begin{equation*}
\begin{aligned}
\begin{bmatrix}
\frac{\partial \bar{u}_{t}}{\partial f_{x}} & \frac{\partial \bar{u}_{t}}{\partial f_{y}}
& \frac{\partial \bar{u}_{t}}{\partial c_{x}}
& \frac{\partial \bar{u}_{t}}{\partial c_{y}} \\
\frac{\partial \bar{v}_{t}}{\partial f_{x}} & \frac{\partial \bar{v}_{t}}{\partial f_{y}}
& \frac{\partial \bar{v}_{t}}{\partial c_{x}}
& \frac{\partial \bar{v}_{t}}{\partial c_{y}}
\end{bmatrix}
\end{aligned}
\end{equation*} 값을 구해야 한다. 우선 \begin{equation*}
\begin{aligned}
\begin{bmatrix}
\bar{u}_{t} & \bar{v}_{t} & 1 \end{bmatrix}
\end{aligned}
\end{equation*}를 전개하면 다음과 같다.
\begin{equation*}
\begin{aligned}
\begin{bmatrix}
\bar{u}_{t} & \bar{v}_{t} & 1 \end{bmatrix}^{T}
&=
\rho_{t}(\mathbf{R}\mathbf{X}_{1} + \mathbf{t})\\
&=
\rho_{t}(\rho_{h}^{-1}\mathbf{R}\mathbf{K}^{-1}\mathbf{p}_{h} + \mathbf{t}) \\
&=
\rho_{t}\rho_{h}^{-1}(\mathbf{R}\mathbf{K}^{-1}\mathbf{p}_{h}) + \rho_{t}\mathbf{t} \\
&=
\rho_{t}\rho_{h}^{-1}
\begin{bmatrix}
& & \\
& \mathbf{R} & \\
& &
\end{bmatrix}
\begin{bmatrix}
f_{x}^{-1}& & -f_{x}^{-1}c_{x}\\
& f_{y}^{-1} & -f_{y}^{-1}c_{y} \\
& & 1
\end{bmatrix}
\begin{bmatrix}
u_{h} \\ v_{h} \\ 1
\end{bmatrix}
+
\rho_{t}
\begin{bmatrix}
t_{x} \\ t_{y} \\ t_{z}
\end{bmatrix} \\
&=
\rho_{t}\rho_{h}^{-1}
\begin{bmatrix}
& & \\
& \mathbf{R} & \\
& &
\end{bmatrix}
\begin{bmatrix}
f_{x}^{-1}(u_{h}-c_{x}) \\
f_{y}^{-1}(v_{h}-c_{y}) \\
1
\end{bmatrix}
+
\rho_{t}
\begin{bmatrix}
t_{x} \\ t_{y} \\ t_{z}
\end{bmatrix} \\
&=
\rho_{t}\rho_{h}^{-1}
\begin{bmatrix}
r_{11}f_{x}^{-1}(u_{h}-c_{x}) + r_{12}f_{y}^{-1}(v_{h}-c_{y}) + r_{13} \\
r_{21}f_{x}^{-1}(u_{h}-c_{x}) + r_{22}f_{y}^{-1}(v_{h}-c_{y}) + r_{23} \\
r_{31}f_{x}^{-1}(u_{h}-c_{x}) + r_{32}f_{y}^{-1}(v_{h}-c_{y}) + r_{33}
\end{bmatrix}
+
\rho_{t}
\begin{bmatrix}
t_{x} \\ t_{y} \\ t_{z}
\end{bmatrix} \\
\end{aligned}
\end{equation*}
따라서 $\bar{u}_{t}, \bar{v}_{t}$는 다음과 같이 나타낼 수 있다.
$$\therefore
\bar{u}_{t} = \frac
{r_{11}f_{x}^{-1}(u_{h}-c_{x}) + r_{12}f_{y}^{-1}(v_{h}-c_{y}) + r_{13} + \rho_{h}t_{x}}
{r_{31}f_{x}^{-1}(u_{h}-c_{x}) + r_{32}f_{y}^{-1}(v_{h}-c_{y}) + r_{33} + \rho_{h}t_{z}}
$$
$$
\bar{v}_{t} = \frac
{r_{21}f_{x}^{-1}(u_{h}-c_{x}) + r_{22}f_{y}^{-1}(v_{h}-c_{y}) + r_{23} + \rho_{h}t_{y}}
{r_{31}f_{x}^{-1}(u_{h}-c_{x}) + r_{32}f_{y}^{-1}(v_{h}-c_{y}) + r_{33} + \rho_{h}t_{z}}
$$
위 식을 사용하여 \begin{equation*}
\begin{aligned}
\begin{bmatrix}
\frac{\partial \bar{u}_{t}}{\partial f_{x}} & \frac{\partial \bar{u}_{t}}{\partial f_{y}}
& \frac{\partial \bar{u}_{t}}{\partial c_{x}}
& \frac{\partial \bar{u}_{t}}{\partial c_{y}} \\
\frac{\partial \bar{v}_{t}}{\partial f_{x}} & \frac{\partial \bar{v}_{t}}{\partial f_{y}}
& \frac{\partial \bar{v}_{t}}{\partial c_{x}}
& \frac{\partial \bar{v}_{t}}{\partial c_{y}}
\end{bmatrix}
\end{aligned}
\end{equation*}를 구해보면 다음과 같다.
$$\frac{\partial \bar{u}_{t}}{\partial f_{x}} = \rho_{t}\rho_{h}^{-1}(r_{31}\bar{u}_{t} - r_{11})f_{x}^{-2}(u_{h}-c_{x})$$
$$\frac{\partial \bar{u}_{t}}{\partial f_{y}} = \rho_{t}\rho_{h}^{-1}(r_{32}\bar{u}_{t} - r_{12})f_{y}^{-2}(v_{h}-c_{y})$$
$$\frac{\partial \bar{u}_{t}}{\partial c_{x}} = \rho_{t}\rho_{h}^{-1}(r_{31}\bar{u}_{t} - r_{11})f_{x}^{-1}$$
$$\frac{\partial \bar{u}_{t}}{\partial c_{y}} = \rho_{t}\rho_{h}^{-1}(r_{32}\bar{u}_{t} - r_{12})f_{y}^{-1}$$
$$\frac{\partial \bar{v}_{t}}{\partial f_{x}} = \rho_{t}\rho_{h}^{-1}(r_{31}\bar{v}_{t} - r_{21})f_{x}^{-2}(u_{h}-c_{x})$$
$$\frac{\partial \bar{v}_{t}}{\partial f_{y}} = \rho_{t}\rho_{h}^{-1}(r_{32}\bar{v}_{t} - r_{22})f_{y}^{-2}(v_{h}-c_{y})$$
$$\frac{\partial \bar{v}_{t}}{\partial c_{x}} = \rho_{t}\rho_{h}^{-1}(r_{31}\bar{v}_{t} - r_{21})f_{x}^{-1}$$
$$\frac{\partial \bar{u}_{t}}{\partial c_{y}} = \rho_{t}\rho_{h}^{-1}(r_{32}\bar{v}_{t} - r_{22})f_{y}^{-1}$$
최종적으로 $\frac{\partial \mathbf{p}_{t}}{\partial \mathbf{c}}$는 다음과 같이 나타낼 수 있다.
Camera Intrinsic(4)
\begin{equation*}
\begin{aligned}
\frac{\partial \mathbf{p}_{t}}{\partial \mathbf{c}}
&=
\begin{bmatrix}
\frac{\partial u_{t}}{\partial f_{x}} & \frac{\partial u_{t}}{\partial f_{y}}
& \frac{\partial u_{t}}{\partial c_{x}}
& \frac{\partial u_{t}}{\partial c_{y}}
\\
\frac{\partial v_{t}}{\partial f_{x}} & \frac{\partial v_{t}}{\partial f_{y}}
& \frac{\partial v_{t}}{\partial c_{x}}
& \frac{\partial v_{t}}{\partial c_{y}}
\end{bmatrix} \\
&=
\begin{bmatrix}
\bar{u}_{t} + f_{x}\frac{\partial \bar{u}_{t}}{\partial f_{x}}
& f_{x}\frac{\partial \bar{u}_{t}}{\partial f_{y}}
& f_{x}\frac{\partial \bar{u}_{t}}{\partial c_{x}} + 1
& f_{x}\frac{\partial \bar{u}_{t}}{\partial c_{y}}
\\
f_{y}\frac{\partial \bar{v}_{t}}{\partial f_{x}}
& \bar{v}_{t} + f_{y}\frac{\partial \bar{v}_{t}}{\partial f_{y}}
& f_{y}\frac{\partial \bar{v}_{t}}{\partial c_{x}}
& f_{y}\frac{\partial \bar{v}_{t}}{\partial c_{y}}+1
\end{bmatrix} \\
&=
\begin{bmatrix}
\bar{u}_{t} + \rho_{t}\rho_{h}^{-1}f_{x}^{-1}(r_{31}\bar{u}_{t} - r_{11})(u_{h}-c_{x})&
\rho_{t}\rho_{h}^{-1}f_{x}f_{y}^{-2}(r_{32}\bar{u}_{t} - r_{12})(v_{h}-c_{y})&
\rho_{t}\rho_{h}^{-1}(r_{31}\bar{u}_{t} - r_{11}) + 1&
\rho_{t}\rho_{h}^{-1}f_{x}f_{y}^{-1}(r_{32}\bar{u}_{t} - r_{12})
\\
\rho_{t}\rho_{h}^{-1}f_{x}^{-2}f_{y}(r_{31}\bar{v}_{t} - r_{21})(u_{h}-c_{x})&
\bar{v}_{t} + \rho_{t}\rho_{h}^{-1}f_{y}^{-1}(r_{32}\bar{v}_{t} - r_{22})(v_{h}-c_{y})&
\rho_{t}\rho_{h}^{-1}f_{x}^{-1}f_{y}(r_{31}\bar{v}_{t} - r_{21})&
\rho_{t}\rho_{h}^{-1}(r_{32}\bar{u}_{t} - r_{12}) + 1
\end{bmatrix}
\end{aligned}
\end{equation*}
4.3.3. First Estimate Jacobian (FEJ)
sliding window optimization을 수행하면 매 iteration 마다 state variable $\mathbf{x}$가 업데이트된다. 이 때, $\boxplus$ 연산자는 N+12개 상태를 각각 파라미터 별로 업데이트해주는 연산자이다.
$$\mathbf{x} \leftarrow \Delta \mathbf{x} \boxplus \mathbf{x}$$
- $\mathbf{x} = [ \ \rho^{(1)}_{1}, \cdots, \rho^{(N)}_{1}, \delta \xi^{T}, a, b, \mathbf{c} \ ]^{T}_{(N+12) \times 1}$
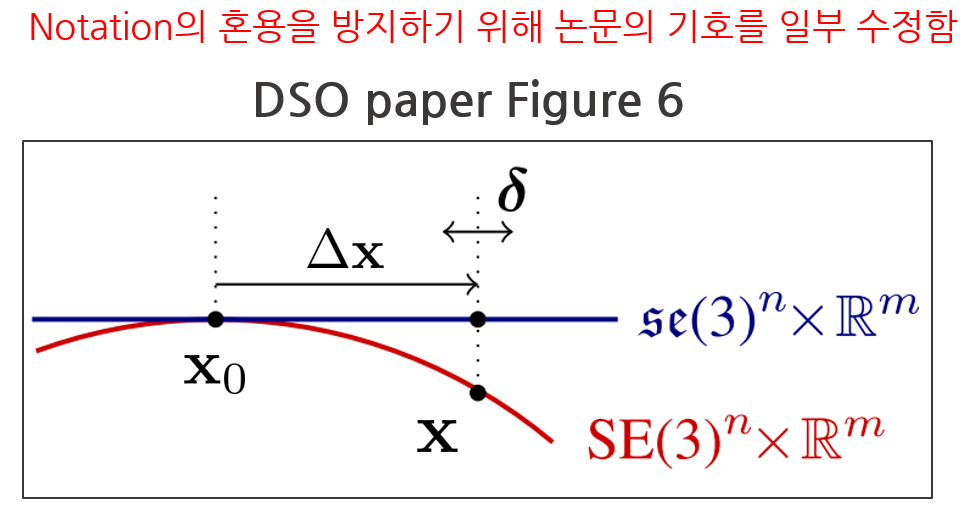
- $\mathbf{x}_{0}$ : LBA를 시작하는 시점에서 state variable
- $\mathbf{x}$ : LBA가 끝난 후 state variable
- $\Delta \mathbf{x}$ : 매 iteration 업데이트(marginalization 포함)로 인한 누적 증분량
- $\delta$ : 매 iteration 업데이트 증분량
DSO에서는 LBA를 수행할 때마다 6번의 최적화를 수행하는데 만약 매 iteration마다 Jacobian을 새로 계산하면 다음과 같은 단점이 존재한다. (자세한 내용은 https://blog.csdn.net/heyijia0327/article/details/53707261 참조)
1. 연산량이 매우 증가하므로 실시간 성능을 보장할 수 없다.
2. 서로 다른 state의 Jacobian을 한 시스템에서 같이 사용하는 경우 성능의 저하를 일으킬 가능성이 존재한다.
따라서 LBA를 수행할 때 매 iteration마다(marginalization 포함) 업데이트로 인해 state variable $\mathbf{x}$가 변하더라도 Jacobian은 새로 계산하지 않고 LBA를 시작하는 시점 ($\mathbf{x}_{0}$)에서 계산한 Jacobian을 사용하여 업데이트하는 방법을 First Estimate Jacobian (FEJ)라고 한다. FEJ의 적용 순서는 다음과 같다.
1. LBA를 시작하기 전에 현재 $\mathbf{x}$를 $\mathbf{x}_{0}$에 저장한 후 Jacobian을 계산한다.
$$\mathbf{x}_{0} \leftarrow \mathbf{x}, \text{ compute } \mathbf{J}|_{\mathbf{x}_{0}}$$
2. LBA를 수행하면서 매 iteration마다 업데이트 값을 누적시킨다.
$$\Delta \mathbf{x}\leftarrow\Delta \mathbf{x}+\delta$$
3. 매 iteration동안 Jacobian은 $\mathbf{x}_{0}$에서 계산한값을 사용한다.
4. LBA iteration이 끝난 경우 현재 상태에서 누적된 증분량을 업데이트한다.
$$\mathbf{x} \leftarrow \Delta \mathbf{x} \boxplus \mathbf{x}_{0}$$
4.3.4. Adjoint Transformation
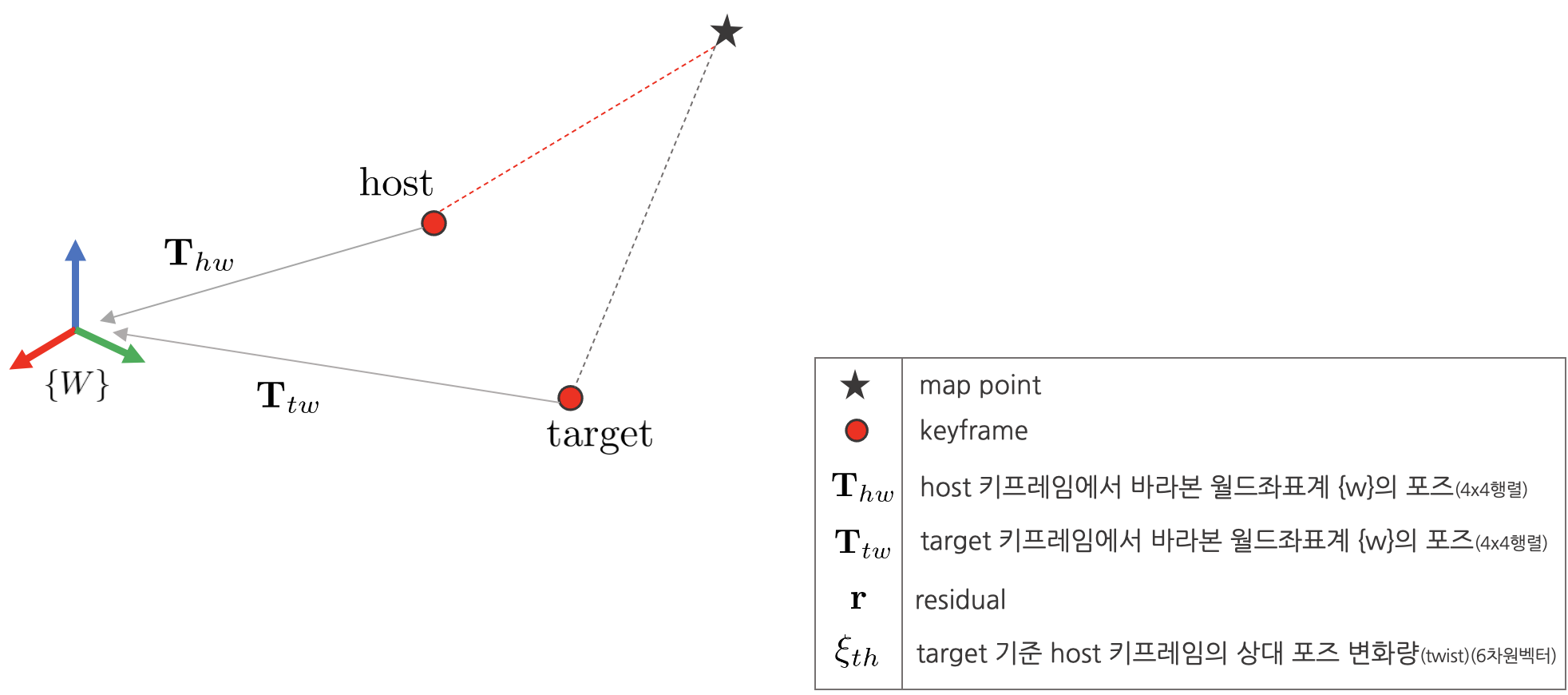
앞서 설명한 것과 같이 DSO에서는 하나의 맵포인트에 2개의 키프레임(host, target)이 연결되어 있다. 이에 따라 최적화 수행 시 연산량을 줄이기 위해 target, host 키프레임 사이의 상대 포즈를 기반으로 계산한 Jacobian $\frac{\partial \mathbf{r}}{\partial \xi_{th}}$를 사용한다. 하지만 해당 Jacobian을 사용하여 iterative solution을 구하게 되면 두 host, target 키프레임 사이의 상대포즈만 최적화되므로 월드좌표계 $\{W\}$를 기준으로 한 카메라 포즈는 계산할 수 없다. 이 때, DSO에서는 Adjoint Transformation을 통해 $\frac{\partial \mathbf{r}}{\partial \xi_{hw}},\frac{\partial \mathbf{r}}{\partial \xi_{tw}}$를 계산하여 월드좌표계와 카메라 포즈를 최적화하였다. (자세한 내용은
https://www.cnblogs.com/JingeTU/p/8306727.html 참조)
(+23.11.6 SLAMUS님의 수식 오류 지적으로 내용을 수정하였습니다. $\xi_{h} \rightarrow \xi_{hw}, \xi_{t} \rightarrow \xi_{tw}$)
- $\mathbf{r}$ : residual
- $\xi_{th}$ : target 기준 host 키프레임의 상대 포즈 변화량 (twist) (6차원 벡터)
- $\xi_{hw}$ : 월드좌표계 기준 host 키프레임의 상대 포즈 변화량
- $\xi_{tw}$ : 월드좌표계 기준 target 키프레임의 상대 포즈 변화량
$\frac{\partial \mathbf{r}}{\partial \xi_{th}}$을 $\frac{\partial \mathbf{r}}{\partial \xi_{hw}},\frac{\partial \mathbf{r}}{\partial \xi_{tw}}$로 변환하기 위해 다음과 같은 연산을 사용한다.
host
\begin{equation*}
\begin{aligned}
\frac{\partial \mathbf{r}}{\partial \xi_{hw}}^{T}
\frac{\partial \mathbf{r}}{\partial \xi_{hw}}
&=
\bigg(\frac{\partial \mathbf{r}}{\partial \xi_{th}}
\frac{\partial \xi_{th}}{\partial \xi_{hw}}\bigg)^{T}
\bigg(\frac{\partial \mathbf{r}}{\partial \xi_{th}}
\frac{\partial \xi_{th}}{\partial \xi_{hw}}\bigg) \\
&=
\bigg(\frac{\partial \xi_{th}}{\partial \xi_{hw}}\bigg)^{T}
\bigg(\frac{\partial \mathbf{r}}{\partial \xi_{th}}\bigg)^{T}
\bigg(\frac{\partial \mathbf{r}}{\partial \xi_{th}}\bigg)
\bigg(\frac{\partial \xi_{th}}{\partial \xi_{hw}}\bigg)
\end{aligned}
\end{equation*}
target
\begin{equation*}
\begin{aligned}
\frac{\partial \mathbf{r}}{\partial \xi_{tw}}^{T}
\frac{\partial \mathbf{r}}{\partial \xi_{tw}}
&=
\bigg(\frac{\partial \mathbf{r}}{\partial \xi_{th}}
\frac{\partial \xi_{th}}{\partial \xi_{tw}}\bigg)^{T}
\bigg(\frac{\partial \mathbf{r}}{\partial \xi_{th}}
\frac{\partial \xi_{th}}{\partial \xi_{tw}}\bigg) \\
&=
\bigg(\frac{\partial \xi_{th}}{\partial \xi_{tw}}\bigg)^{T}
\bigg(\frac{\partial \mathbf{r}}{\partial \xi_{th}}\bigg)^{T}
\bigg(\frac{\partial \mathbf{r}}{\partial \xi_{th}}\bigg)
\bigg(\frac{\partial \xi_{th}}{\partial \xi_{tw}}\bigg)
\end{aligned}
\end{equation*}
이 때, twist의 변화량은 다음과 같이 계산할 수 있다.
$$\frac{\partial \xi_{th}}{\partial \xi_{hw}} = -\text{Ad}_{\mathbf{T}_{th}}$$
$$\frac{\partial \xi_{th}}{\partial \xi_{tw}} = \mathbf{I}$$
여기서 $\text{Ad}_{\mathbf{T}_{th}}$를 Adjoint Transformation of SE(3) Group이라고 한다. 해당 변환이 하는 역할은 3차원 공간 상에서 특정 좌표계에서 바라본 twist를 다른 좌표계에서 바라본 twist로 변환하는 역할을 한다.
$$\xi_{tw} = \text{Ad}_{\mathbf{T}_{th}} \cdot \xi_{hw}$$
구체적으로 $\text{Ad}_{\mathbf{T}_{th}}$는 host 키프레임에서 바라본 특정 twist를 target 키프레임에서 바라본 twist로 변환하는 연산자이다. 하지만 해당 공식에서 사용하는 $\text{Ad}_{\mathbf{T}_{th}}$는 $\frac{\partial \xi_{th}}{\partial \xi_{hw}}$ 값으로 유도되었기 때문에 물리적인 의미는 갖지 않고 $\frac{\partial \mathbf{r}}{\partial \xi_{hw}}$를 계산하기 위한 도구로만 사용된다.
$\text{Ad}_{\mathbf{T}_{th}}$의 자세한 정의 및 역할에 대해 알고 싶으면 링크(http://ethaneade.com/lie.pdf)를 참조하면 된다.
$$\exp(\text{Ad}_{\mathbf{T}_{th}} \cdot \xi_{hw}^{\wedge}) = \mathbf{T}_{th}\exp(\xi_{hw}^{\wedge})\mathbf{T}_{th}^{-1}$$
다음으로 $\frac{\partial \xi_{th}}{\partial \xi_{hw}}$, $\frac{\partial \xi_{th}}{\partial \xi_{tw}}$ 값의 유도 과정에 대해 설명한다. 우선 $\mathbf{T}_{th} = \mathbf{T}_{tw}\mathbf{T}_{hw}^{-1}$와 같이 2개의 포즈로 분할할 수 있고 이를 iterative 업데이트 공식으로 확장하면 다음과 같다.
derivative of host
$$\exp(\xi_{th}^{\wedge} + \delta \xi_{th}^{\wedge})\mathbf{T}_{th}
=
\mathbf{T}_{tw}(\exp(\xi_{hw}^{\wedge} + \delta \xi_{hw}^{\wedge})\mathbf{T}_{hw})^{-1}$$
\begin{equation*}
\begin{aligned}
\exp(\xi_{th}^{\wedge} + \delta \xi_{th}^{\wedge})
&=
\mathbf{T}_{tw}\mathbf{T}_{hw}^{-1}\exp(-(\xi_{hw}^{\wedge} + \delta \xi_{hw}^{\wedge}))\mathbf{T}_{th}^{-1} \\
&=
\mathbf{T}_{th} \exp(-(\xi_{hw}^{\wedge}+\delta \xi_{hw}^{\wedge})) \mathbf{T}_{th}^{-1} \\
&=
\exp(-\text{Ad}_{\mathbf{T}_{th}}(\xi_{hw}^{\wedge} + \delta\xi_{hw}^{\wedge}))
\end{aligned}
\end{equation*}
$$\therefore
\exp(\xi_{th}^{\wedge} + \delta \xi_{th}^{\wedge})
=
\exp(-\text{Ad}_{\mathbf{T}_{th}}(\xi_{hw}^{\wedge} + \delta\xi_{hw}^{\wedge}))$$
$$\therefore \frac{\partial \xi_{th}}{\partial \xi_{hw}} = -\text{Ad}_{\mathbf{T}_{th}}$$
derivative of target
$$\exp(\xi_{th}^{\wedge} + \delta \xi_{th}^{\wedge})\mathbf{T}_{th}
=
\exp(\xi_{tw}^{\wedge} + \delta \xi_{tw}^{\wedge})\mathbf{T}_{tw}\mathbf{T}_{hw}^{-1}$$
\begin{equation*}
\begin{aligned}
\exp(\xi_{th}^{\wedge} + \delta \xi_{th}^{\wedge})
&=
\exp(\xi_{tw}^{\wedge} + \delta \xi_{tw}^{\wedge})\mathbf{T}_{tw}\mathbf{T}_{hw}^{-1}\mathbf{T}_{th}^{-1} \\
&=
\exp(\xi_{tw}^{\wedge} + \delta \xi_{tw}^{\wedge})
\end{aligned}
\end{equation*}
$$\therefore \exp(\xi_{th}^{\wedge} + \delta \xi_{th}^{\wedge}) = \exp(\xi_{tw}^{\wedge} + \delta \xi_{tw}^{\wedge})$$
$$\therefore \frac{\partial \xi_{th}}{\partial \xi_{tw}} = \mathbf{I}$$
4.3.5. Marginalization
To be added
4.3.6. Solving the Incremental Equation
DSO에서는 sliding window 내부에 항상 8개의 키프레임을 유지하면서 12+N개의 파라미터를 최적화한다. (Pose(6) + Photometric(2) + Camera Intrinsics(4) + Idepth(N)). 이렇게 특정 윈도우 내의 키프레임 포즈와 맵포인트를 동시에 최적화하는 방법을 Local Bundle Adjustment (LBA)라고 한다. 이전 섹션에서 유도한 LBA의 에러함수는 다음과 같고 이 때, state variable $\mathbf{x}$는 다음과 같다. 수식을 간결하게 나타내기 위해 idepth를 제외한 나머지 파라미터를 $\mathbf{y} = [ \ \delta \xi^{T} \ a \ b \ \mathbf{c} \ ]$로 축약하였다.
$$f(\mathbf{x}) = \sqrt{w_{h}} \ \mathbf{r}$$
- \begin{equation*}
\begin{aligned}
\mathbf{x}
&=
\begin{bmatrix}
\rho^{(1)}_{1} & \cdots & \rho^{(N)}_{1} & \delta \xi^{T} & a & b & \mathbf{c}
\end{bmatrix}^{T}_{(N+12) \times 1} \\
&=
\begin{bmatrix}
\rho^{(1)}_{1} & \cdots & \rho^{(N)}_{1} & \mathbf{y}
\end{bmatrix}^{T}_{(N+12) \times 1}
\end{aligned}
\end{equation*}
- $\rho_{1}^{(i)}$ : 1번 이미지에서 i번째 inverse depth 값 (N개)
- $\delta \xi$ : 두 카메라 간 상대 포즈 변화량 (twist) (6차원 벡터) (6개)
- $a,b$ : 두 이미지 간 exposure time을 고려하여 이미지 밝기를 조절하는 파라미터 (2개)
- $\mathbf{c}$ : 카메라 내부 파라미터 (fx,fy,cx,cy) (4개)
해당 에러함수를 이용해 least squares optimization 형태로 나타내면 최종적으로 다음과 같은 형태의 식이 유도된다. 해당 식의 유도는 Initialization 챕터에서 다뤘기 때문에 생략한다.
$$\mathbf{H}\Delta \mathbf{x} = -\mathbf{b} \rightarrow \begin{bmatrix}
\mathbf{H}_{\rho\rho} & \mathbf{H}_{\rho\mathbf{y}} \\
\mathbf{H}_{\mathbf{y}\rho} & \mathbf{H}_{\mathbf{y}\mathbf{y}}
\end{bmatrix}
\begin{bmatrix}
\Delta \mathbf{x}_{\rho} \\
\Delta \mathbf{x}_{\mathbf{y}}
\end{bmatrix}
=
\begin{bmatrix}
-\mathbf{b}_{\rho} \\
-\mathbf{b}_{\mathbf{y}}
\end{bmatrix}
$$
- $\mathbf{y} = [ \ \delta \xi^{T} \ a \ b \ \mathbf{c} \ ]$
이 때, Hessian Matrix $\mathbf{H}$를 자세하게 펼쳐보면 다음과 같다.
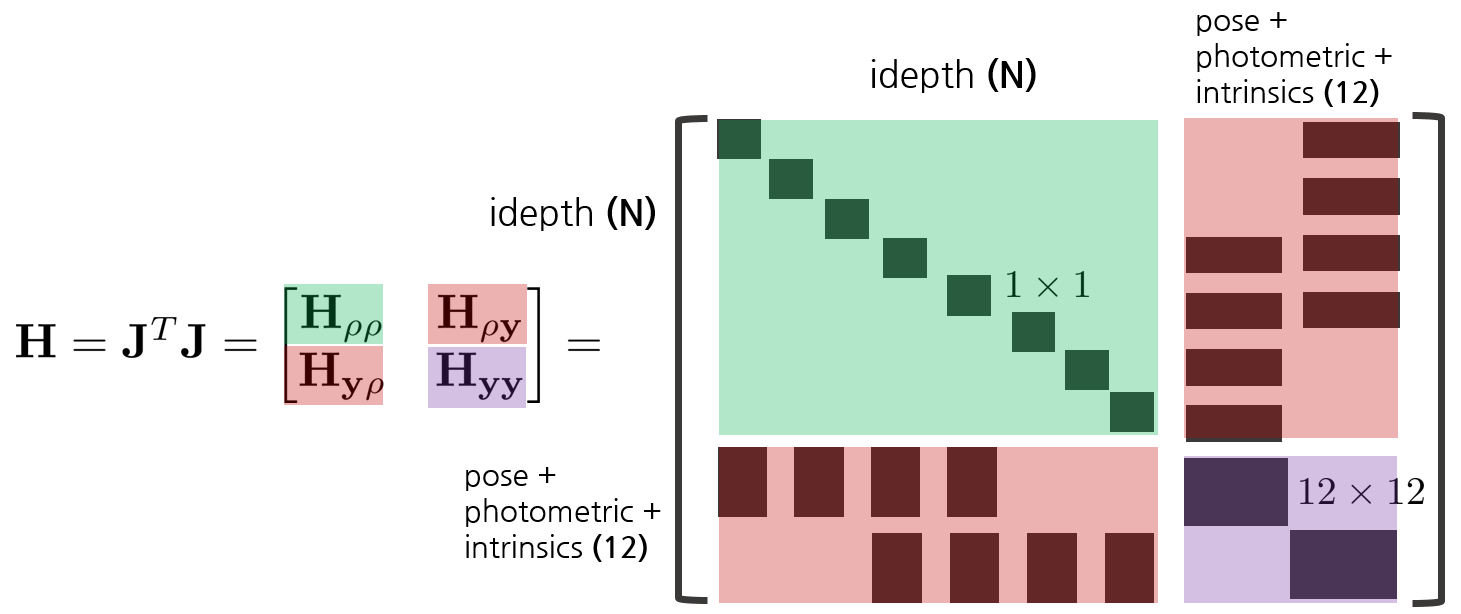
Schur Complement 섹션에서 설명한 것처럼 $\mathbf{H}^{-1}$을 계산하는데 매우 많은 시간이 소모되므로 이를 Schur Complement를 사용해서 $\Delta \mathbf{x}_{\mathbf{y}}$, $\Delta \mathbf{x}_{\mathbf{\rho}}$ 순서대로 계산한다.
Details of H and b matrix
$\mathbf{H}, \mathbf{b}$ 행렬에 대해 자세하게 전개하면 다음과 같다. 이는 DSO 코드를 보면서 공식과 매칭할 때 어떤 H, b 행렬의 값을 다루고 있는지 확인할 때 참고하면 좋을 것 같다.
$$
\begin{bmatrix}
\mathbf{H}_{\rho\rho} & \mathbf{H}_{\rho\mathbf{y}} \\
\mathbf{H}_{\mathbf{y}\rho} & \mathbf{H}_{\mathbf{y}\mathbf{y}}
\end{bmatrix}
=
\begin{bmatrix}
\mathbf{J}_{\rho}^{T}\mathbf{J}_{\rho} & \mathbf{J}_{\rho}^{T}\mathbf{J}_\mathbf{y} \\
\mathbf{J}_{\mathbf{y}}^{T}\mathbf{J}_{\rho} & \mathbf{J}_{\mathbf{y}}^{T}\mathbf{J}_{\mathbf{y}}
\end{bmatrix}
$$
H_yy
$$
\mathbf{H}_{\mathbf{y}\mathbf{y}}
=
\mathbf{J}_{\mathbf{y}}^{T}\mathbf{J}_{\mathbf{y}}
=
\begin{bmatrix}
\mathbf{J}_{\mathbf{c}}^{T}\mathbf{J}_{\mathbf{c}} & \mathbf{J}_{\mathbf{c}}^{T}\mathbf{J}_{\xi'} \\
\mathbf{J}_{\xi'}^{T}\mathbf{J}_{\mathbf{c}} & \mathbf{J}_{\xi'}^{T}\mathbf{J}_{\xi'} \\
\end{bmatrix}
$$
- $\xi' = [ \ \delta \xi \ a \ b \ ]_{8\times1}$
$$
\mathbf{J}_{\mathbf{c}}^{T}\mathbf{J}_{\mathbf{c}}
=
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \mathbf{c}}^{T} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \mathbf{c}}^{T}
\end{bmatrix}
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \mathbf{c}}
\\
\vdots
\\
\frac{\partial \mathbf{r}^{(N)}}{\partial \mathbf{c}}
\end{bmatrix}
=
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \mathbf{c}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \mathbf{c}}
$$
$$
\mathbf{J}_{\mathbf{c}}^{T}\mathbf{J}_{\xi'}
=
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \mathbf{c}}^{T} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \mathbf{c}}^{T}
\end{bmatrix}
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \xi_{1}} & \cdots & \frac{\partial \mathbf{r}^{(1)}}{\partial \xi_{8}}
\\
\vdots & \ddots & \vdots
\\
\frac{\partial \mathbf{r}^{(N)}}{\partial \xi_{1}} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \xi_{8}}
\end{bmatrix}
=
\begin{bmatrix}
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \mathbf{c}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{1}} & \cdots & \sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \mathbf{c}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{8}}
\end{bmatrix}
$$
$$
\mathbf{J}_{\xi'}^{T}\mathbf{J}_{\xi'}
=
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \xi_{1}} & \cdots & \frac{\partial \mathbf{r}^{(1)}}{\partial \xi_{8}}
\\
\vdots & \ddots & \vdots
\\
\frac{\partial \mathbf{r}^{(N)}}{\partial \xi_{1}} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \xi_{8}}
\end{bmatrix}^{T}
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \xi_{1}} & \cdots & \frac{\partial \mathbf{r}^{(1)}}{\partial \xi_{8}}
\\
\vdots & \ddots & \vdots
\\
\frac{\partial \mathbf{r}^{(N)}}{\partial \xi_{1}} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \xi_{8}}
\end{bmatrix}
=
\begin{bmatrix}
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{1}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{1}} & \cdots & \sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{1}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{8}}
\\
\vdots & \ddots & \vdots
\\
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{8}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{1}} & \cdots & \sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{8}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{8}}
\end{bmatrix}
$$
H_rho_rho, H_rho_y, H_y_rho
$$
\mathbf{J}_{\rho}^{T}\mathbf{J}_{\rho}
=
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \rho^{(1)}} & \cdots & \frac{\partial \mathbf{r}^{(1)}}{\partial \rho^{(M)}}
\\
\vdots & \ddots & \vdots
\\
\frac{\partial \mathbf{r}^{(N)}}{\partial \rho^{(1)}} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \rho^{(M)}}
\end{bmatrix}^{T}
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \rho^{(1)}} & \cdots & \frac{\partial \mathbf{r}^{(1)}}{\partial \rho^{(M)}}
\\
\vdots & \ddots & \vdots
\\
\frac{\partial \mathbf{r}^{(N)}}{\partial \rho^{(1)}} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \rho^{(M)}}
\end{bmatrix}
=
\begin{bmatrix}
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(1)}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(1)}} & 0 & \cdots & 0
\\
0 & \sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(2)}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(2)}} & \cdots & 0
\\
\vdots & \vdots & \ddots & 0
\\
0 & 0& \cdots & \sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(M)}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(M)}}
\end{bmatrix}
$$
$$\mathbf{J}_{\mathbf{y}}^{T}\mathbf{J}_{\rho}
=
\begin{bmatrix}
\mathbf{J}_{\mathbf{c}}^{T} & \mathbf{J}_{\xi'}^{T}
\end{bmatrix}^{T}
\mathbf{J}_{\rho}
=
\begin{bmatrix}
\mathbf{J}_{\mathbf{c}}^{T}\mathbf{J}_{\rho} & \mathbf{J}_{\xi'}^{T}\mathbf{J}_{\rho}
\end{bmatrix}^{T}
$$
$$
\mathbf{J}_{\mathbf{c}}^{T}\mathbf{J}_{\rho}
=
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \mathbf{c}}^{T} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \mathbf{c}}^{T}
\end{bmatrix}
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \rho^{(1)}} & \cdots & \frac{\partial \mathbf{r}^{(1)}}{\partial \rho^{(M)}}
\\
\vdots & \ddots & \vdots
\\
\frac{\partial \mathbf{r}^{(N)}}{\partial \rho^{(1)}} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \rho^{(M)}}
\end{bmatrix}
=
\begin{bmatrix}
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \mathbf{c}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(1)}} & \cdots & \sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \mathbf{c}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(M)}}
\end{bmatrix}
$$
$$
\mathbf{J}_{\xi'}^{T}\mathbf{J}_{\rho}
=
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \xi_{1}} & \cdots & \frac{\partial \mathbf{r}^{(1)}}{\partial \xi_{8}}
\\
\vdots & \ddots & \vdots
\\
\frac{\partial \mathbf{r}^{(N)}}{\partial \xi_{1}} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \xi_{8}}
\end{bmatrix}^{T}\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \rho^{(1)}} & \cdots & \frac{\partial \mathbf{r}^{(1)}}{\partial \rho^{(M)}}
\\
\vdots & \ddots & \vdots
\\
\frac{\partial \mathbf{r}^{(N)}}{\partial \rho^{(1)}} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \rho^{(M)}}
\end{bmatrix}
=
\begin{bmatrix}
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{1}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(1)}} & \cdots & \sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{1}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(M)}}
\\
\vdots & \ddots & \vdots
\\
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{8}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(1)}} & \cdots & \sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{8}}^{T}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(M)}}
\end{bmatrix}
$$
$f(\mathbf{x}) = \sqrt{w_{h}}\mathbf{r}$ 이므로 huber norm을 생략하고 residual만 표현하면
$$\begin{bmatrix}
\mathbf{b}_{\rho} \\
\mathbf{b}_{\mathbf{y}}
\end{bmatrix}\rightarrow\begin{bmatrix}
\mathbf{J}_{\rho}^{T}f(\mathbf{x}) \\
\mathbf{J}_{\mathbf{y}}^{T}f(\mathbf{x})
\end{bmatrix}\rightarrow\sqrt{w_{h}} \begin{bmatrix}
\mathbf{J}_{\rho}^{T}\mathbf{r} \\
\mathbf{J}_{\mathbf{y}}^{T}\mathbf{r}
\end{bmatrix}$$
이 된다. 이를 자세하게 전개하면 다음과 같다.
$$
\mathbf{J}_{\rho}^{T}\mathbf{r}
=
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \rho^{(1)}} & \cdots & \frac{\partial \mathbf{r}^{(1)}}{\partial \rho^{(M)}}
\\
\vdots & \ddots & \vdots
\\
\frac{\partial \mathbf{r}^{(N)}}{\partial \rho^{(1)}} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \rho^{(M)}}
\end{bmatrix}^{T}
\begin{bmatrix}
\mathbf{r}^{(1)}
\\
\vdots
\\
\mathbf{r}^{(N)}
\end{bmatrix}
=
\begin{bmatrix}
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(1)}}^{T}\mathbf{r}^{(i)}
\\
\vdots
\\
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \rho^{(M)}}^{T}\mathbf{r}^{(i)}
\end{bmatrix}
$$
$$\mathbf{J}_{\mathbf{y}}^{T}\mathbf{r}
=
\begin{bmatrix}
\mathbf{J}_{\mathbf{c}}^{T}
\\
\mathbf{J}_{\xi'}^{T}
\end{bmatrix}
\mathbf{r}
=
\begin{bmatrix}
\frac{\partial \mathbf{r}^{(1)}}{\partial \mathbf{c}}^{T} & \cdots & \frac{\partial \mathbf{r}^{(1)}}{\partial \mathbf{c}}^{T}
\\
\frac{\partial \mathbf{r}^{(1)}}{\partial \xi_{1}}^{T} & \cdots & \frac{\partial \mathbf{r}^{(1)}}{\partial \xi_{8}}^{T}
\\
\vdots & \ddots & \vdots
\\
\frac{\partial \mathbf{r}^{(N)}}{\partial \xi_{1}}^{T} & \cdots & \frac{\partial \mathbf{r}^{(N)}}{\partial \xi_{8}}^{T}
\end{bmatrix}
\begin{bmatrix}
\mathbf{r}^{(1)}
\\
\vdots
\\
\mathbf{r}^{(N)}
\end{bmatrix}
=
\begin{bmatrix}
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \mathbf{c}}^{T}\mathbf{r}^{(i)}
\\
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{1}}^{T}\mathbf{r}^{(i)}
\\
\vdots
\\
\sum^{N}_{i=1}\frac{\partial \mathbf{r}^{(i)}}{\partial \xi_{8}}^{T}\mathbf{r}^{(i)}
\end{bmatrix}
$$
4.4. Null Space Effect Elimination
4.4.1. Ambiguity Problems

DSO는 단안카메라를 활용한 Visual Odometry이므로 맵포인트의 깊이를 정확하게 알 수 없는 scale ambiguity 문제를 가진다. 예를 들면, 내가 현재 실제 도시의 이미지를 보고 있는 것인지 도시의 미니어쳐 이미지를 보고 있는 것인지를 단안카메라만 사용하서는 정확하게 알 수 없다는 의미이다. 즉, 카메라의 trajectory와 모든 맵포인트들을 일괄적으로 키우거나 줄여도 최적화 단계에서 아무런 영향을 미치지 않는다.
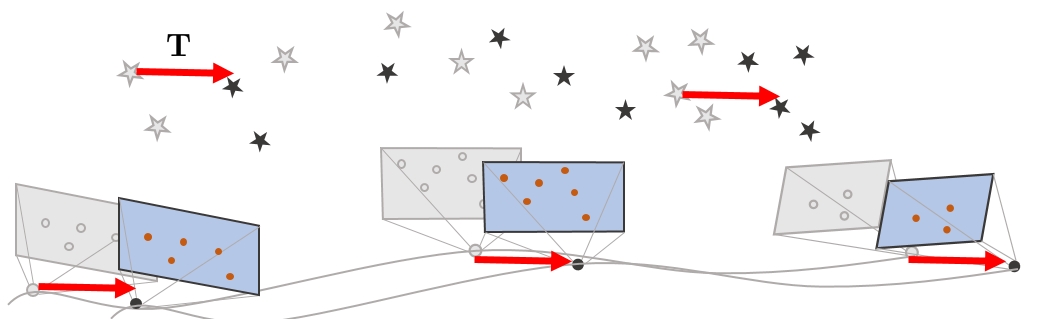
또한 모든 카메라 포즈들과 맵포인트에 동일한 SE(3) 변환을 적용하면 이 또한 최적화 단계에서 아무런 영향을 미치지 않는다. 이를 coordinate system ambiguity 문제라고 한다. (자세한 정보는 https://blog.csdn.net/wubaobao1993/article/details/105106301 참조)
4.4.2. Null Space
null space란 정방행렬 $\mathbf{A} \in \mathbb{R}^{n\times n}$과 벡터 $\mathbf{x} \in \mathbb{R}^{n}$가 존재할 때 다음을 만족하는 해집합을 의미한다.
$$\mathbf{Ax} = 0$$
일반적으로 Gauss-Newton (GN) 방법을 사용할 때 다음과 같은 공식을 풀어야 하는 상황이 발생한다.
$$\mathbf{H}\Delta \mathbf{x} = -\mathbf{b}$$
- $\mathbf{H} = \mathbf{J}^{T}\mathbf{J} \in \mathbb{R}^{n\times n}$
- $\mathbf{b} = \mathbf{J}^{T}\mathbf{e}\in \mathbb{R}^{n}$
- $\Delta \mathbf{x} \in \mathbb{R}^{n}$
만약 $\mathbf{H}$의 역행렬이 존재하는 경우 $\Delta \mathbf{x}$는 다음과 같은 유일해(unique solution)을 가진다
$$\Delta \mathbf{x} = -\mathbf{H}^{-1}\mathbf{b} \quad \text{if } \mathbf{H} \text{ is invertible}$$
$\mathbf{H}$의 역행렬이 존재하지 않는 경우 $\Delta \mathbf{x}$는 특수해(particular solution) $\Delta \mathbf{x}_{p}$와 일반해(homogeneous solution) $\Delta \mathbf{x}_{h}$를 합한 완전해(complete solution)을 갖는다.
$$\Delta \mathbf{x} = \Delta \mathbf{x}_{h} + \Delta \mathbf{x}_{p} \quad \text{if } \mathbf{H} \text{ is not invertible}$$
우선 비동차방정식(non-homogeneous equation)에서 특수해 $\Delta \mathbf{x}_{p}$를 구할 수 있다.
$$\mathbf{H}\Delta \mathbf{x}_{p} = -\mathbf{b}$$
다음으로 동차방정식(homogeneous equation)에서 일반해 $\Delta \mathbf{x}_{h}$를 구할 수 있다.
$$\mathbf{H}\Delta \mathbf{x}_{h} = 0$$
따라서 $\mathbf{H}$의 역행렬이 존재하지 않는 경우 완전해는 다음과 같이 나타낼 수 있다. 이 때 $\lambda$는 임의의 정수를 의미하며 $\lambda$ 값에 관계없이 아래 식은 항상 성립하므로 완전해는 무수히 많은 해를 가진다.
$$\Delta \mathbf{x} = \Delta \mathbf{x}_{p} + \lambda \Delta \mathbf{x}_{h} $$
$$\mathbf{H}(\Delta \mathbf{x}_{p} + \lambda \Delta \mathbf{x}_{h}) = -\mathbf{b} $$
여기서 null space는 $\Delta \mathbf{x}_{h}$의 해집합으로 인해 span되는 공간을 의미한다.
$$\mathbf{N} = \text{Span}(\Delta \mathbf{x}_{h}) $$
null space는 전체 방정식의 값에 영향을 미치지 않으므로 null space의 선형결합인 $\mathbf{N}\Delta \mathbf{x}$ 또한 null space에 포함되어 다음과 같은 방정식이 성립한다.
$$\mathbf{H}\Delta \mathbf{x} + \mathbf{N}\Delta \mathbf{x}= -\mathbf{b} $$
4.4.3. Null Space in DSO
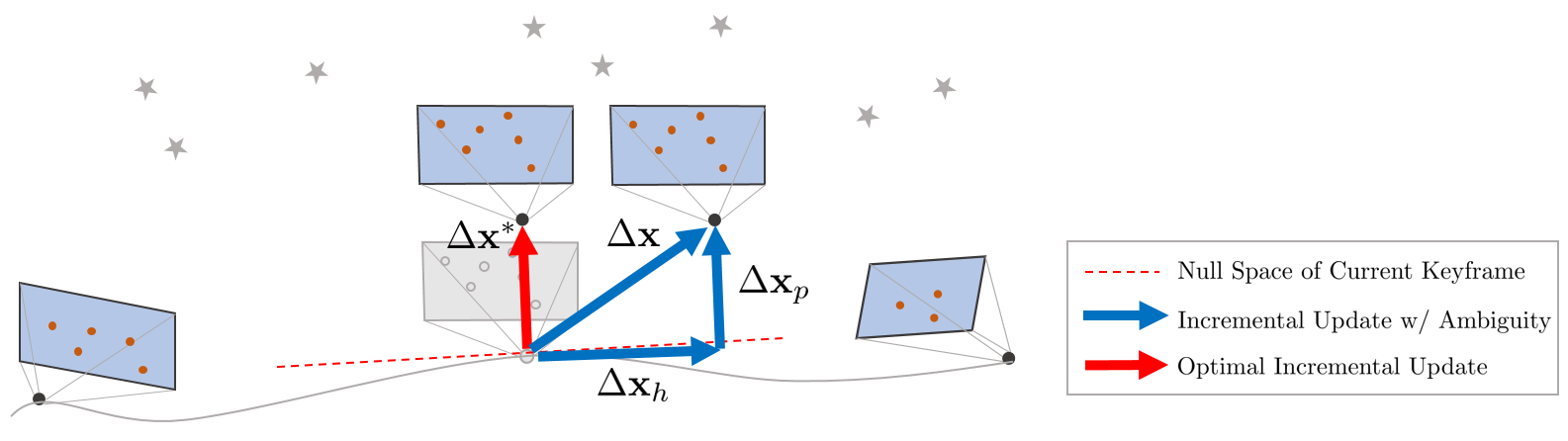
null space는 시스템(=에러함수) $\|\mathbf{E}(\mathbf{x} + \Delta \mathbf{x})\|$ 값에는 영향을 미치지 않지만 업데이트 값 $\Delta \mathbf{x}$에는 영향을 미치므로 null space의 영향이 곧 ambiguity 문제의 원인이 된다. 따라서 DSO에서는 LBA를 수행할 때 null space의 영향을 제거하여 ambiguity 문제를 해결하는 방법을 사용했다.
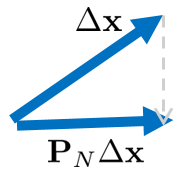
예를 들어 위 그림과 같이 LBA를 통해 업데이트 값 $\Delta \mathbf{x} = \Delta \mathbf{x}_{p} + \Delta \mathbf{x}_{h} $ 이 구해졌다고 가정하면 여기에서 null space에 프로젝션된 양 $\mathbf{P}_{N}\Delta \mathbf{x}$만큼을 빼줌으로써 null space의 영향을 제거할 수 있다.
프로젝션 행렬 $\mathbf{P}_{N}$은 $\mathbf{N}^{T}\mathbf{N}$의 역행렬이 존재하는가 안하는가에 따라 2가지 방법으로 구할 수 있다.
\begin{equation*}
\begin{aligned}
\mathbf{P}_{\mathbf{N}} & = \mathbf{NN}^{\dagger} \\
& = \mathbf{N}(\mathbf{N}^{T}\mathbf{N})^{-1}\mathbf{N}^{T} \quad \text{if, } \mathbf{NN}^{T} \ \text{is invertible.} \\
& = \mathbf{N}(\mathbf{V}\Sigma^{\dagger}\mathbf{U}^{T}) \quad \text{if, } \mathbf{NN}^{T} \ \text{is not invertible. Do SVD}
\end{aligned}
\end{equation*}
결론적으로 다음과 같이 최적의 업데이트 값 $\Delta \mathbf{x}^{*} $를 계산함으로써 null space의 영향을 제거할 수 있다.
$$\Delta \mathbf{x}^{*} = \Delta \mathbf{x} - \mathbf{NN}^{\dagger} \Delta \mathbf{x}$$
4.4.4. Detailed Derivation of Null Space in DSO
프로젝션 행렬을 사용하지 않고 다른 방법으로 유도하면 다음과 같다. 우선 최적의 업데이트 값 $\Delta \mathbf{x}^{*} $는 다음과 같이 나타낼 수 있다. 이 때, $\mathbf{N}\Delta \mathbf{x}_{h}$는 null space에 의해 드리프트된 값을 의미한다.
$$\Delta \mathbf{x}^{*} = \Delta \mathbf{x} - \mathbf{N}\Delta \mathbf{x}_{h}$$
null space가 에러함수의 값에 영향을 미치지 않는다는 점을 사용하면 다음 공식이 성립한다.
\begin{equation*}
\begin{aligned}
\mathbf{E}(\mathbf{x}+\Delta \mathbf{x}) = \mathbf{E}(\mathbf{x} + \Delta \mathbf{x} - \mathbf{N}\Delta \mathbf{x}_{h})
\end{aligned}
\end{equation*}
위 공식의 두 에러함수를 1차 테일러 전개하여 정리하면 다음과 같이 나타낼 수 있다.
\begin{equation*}
\begin{aligned}
\mathbf{E}(\mathbf{x} + \Delta\mathbf{x} - \mathbf{N}\Delta \mathbf{x}_{h}) & = \mathbf{e}(\mathbf{x}+\Delta \mathbf{x} - \mathbf{N}\Delta \mathbf{x}_{h})^{T}\mathbf{e}(\mathbf{x}+\Delta \mathbf{x} - \mathbf{N}\Delta \mathbf{x}_{h}) \\
& \simeq (\mathbf{e}(\mathbf{x}) + \mathbf{J}(\Delta \mathbf{x}-\mathbf{N}\Delta \mathbf{x}_{h}))^{T}(\mathbf{e}(\mathbf{x}) + \mathbf{J}(\Delta \mathbf{x}-\mathbf{N}\Delta \mathbf{x}_{h})) \\
& = \underbrace{\mathbf{e}^{T}\mathbf{e} + \mathbf{e}^{T}\mathbf{J}\Delta \mathbf{x} + \Delta \mathbf{x}\mathbf{J}^{T}\mathbf{e} + \Delta \mathbf{x}^{T}\mathbf{J}^{T}\mathbf{J}\Delta \mathbf{x}}_{\mathbf{E}(\mathbf{x}+\Delta \mathbf{x})}
\underbrace{-\mathbf{e}^{T}\mathbf{JN}\Delta \mathbf{x}_{h} - (\mathbf{N}\Delta \mathbf{x}_{h})^{T}\mathbf{J}^{T}\mathbf{e} - (\mathbf{N}\Delta \mathbf{x}_{h})^{T}\mathbf{J}^{T}\mathbf{J}\Delta \mathbf{x} - \Delta \mathbf{x} \mathbf{J}^{T}\mathbf{J}(\mathbf{N}\Delta \mathbf{x}_{h}) + (\mathbf{N}\Delta \mathbf{x}_{h})^{T}\mathbf{J}^{T}\mathbf{J}(\mathbf{N}\Delta \mathbf{x}_{h})}_{\Delta \mathbf{x}_{h} \ part} \\
& = \mathbf{E}(\mathbf{x} + \Delta \mathbf{x})
\end{aligned}
\end{equation*}
따라서 공통부분을 소거한 후 다시 정리하면 다음과 같은 공식이 성립하고
\begin{equation*}
\begin{aligned}
(\mathbf{N}\Delta \mathbf{x}_{h})^{T}\mathbf{J}^{T}\mathbf{J}(\mathbf{N}\Delta \mathbf{x}_{h}) = \mathbf{e}^{T}\mathbf{JN}\Delta \mathbf{x}_{h} + (\mathbf{N}\Delta \mathbf{x}_{h})^{T}\mathbf{J}^{T}\mathbf{e} + (\mathbf{N}\Delta \mathbf{x}_{h})^{T}\mathbf{J}^{T}\mathbf{J}\Delta \mathbf{x} + \Delta \mathbf{x} \mathbf{J}^{T}\mathbf{J}(\mathbf{N}\Delta \mathbf{x}_{h})
\end{aligned}
\end{equation*}
여기서 null space의 선형결합에 해당하는 $\mathbf{N}\Delta \mathbf{x}_{h}$와 에러함수의 기울기를 의미하는 $\mathbf{J}^{T}\mathbf{e}$는 서로 직교하므로 다음이 성립한다.
$$\mathbf{N}\Delta \mathbf{x}_{h}\mathbf{J}^{T}\mathbf{e} = 0$$
따라서 남은 식들을 정리하면 다음 공식이 성립한다.
$$\mathbf{N}\Delta \mathbf{x}_{h} = \Delta \mathbf{x}$$
하지만 위 공식은 실제로 서로 일치하지 않으므로 이를 $\Delta \mathbf{x}_{h}$에 대한 least squares를 활용하여 근사해를 구하면 $\| \mathbf{N}\Delta \mathbf{x}_{h} - \Delta \mathbf{x}\|$의 크기가 최소가 되는 근사해를 구할 수 있다. 이 때, $\mathbf{N}^{T}\mathbf{N}$의 역행렬이 존재하는가 아닌가에 따라 다음과 같이 해를 구할 수 있다.
\begin{equation*}
\begin{aligned}
& \Delta \mathbf{x}_{h} = \mathbf{N}^{\dagger}\Delta \mathbf{x} \quad \text{if, } \mathbf{NN}^{T} \ \text{ is invertible.} \\
& \Delta \mathbf{x}_{h} = \mathbf{V}\mathbf{D}^{\dagger}\mathbf{U}^{T}\Delta \mathbf{x} \quad \text{if, } \mathbf{NN}^{T} \ \text{ is not invertible.} \\
\end{aligned}
\end{equation*}
결론적으로 다음과 같이 최적의 업데이트 값 $\Delta \mathbf{x}^{*} $를 계산할 수 있다.
$$\Delta \mathbf{x}^{*} = \Delta \mathbf{x} - \mathbf{N}\Delta \mathbf{x}_{h} \Rightarrow \Delta \mathbf{x}^{*} = \Delta \mathbf{x} - \mathbf{NN}^{\dagger} \Delta \mathbf{x}$$
null space 영향이 제거된 $\mathbf{H}^{*}, \mathbf{b}^{*}$를 다음과 같이 유도할 수 있다.
\begin{equation*}
\begin{aligned}
\Delta \mathbf{x}^{T} \mathbf{b}^{*} & = \Delta \mathbf{x}^{T} \mathbf{b} - \Delta \mathbf{x}_{h}^{T}\mathbf{b}_{n} \\
& = \Delta \mathbf{x}^{T} \mathbf{b} - (\mathbf{N}^{\dagger}\Delta \mathbf{x})^{T}\mathbf{N}^{T}\mathbf{J}^{T}\mathbf{e} \\
& = \Delta \mathbf{x}^{T}\mathbf{b} - \Delta \mathbf{x}^{T}(\mathbf{NN}^{\dagger})^{T}\mathbf{b} \\
& = \text{where, } \mathbf{b}_{n} = \mathbf{J}_{n}\mathbf{e} \ \ \mathbf{J}_{n} = \frac{\partial \mathbf{e}}{\partial \Delta \mathbf{x}_{h}} = \frac{\partial \mathbf{e}}{\partial \Delta \mathbf{x}}\frac{\partial \Delta \mathbf{x}}{\partial \Delta \mathbf{x}_{h}} = \mathbf{JN}
\end{aligned}
\end{equation*}
\begin{equation*}
\begin{aligned}
\Delta \mathbf{x}^{T} \mathbf{H}^{*} \Delta \mathbf{x} & = \Delta \mathbf{x}^{T} \mathbf{H}\Delta \mathbf{x} - \Delta \mathbf{x}_{h}^{T}\mathbf{H}_{n}\Delta \mathbf{x}_{h} \\
& = \Delta \mathbf{x}^{T}\mathbf{H}\Delta \mathbf{x} - (\mathbf{N}^{\dagger}\Delta \mathbf{x})^{T}\mathbf{N}^{T}\mathbf{J}^{T}\mathbf{JN}(\mathbf{N}^{\dagger}\Delta \mathbf{x}) \\
& = \Delta \mathbf{x}^{T} \mathbf{H} \Delta \mathbf{x} - \Delta \mathbf{x}^{T}(\mathbf{NN}^{\dagger})^{T} \mathbf{H} (\mathbf{NN}^{\dagger})\Delta \mathbf{x} \\
& \text{where, } \mathbf{H}_{n} = \mathbf{J}_{n}^{T}\mathbf{J}_{n}, \ \ \mathbf{J}_{n} = \frac{\partial \mathbf{e}}{\partial \Delta \mathbf{x}_{h}} = \frac{\partial \mathbf{e}}{\partial \Delta \mathbf{x}}\frac{\partial \Delta \mathbf{x}}{\partial \Delta \mathbf{x}_{h}} = \mathbf{JN}.
\end{aligned}
\end{equation*}
따라서 최종적으로 다음의 연산을 통해 null space의 영향을 제거할 수 있다.
$$\mathbf{b}^{*} = \mathbf{b} - (\mathbf{NN}^{\dagger})^{T}\mathbf{b}$$
$$\mathbf{H}^{*} = \mathbf{H} - (\mathbf{NN}^{\dagger})^{T}\mathbf{H}(\mathbf{NN}^{\dagger})$$
5. Pixel Selection
5.1. Make Histogram
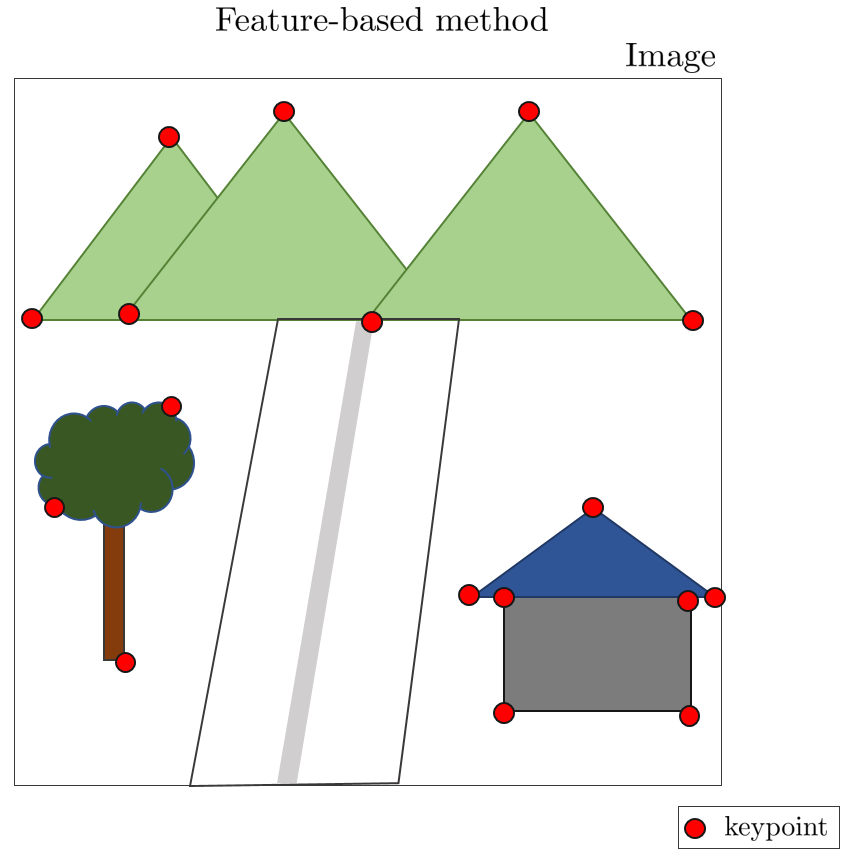
ORB-SLAM2와 같은 feature-based VO의 경우 이미지 내에서 특정 포인트를 추출할 때 feature extraction 알고리즘을 사용하여 키포인트를 추출한다. 그 다음 해당 키포인트를 3차원 점으로 Unprojection $\pi^{-1}(\cdot)$하고 다시 2차원 점으로 Reprojection $\pi(\cdot)$해서 reprojection error를 사용하여 카메라의 모션을 계산한다.
하지만 direct method를 사용하는 DSO는 키포인트를 추출하는 과정없이 특정 픽셀의 밝기 오차를 계산하기 때문에 특정 포인트를 추출하는 방법 또한 feature-based와 달라지게 된다. DSO에서는 이미지에서 특정 포인트를 추출하기 위해 gradient histogram과 dynamic grid 방법을 사용했다. 해당 방법은 DSO 논문에서도 자세한 설명이 부족하고 참고 논문이 없으며 구글링해도 나오는 정보가 거의 없으므로 해당 섹션에서 다루는 내용이 100% 정확하다고 볼 수 없다. 해당 내용은 논문을 볼 때 참고용으로 보면 좋을 것 같다.
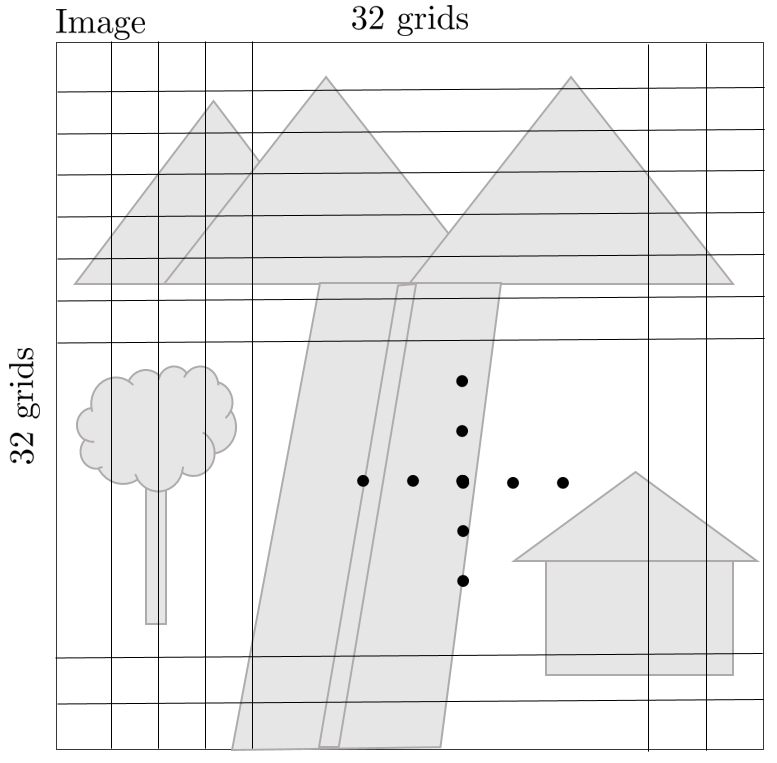
1. 우선 새로운 이미지가 들어오면 gradient histogram을 생성하기 위해 이미지를 32x32 영역으로 나눈다. (grayscale)
2. 하나의 영역을 확대해서 보면 아래 그림과 깉이 여러 픽셀들로 구성되어 있고 각 픽셀마다 고유의 밝기 값을 가지고 있다. 이를 이용해 image gradient (dx,dy)를 구할 수 있고 해당 영역에 대한 히스토그램을 만들 수 있다.
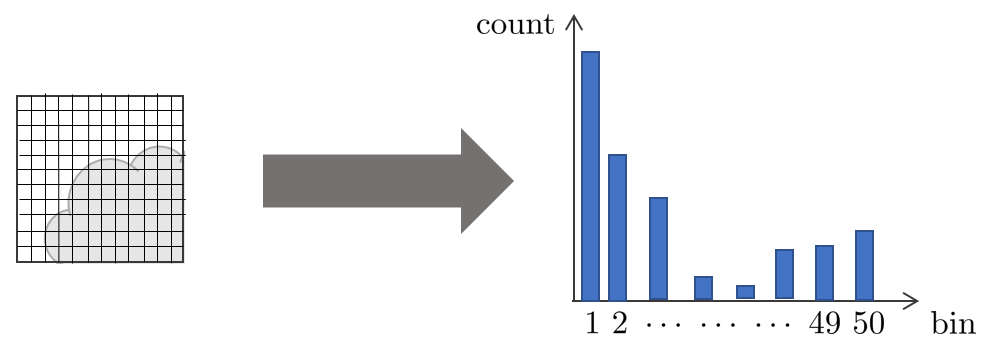
3. 이 때, gradient $dx,dy$는 원래 0~255 값을 가지지만 DSO에서는 한 픽셀의 bin = $\sqrt{dx^{2}+dy^{2}}$ 값을 사용하여 히스토그램을 생성했다.
$$0<\sqrt{dx^{2}+dy^{2}}<360$$
bin은 위와 같은 범위를 가지지만 이를 1~50 범위로 제한하여 50이 넘는 경우 최대값을 50으로 설정하여 히스토그램의 범위를 단순화했다.
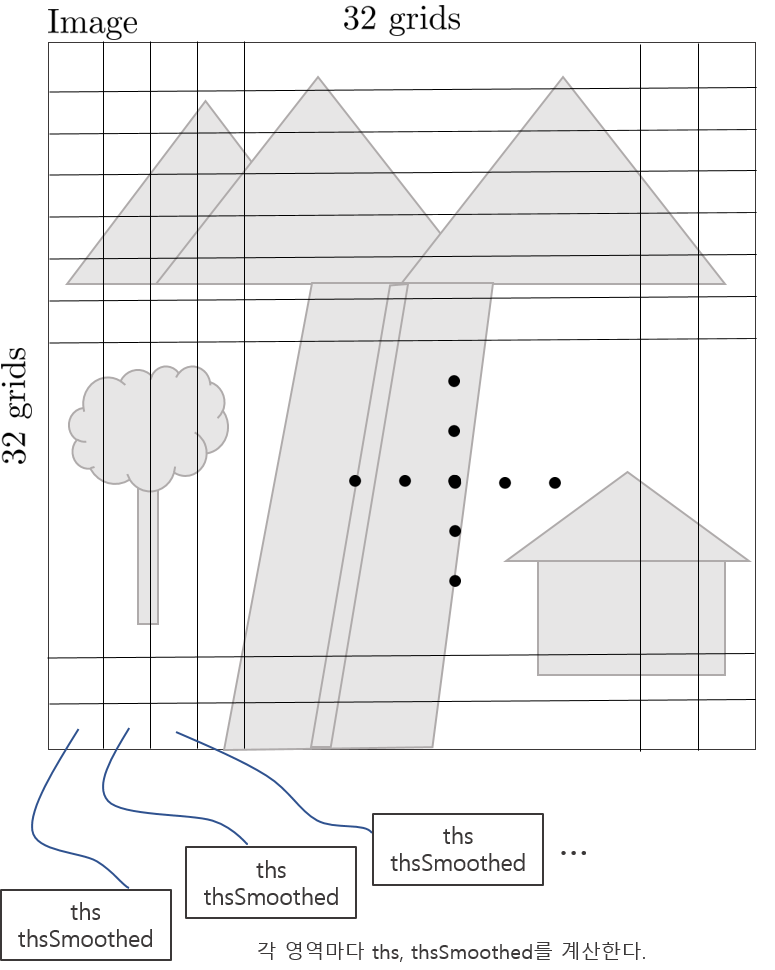
4. 이러한 히스토그램을 32x32 모든 영역에 대해 계산한다.
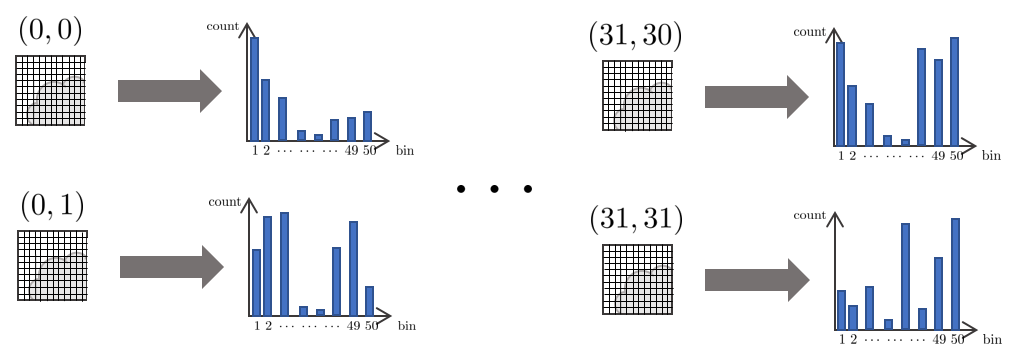
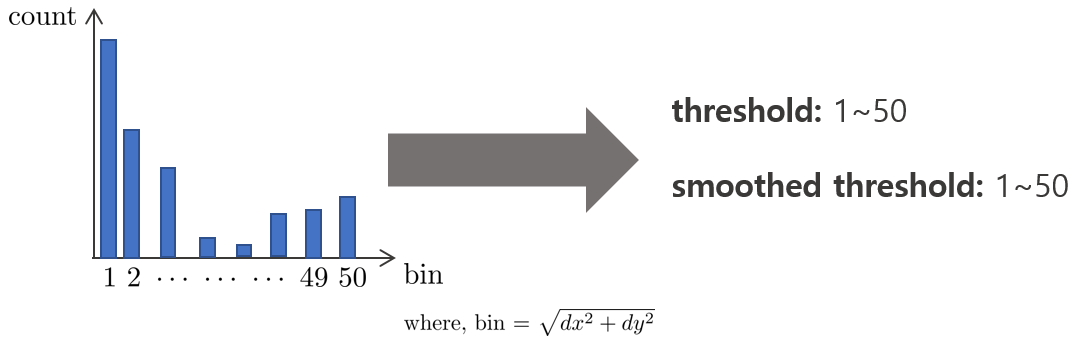
5. 히스토그램에서 total count의 50%가 되는 bin 값을 1-50 순서대로 찾는다. 예를 들어, 히스토그램의 모든 bin에서 총 1000개가 카운트되었다면 1번 bin부터 순서대로 카운트 값을 빼주면서 해당 값이 500보다 작아지는 bin을 threshold로 설정한다. 또한, 주변 3x3 영역의 threshold 평균을 사용한 smoothed threshold 값 또한 설정한다.
5.2. Dynamic Grid
한 이미지에 대한 32x32 히스토그램을 생성하고 threshold 값을 설정하였으면 다음으로 dynamic grid 방법을 통해 이미지 내에서 픽셀을 선택한다. 이를 통해 high gradient 영역에 대부분의 포인트가 추출되는 것을 방지하고 한 이미지 내에서 추출할 수 있는 총 포인트의 개수(N=2000)을 관리할 수 있다.
1. 하나의 grid 영역의 크기를 설정한다. DSO는 초기값으로 12x12 [pixel]을 사용했다. 640x480 이미지 기준으로 봤을 때 일반적으로 32x32 histogram 영역보다 작은 크기를 사용한다. grid 크기를 설정하였으면 이미지 전체를 grid로 나눈다.
2. 한 grid 영역을 확대해보면 아래와 같다. 이 때, 한 영역에서 총 3개의 피라미드 이미지의 gradient를 사용한다. Alalagong님의 자료를 참조하여 피라미드 별로 파란색(lv2), 초록색(lv1), 빨간색(lv0, 원본)으로 표시하면 아래 그림과 같고 순서대로 해당 영역의 픽셀을 탐색한다.
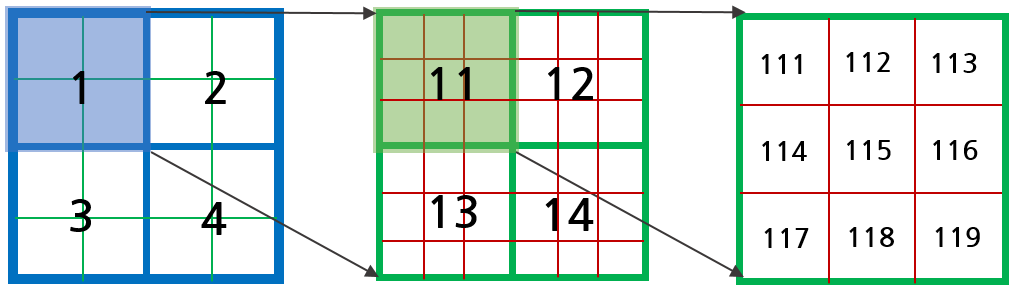
3. 피라미드 레벨이 낮은 곳(lv0, 원본)부터 한 픽셀 씩 루프를 돌면서 해당 영역 히스토그램의 smoothed threshold 값과 픽셀의 squared gradient $\sqrt{dx^{2}+dy^{2}}$ 값을 비교한다. (111 -> 112 -> 113 -> ... -> 119 -> 11 -> 1 -> 121 -> 122 -> 123 -> ... -> 129 -> 12 -> 2 -> ...)
이 때, 특정 픽셀 값이 smoothed treshold보다 크면 다음 단계로써 해당 픽셀의 $(dx,dy)$ 값과 랜덤한 방향벡터인 randdir과 norm을 계산하여 해당 값이 0보다 큰 지 검사한다.
$$\text{randdir} \cdot (dx,dy) > 0$$
4. 최종적으로 norm까지 특정 값보다 크다면 해당 픽셀을 grid를 대표하는 픽셀로 선정하고 루프를 탈출한다.
ex) 만약 115 픽셀의 $\sqrt{dx^{2}+dy^{2}}$ 값이 smoothed threshold보다 크고 $\text{randdir} \cdot (dx_{115},dy_{115}) > 0$를 만족하면 115 픽셀을 grid 대표 픽셀로 선정하고 루프를 탈출한다. 랜덤한 방향벡터와 norm을 계산함으로써 특정 픽셀 영역에 포인트 추출이 몰리는 현상을 방지했다.
5. 만약 픽셀이 smoothed threshold보다 작은 경우 lv0 -> lv1 -> lv2 순서로 값을 비교한다. 이 때, 레벨이 높을수록 threshold에 0.75를 곱한 후 픽셀의 밝기 값과 비교하여 높은 피라미드 레벨의 픽셀일수록 추출될 확률을 높였다.
6. 모든 픽셀을 전부 검사했음에도 추출한 포인트의 총합이 원하는 총량(기본 N=2000)보다 적을 경우 ($N_{\text{want}}/N_{\text{have}} > 1.25 $)에는 8x8로 한 grid 크기를 줄인 후 다시 검색하고 만약 추출된 포인트가 너무 많은 경우 ($N_{\text{want}}/N_{\text{have}} < 0.25$)에는 16x16 grid 크기로 포인트를 다시 추출한다.
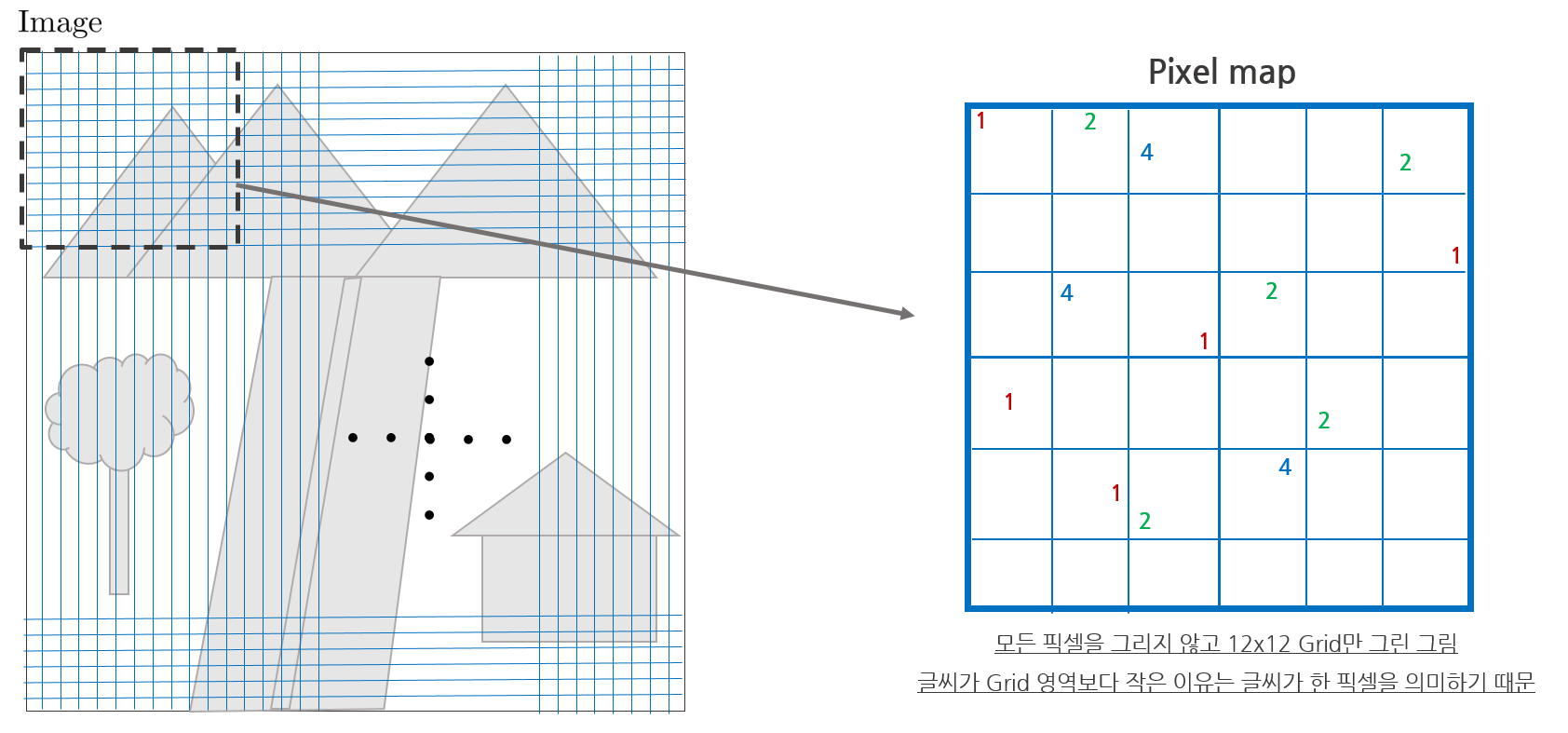
7. 한 이미지 내에서 모든 grid에 대해 루프를 돌면서 smoothed threshold를 통과한 픽셀들만 pixel map에 저장한다. pixel map에는 lv0에서 추출된 포인트의 경우 '1', lv1에서 추출된 포인트는 '2', lv3에서 추출된 포인트는 '4'의 값을 갖는다. 포인트가 추출되지 않는 영역의 값은 '0'을 갖는다.
6. Code Review
References
5. [CH] DSO tracking and optimization
8. [CH] DSO photometric calibration
9. [CH] DSO code with comments
11. [CH] DSO (5) Calculation and Derivation of Null Space
'Engineering' 카테고리의 다른 글
| [SLAM] g2o example 코드 리뷰 (0) | 2022.06.09 |
|---|---|
| [SLAM] Visual LiDAR Odometry and Mapping (V-LOAM) 논문 리뷰 (0) | 2022.06.08 |
| [SLAM] Depth Enhanced Monocular Odometry (DEMO) 논문 리뷰 (0) | 2022.06.08 |
| [SLAM] Direct Sparse Odometry (DSO) 논문 및 코드 리뷰 (1) (5) | 2022.06.03 |
| [SLAM] Lidar Odometry And Mapping (LOAM) 논문 리뷰 (27) | 2022.06.02 |





