추정 이론(Estimation Theory) 개념 정리 Part 1 - MVUE, CRLB
alida2024. 2. 10. 12:33
본 포스트는 필자가 추정 이론을 공부한 내용을 바탕으로 정리한 포스팅이다.
1. Introduction
추정 이론(estimation theory)는 관측된 데이터를 바탕으로 모델의 파라미터나 상태를 예측하는 다양한 방법을 정리한 이론이다. 이는 데이터 분석, 신호처리, 기계학습, 금융, 로봇공학 등 다양한 분야에서 널리 쓰이고 있으며 주로 불확실성을 다루는 과정에서 정확한 결정을 내리기 위한 필수적인 도구로 사용된다. 추정 이론의 응용 분야는 매우 넓은데 통신에서는 신호의 품질을 추정하거나 기계학습에서는 데이터로부터 알고리즘의 파라미터를 결정하는데 사용된다. 또한 금융 분야에서는 시장의 미래 동향을 예측하기 위한 변수를 추정하는데 필수적으로 사용되고 있다.
1.1. The Mathematical Estimation Problem
다음과 같은 데이터 모델이 주어졌다고 가정하자. \begin{equation} \begin{aligned} x[n] = \theta + w[n] \quad n=0,1,\cdots,N-1 \end{aligned} \end{equation} - $x[n]$: 관측된 데이터 - $\theta$: 추정하고자 하는 미지의 파라미터
위 식에서 $w[n]$은 랜덤 노이즈라고 하며 일반적으로 평균이 $0$이고 분산은 $\sigma^2$인 가우시안 분포를 따른다고 가정한다. \begin{equation} \begin{aligned} w[n] \sim \mathcal{N}(0, \sigma^{2}) \end{aligned} \end{equation} - $a \sim \mathcal{N}(\mu, \sigma^{2})$ : 확률변수 $a$가 평균이 $\mu$이고 분산이 $\sigma^{2}$인 가우시안 분포를 따른다.
좋은 추정값(estimator)을 얻기 위해서는 우선 수학적으로 데이터를 잘 모델링해야 한다. 데이터는 랜덤성을 띄기 때문에 확률 밀도 함수(probability density function, pdf) $p(x[0], x[1], \cdots, x[N-1]; \theta)$를 사용하여 데이터를 표현한다. 이 때 $x[n]$은 $N$개의 데이터를 의미하며 $\theta$는 미지의 모델 파라미터를 의미한다. 만약 $N=1$인 경우 pdf는 아래와 같이 나타낼 수 있다.
pdf를 표기하는 서로 다른 방법을 정리하면 다음과 같다. 1. $p(x; \theta)$ : 매개 변수 $\theta$에 대한 $x$의 확률 분포 (pdf of $x$ paramterized by $\theta$) 2. $p(x|\theta)$ : $\theta$가 주어졌을 때 $x$의 조건부 확률 분포 (pdf of $x$ given $\theta$) 3. $p(x,\theta)$ : $x, \theta$가 동시에 발생할 결합 확률 분포 (joint pdf of $x, \theta$)
1.에서 $\theta$는 확률 변수(random variable)일수도 있고 아닐수도 있다. $x$는 확률 변수이다. 2.,3.에서 $x$와 $\theta$는 반드시 확률 변수이어야 한다. 3. 에서 두 확률 변수 $x, \theta$는 일반적으로 서로 독립이 아니며 종속적이다.
위 식에서 보다시피 파라미터 $\theta$는 $x[0]$의 확률에 직접적인 영향을 주기 때문에, 역으로 $x[0]$의 값을 보고 $\theta$를 추정하는 것이 가능하다.
예를 들면 아래와 같은 그림이 주어졌다고 했을 때 $x[0]$ 값이 음수가 관측되면 우리는 $\theta=\theta_{2}$보다는 $\theta=\theta_1$이라고 일반적으로 유추할 수 있다. 하지만 실제 문제에서는 위와 같은 pdf는 주어지지 않기 때문에 데이터 $x$와 파라미터 $\theta$의 관계를 정의해야 한다.
다음으로 다른 유형의 데이터 모델을 살펴보자. \begin{equation} \begin{aligned} x[n] = A + Bn + w[n] \quad \quad n=0,1,\cdots,N-1 \end{aligned} \end{equation}
이 때, 추정하고자 하는 파라미터는 $\theta = [A,B]^{\intercal}$가 된다. $N$개의 데이터를 벡터화하여 $\mathbf{x} = [x[0], x[1], \cdots, x[N-1]]^{\intercal}$라고 표현하면 $\mathbf{x}$에 대한 pdf는 다음과 같다.
pdf에 기반한 (\ref{eq:intro1})과 같은 추정은 고전적인 추정 방법으로써 파라미터 $\theta$를 우리가 모르지만 고정된 상수로 보는 빈도주의(frequentist) 관점으로 해석될 수 있다. 이와 달리 현대적인 추정 방법은 파라미터 $\theta$ 또한 별도의 확률 변수로 해석하는 베이지안(bayesian) 관점을 주로 사용한다.
직관적으로 우리는 모든 데이터(또는 무한개의 데이터)를 관측하는게 아닌 이상 좋은 추정값을 얻는 것이 어렵다는 것을 알 수 있다. 실제로 $\breve{A} = 69.8$이고 $\hat{A} = 71.1$이어서 $\breve{A}$가 $A=70$에 더 가깝다. 이런 경우 $\breve{A}$가 더 좋은 추정값이라고 볼 수 있을까? 당연히 아니다.
추정값(estimator) $\hat{A}$는 확률변수 $x[n]$에 대한 함수이므로 $\hat{A}$ 역시 확률변수가 된다. 따라서 추정값 역시 노이즈로 인해 다양한 결과물들을 도출할 수 있다. $\breve{A}$가 $A$에 더 가깝다는 사실은 주어진 $x[n]$의 예제에 대해서만을 의미한다. 따라서 추정값의 성능을 평가하기 위해서는 반드시 통계적으로 접근해야 한다. 예를 들어 여러번의 실험을 통해 데이터를 수집하고 이를 반복적으로 추정하는 방법이 존재한다.
데이터를 여러번 수집한 후 추정값 $\hat{A}, \breve{A}$의 기대값(expectation)을 계산하면 다음과 같다.
추정값(estimator)는 확률변수(random variable)이다. 따라서 추정값의 성능은 반드시 통계적 방법이나 pdf를 통해 판단되어야 한다.
컴퓨터 시뮬레이션을 사용하여 추정값을 평가하는 방법은 파라미터에 대한 통찰을 얻기엔 충분히 좋지만 이를 절대적인 값으로 해석하면 안된다. 운이 좋은 경우 추정값은 소수점 오차를 가진 정확도로 구할 수 있지만 운이 나쁜 경우에는(데이터가 부족하거나 에러 값이 들어 있거나) 잘못된 추정값을 얻을 수 있다.
2. Minimum Variance Unbiased Estimation
본 섹션에서 나오는 추정값들은 고전적인 빈도주의 관점에서 파라미터 $\theta$가 고정된 값으로 주어졌다고 가정한다.
2.1. Unbiased Estimators
추정값이 불편성(unbiased)을 지닌다는 의미는 추정값의 평균이 파라미터의 참 값과 동일하다는 의미와 동치이다. 일반적으로 파리미터는 특정 범위 $a < \theta < b$ 안에 존재하므로 불편추정값(unbiased estimator, 또는 불편추정량)이란 다음과 같이 수학적으로 정의할 수 있다.
\begin{equation} \begin{aligned} \mathbb{E}(\breve{A}) & = \frac{1}{2}A \\ & = A \quad \text{ if } A = 0 \\ & \neq A \quad \text{ if } A \neq 0 \end{aligned} \end{equation}
따라서 $\breve{A}$는 편의추정값(biased estimator)이다.
불편추정값이 반드시 좋은 추정값을 의미할까? 추정값이 불편성을 지닌다고 해서 반드시 좋은 추정값이라는 의미는 아니다. 불편성의 의미는 오직 추정값의 기대값(expectation)이 실제 값과 동일하다는 의미만 지닌다. 이와 반대로 편의추정값은 시스템의 노이즈를 포함하여 모델링한 값일 수 있다. 하지만 영구적인 편향성은 항상 안 좋은 추정값을 가진다. 예를 들면 다음과 같이 동일 파라미터 $\theta$에 대한 여러 추정값 $\{ \hat{\theta}_{1}, \hat{\theta}_{2}, \cdots, \hat{\theta}_{n}\}$이 주어졌을 때 가장 합리적인 방법은 이들의 기대값을 구하는 것이다.
따라서 위 식에서 보다시피 많은 수($n \uparrow$)의 추정값을 사용할 수록 분산은 작아진다. 만약 $n \rightarrow \infty$이면 분산은 0이 되고 $\hat{\theta} \rightarrow \theta$가 된다. 하지만 편의추정량의 경우 $\mathbb{E}(\hat{\theta}_{i}) = \theta + b(\theta)$이므로 다음과 같은 기대값을 가진다.
- $\theta$ : 추정해야 할 파라미터. 빈도주의 관점에 의해 $\theta$는 고정된 상수 값을 의미한다. 즉, 확률변수가 아니다.
MSE는 실제 값 $\theta$과 추정값 $\hat{\theta}$의 평균 제곱 편차를 측정한다. MSE는 널리 사용되는 criterion 중 하나이지만 아쉽게도 편향에 의한 영향을 받는다. 위 식에 $\pm \mathbb{E}(\hat{\theta})$를 추가한 후 식을 전개하면 다음과 같다.
따라서 최적의 추정값을 찾기 위한 criterion을 고려할 때 MSE를 최소화해주는 minimum MSE(MMSE) 추정값을 고려하면 안된다. MMSE의 대안으로 편향이 0이고 분산을 최소화하는 추정값을 사용해야 하는데 이를 minimum variance unbiased estimator(MVUE)라고 한다. 불편추정값의 분산을 최소화하는 과정은 pdf 관점에서 $p(\hat{\theta} - \theta)$를 0 주변에 집중시키는 효과가 있다. 따라서 추정 오차가 커질 가능성이 작아진다.
2.3. Existence of the Minimum Variance Unbiased Estimator
독자는 MVUE가 실제로 존재하는지 여부에 대해 궁금증이 생길 수 있다. 즉, 모든 파라미터 $\theta$에 대해 최소의 분산을 가지며 불편향된 추정값이 존재하는지 궁금할 수 있다. 결론만 말하자면 MVUE는 항상 존재하는 것은 아니다.
2.4. Finding the Minimum Variance Unbiased Estimator
만약 MVUE가 존재한다고해도 이를 찾는 것이 불가능할 수 있다. MVUE를 찾을 수 있는 절대적인 방법이란 아직 알려지지 않았다. 하지만 이를 가능하게 해주는 몇몇 기준들은 존재한다.
Cramer-Rao lower bound(CRLB)를 결정하고 추정값들이 이를 만족하는지 확인한다.
Rao-Blackwell-Lehmann-Scheffe(RBLS) 이론을 적용한다.
추정값이 불편성(unbiased) 뿐만아니라 선형(linear) 특성이 있다는 제약조건 하에 분산을 최소화하는 MVUE를 구한다.
1,2 방법을 사용하면 MVUE를 구할 수 있고 3 방법은 MVUE가 데이터에 대하여 선형인 경우에만 적용된다.
1,2) CRLB는 임의의 불편추정값에 대하여 분산의 하한선(lower bound)를 결정하게 해준다. 만약 어떤 추정값이 CRLB와 동일한 분산 값을 가진다면 이는 반드시 MVUE가 된다. CRLB와 동일한 분산 값을 가지지 않는다고 하더라도 MVUE가 존재할 수 있다. 이럴 때는 RBLS를 적용한다. RBLS는 충분통계량(sufficient statistics)을 먼저 구한 후 충분통계량에 대한 추정을 수행하는데 이 때 추정값이 $\theta$에 대한 불편추정값이 된다.
3) 이는 추정값이 선형이어야 하는 제약조건을 가진다. 이는 때때로 강력한 제약조건이지만 최적의 선형 추정값을 구할 수 있다.
3. Cramer-Rao Lower Bound
어떠한 불편추정값(unbiased estimator)의 분산의 하한선(lower bound)를 결정할 수 있다는 것은 실제 추정 문제에서 매우 유용하게 사용된다. 최선의 경우 특정 추정값이 MVUE임을 바로 구할수도 있다. 그렇지 않은 경우라 하더라도 여러 불편추정량에 대한 벤치마크 용도로 활용될 수도 있다. 이는 신호 추정 분야에서 매우 유용하게 활용된다. Cramer-Rao lower bound(CRLB) 이외에도 [McAulay and Hofstetter 1971, Kendall and Stuart 1979, Seidman 1970, Ziv and Zakai 1969]와 같이 분산의 한계(bound)를 결정하는 알고리즘들이 존재하지만 CRLB가 이들 중 가장 쉽게 한계를 구할 수 있다.
3.1. Estimator Accuracy Considerations
추정에 사용되는 정보는 일반적으로 관측된 데이터로부터 얻을 수 있고 관측 데이터는 노이즈를 포함하기 때문에 일반적으로 pdf로 표현될 수 있다. 따라서 추정의 정확도는 당연히 pdf와 직접적인 관련이 있다. 만약 파라미터가 pdf에 영향을 거의 주지 않는 최악의 경우에는 좋은 추정값을 얻는 것이 어려울 것이다. 따라서 파라미터가 pdf에 영향을 많이 줄수록 추정의 정확도는 올라간다.
3.1.1. Example 3.1 - PDF Dependence on Unknown Parameter
만약 하나의 데이터가 샘플링되었다고 가정해보자
\begin{equation} \begin{aligned} x[0] = A + w[0] \end{aligned} \end{equation}
이 때, $w[n]$는 $\mathcal{N}(0, \sigma^{2})$을 따르는 white gaussian noise(WGN)이다. 일반적으로 좋은 추정값(estimator)이란 $\sigma^{2}$가 작은 추정값임을 알 수 있다. 그리고 좋은 불편추정값은 $\hat{A} = x[0]$임을 알 수 있다.
분산 $\sigma^{2}$ 값이 작을 수록 좋은 추정값임을 설명하기 위해 아래와 같은 예제를 들 수 있다. 만약 서로 다른 두 분산 $\sigma_{1}=1/3$와 $\sigma_{2}=1$이 주어졌고 $x[0]=3$인 경우를 가정해보자. 이에 대한 pdf는 다음과 같다.
$\sigma_{1}^2 < \sigma_{2}^2$이므로 우리는 $p_{1}(\cdot)$이 $A$를 더 잘 추정하고 있다고 판단할 수 있다. 예를 들어 $A=4.5$일 확률은 $p_{1}$보다 $p_{2}$가 더 높으므로 우리는 $p_{1}$이 더 좁은 범위에 대한 확실한 확률분포를 가짐을 알 수 있다.
Likelihood Function v.s. Probability Density Function 만약 pdf $p(x; \theta)$가 $x$는 고정된 값이면서 동시에 파라미터 $\theta$에 대한 함수라면 이를 일반적으로 가능도함수(likelihood function)라고 부른다. 이와 반대로, $p(x;\theta)$가 $\theta$는 고정된 값이면서 동시에 $x$에 대한 함수라면 이는 일반적인 확률밀도함수(probability density function, pdf)라고 부른다. 두 개념을 비교한 그림은 아래와 같다. $p(x;\theta)$는 다음과 같다. \begin{equation} \begin{aligned} p(x;\theta) = \frac{1}{ \sqrt{ 2\pi\sigma^{2} }} \exp\bigg[ -\frac{1}{2\sigma^{2}} (x - \theta)^{2} \bigg] \end{aligned} \end{equation}
그림에서 보는 것과 같이 pdf와 가능도함수는 모양만 같을 뿐 이를 해석하는 관점이 서로 다르다. pdf의 경우 파라미터가 주어졌을 때 특정 구간 내에서 확률을 구하는 것에 관심이 있다면 가능도함수는 데이터가 주어졌을 때 이를 가장 잘 설명하는 파라미터는 무엇인가? 에 관심이 있다.
지금까지 설명한 pdf는 전부 데이터 $x$가 주어졌을 때 파라미터 $A$를 찾는 형태이기 때문에 이는 가능도함수(likelihood function) 관점에서 해석할 수 있다. 가능도함수의 뾰족한 정도(sharpness)는 추정값이 얼마나 정확한 지에 대한 정확도를 판단하는데 사용된다.수학적으로 곡선의 뾰족한 정도는 함수의 2차 미분을 수행하여 곡률(curvature)를 구함으로써 얻을 수 있다.이 때, pdf 특성 상 exponential 항이 존재하여 계산이 어렵기 때문에 일반적으로 log를 취한 값을 사용하는데 이를 로그 가능도함수(log likelihood function)이라고 한다.
위 식의 의미는 $\sigma^{2}$가 감소할수록 원래 함수의 곡률(curvature)을 의미하는 $-\frac{\partial^{2} \ln p(x[0];A)}{\partial A^{2}}$는 증가하는 것을 의미한다. 앞서 말한 추정값 $\hat{A} = x[0]$의 분산은 다음과 같다.
위 식은 로그 가능도함수의 1차 미분이 위와 같은 임의의 함수 $I, g$의 곱셈 형태로 표현되어야 한다는 뜻이다. 이 때 불편추정값은 $\hat{\theta} = g(\mathbf{x})$가 되며 $\hat{\theta}$는 MVUE를 만족한다. 이 때의 최소 분산 값은 $1/I(\theta)$이 되며 이를 Fisher information이라고 한다. Fisher information은 일반적으로 다음과 같이 정의한다.
따라서 CRLB 정의에 따라 임의의 불편추정값 $\breve{A}$의 분산이 $\text{var}(\breve{A}) = \frac{\sigma^{2}}{N}$을 만족하면 이는 반드시 MVUE가 된다. 위 예제에서는 $\breve{A}=\bar{x}$가 MVUE가 된다. 그리고 이러한 추정값을 efficient하다라고 한다. 관측 데이터를 효율적(efficient)으로 사용하여 추정하였다는 의미이다.
3.3. Transformation of Parameters
실제 추정 문제에서는 우리가 추정하고자 하는 파라미터가 단순한 $\theta$가 아닌 $\theta$의 함수 형태를 추정해야 하는 일이 자주 발생한다. 이전 예제에서도 단순히 $A$를 추정하는 것이 아닌 $A^{2}$를 추정하고 싶을 수도 있다. 만약 A의 CRLB를 알고 있는 경우에는 $A^{2}$의 CRLB도 쉽게 구할 수 있고 $A$와 관련된 어떤 함수라도 구할 수 있다.
추정하고자 하는 파라미터가 $\alpha = g(\theta)$와 같이 $\theta$에 대한 함수일 경우 CRLB는 다음과 같다.
이전 Example 3.3 예제에서 $\hat{A} = \bar{x}$는 $A$에 대하여 efficient함을 보였다. 따라서 $\bar{x}^{2}$ 역시 $A^{2}$에 대하여 efiicient하다고 예상할 수 있으나 이는 사실이 아니다. 그 이전에 $\hat{A^{2}} = \bar{x}^{2}$는 $A^{2}$에 대한 불편추정값 조차 아니다. 즉, 편향(bias)이 존재한다.
위 식에서 (\ref{eq:crlb4}), (\ref{eq:crlb5})의 분산이 동일하기 때문에 $\hat{\alpha}$ 역시 MVUE이면서 동시에 efficient함을 알 수 있다.
앞서 보았듯이 efficiency는 linear 또는 affine 변환에서만 보존되는 것을 확인하였다. 하지만 데이터가 충분히 큰 경우에는 비선형 변환도 근사적으로(approximately) efficiency가 보존된다. 다시 이전 예제 $\alpha = g(A) = A^{2}$로 돌아가서 데이터 $x[n]$의 평균을 $\bar{x} = \frac{1}{N} \sum_{n=0}^{N-1} x[n]$이라고 할 때 $\bar{x}^{2}$는 $N$이 충분히 클 경우 근사적으로 편향이 제거된다.
(\ref{eq:crlb6}), (\ref{eq:crlb6})가 $N$이 충분히 큰 경우에 대하여 서로 동일하기 때문에 데이터가 많은 경우에는 비선형 변환에 대한 추정값도 MVUE가 되며 동시에 efficient함을 알 수 있다.
다른 방법을 사용하여 비선형 변환이 근사적으로 efficient함을 보일 수 있다. 확률분포 관점에서 봤을 때 $N$이 커질수록 $\hat{\mathbf{x}}$는 $A$ 주변으로 뾰족해지는 경향이 있다. 이에 따라 $\pm 3\sigma$ 사이의 간격은 좁아지게 되고 좁은 영역에 대해여 비선형 변환을 수행하면 근사적으로 선형 변환을 한 것과 유사한 효과를 얻는다. 이를 $\bar{x} = A$ 지점에서 테일러 1차 근사를 통해 표현하면 다음과 같다.
즉 추정값은 CRLB에 점근적으로(asymptotically) 도달하는 것을 알 수 있다. 따라서 비선형 변환은 점근적으로 efficient하다.
3.4. Extension to a Vector Parameter
지금까지는 추정하려는 파라미터 $\theta$가 스칼라 값이었다. 해당 섹션에서는 파라미터가 여러개인 벡터 파리미터 $\boldsymbol{\theta} = [\theta_{1}, \theta_{2},\cdots, \theta_{p}]^{\intercal}$ 케이스에 대해 다룬다. $\hat{\boldsymbol{\theta}}$는 $\boldsymbol{\theta}$에 대한 불편추정값(unbiased estimator)이라고 가정한다. 벡터 파라미터의 각 원소의 분산은 다음과 같이 나타낼 수 있다.
위 식은 로그 가능도함수의 1차 미분이 위와 같은 임의의 함수 $\mathbf{I}, \mathbf{g}$의 곱셈 형태로 표현되어야 한다는 뜻이다. 이 때 불편추정값은 $\hat{\boldsymbol{\theta}} = \mathbf{g}(\mathbf{x})$가 되며 $\hat{\boldsymbol{\theta}}$는 MVUE를 만족한다. 이 때의 최소 분산 값은 $1/\mathbf{I}(\boldsymbol{\theta})$이 된다.
위 예제에서 보다시피 스칼라 파라미터 $\theta=A$만 추정했을 때와는 달리 $\boldsymbol{\theta}= [A, \ B]^{\intercal}$처럼 벡터 파라미터를 추정하면 CRLB는 커지는 것을 알 수 있다. 스칼라 파라미터만 추정했을 때 CRLB는 다음과 같다.
따라서 $N \geq 2$인 경우에는 벡터 파라미터의 CRLB가 항상 스칼라 파라미터의 CRLB보다 크다.
\begin{equation} \begin{aligned} \frac{2(2N-1)\sigma^2}{N(N+1)} > \frac{\sigma^2}{N} \quad \cdots \text{ for } N \geq 2 \end{aligned} \end{equation}
또한 특정 파라미터는 다른 파라미터보다 데이터 개수 $N$에 민감하게 반응할 수 있다.
\begin{equation} \begin{aligned} \frac{\text{CRLB}(\hat{A})}{\text{CRLB}(\hat{B})} = \frac{(2N-1)(N-1)}{6} > 1 \quad \cdots \text{ for } N \geq 3 \end{aligned} \end{equation}
$\text{CRLB}(\hat{B})$는 데이터 증가에 $1/N^3$으로 감소하는 반면, $\text{CRLB}(\hat{A})$는 데이터 증가에 $1/N$ 비율로 감소한다. 이러한 차이로 인해 $x[n]$이 $B$를 변경하는 것에 $A$를 변경하는 것보다 더 민감하게 반응한다는 것을 알 수 있다.
3.5. Vector Parameter CRLB for Transformations
스칼라 파라미터의 변환에 대해 이전 섹션에서 알아본 것 처럼, 실제 추정 문제에서는 단순히 벡터 파라미터 $\boldsymbol{\theta}$를 추정해야 하는 것이 아닌 $\boldsymbol{\theta}$의 함수 형태를 추정해야 하는 일이 자주 발생한다.
추정하고자 하는 파라미터가 $\boldsymbol{\alpha} = \mathbf{g}(\boldsymbol{\theta})$와 같이 $\boldsymbol{\theta}$에 대한 함수이며 $r$ 차원의 함수의 함수일 경우 다음 수식을 만족해야 한다. (자세한 유도 과정은 Appendix 3B 참조)
3.5.1. Example 3.8 - CRLB for Signal-to-Noise Ratio
다음과 같은 관측 데이터가 주어졌다고 하자.
\begin{equation} \begin{aligned} x[n] = A + w[n] \quad \text{ where } w[n] \overset{\text{i.i.d.}}{\sim} \mathcal{N}(0, \sigma^{2}) \end{aligned} \end{equation}
$\theta = [A, \ \sigma^2]^{\intercal}$는 미지의 파라미터이며 우리가 추정하고자 하는 값은 $\alpha = \frac{A^2}{\sigma^2}$라고 하자. 이러한 $\alpha$를 signal to noise ratio(SNR)이라고 한다. $\alpha = g(\boldsymbol{\theta}) = \theta_{1}^{2}/\theta_2 = A^2 / \sigma^2$과 같이 나타낼 수 있으므로 이를 통해 Fisher information 행렬을 표현하면 다음과 같다.
위 식에서 보다시피 $N \rightarrow \infty$가 되어도 CRLB는 $2\sigma_{A}^{4}$ 이하로 내려가지 않는다. 이는 각각의 개별 관측 데이터가 전부 $A$에 대한 정보를 포함하고 있기 때문에 $A$의 분산 값이 항상 반영되기 때문이다.
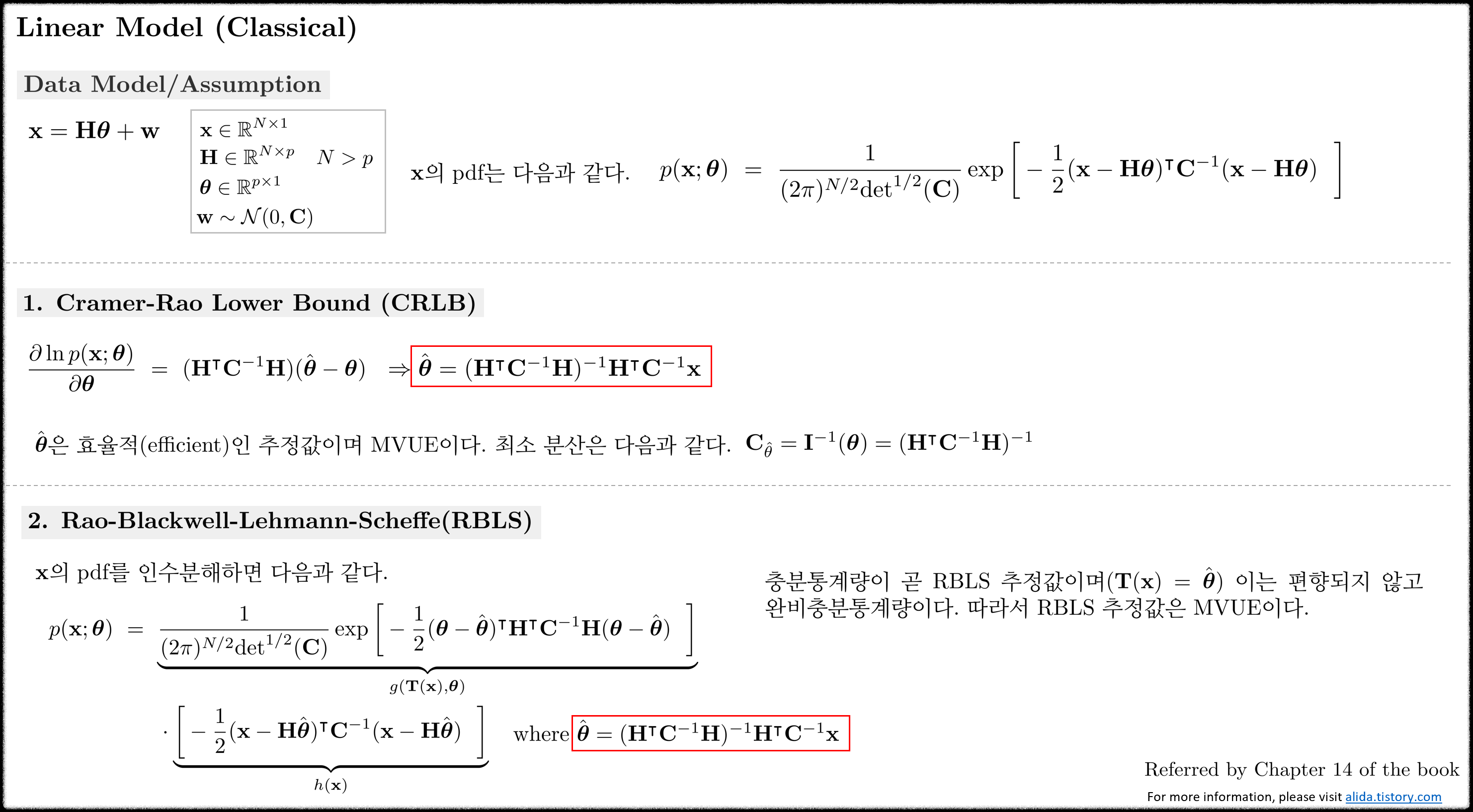
4. Linear Models
일반적으로 MVUE를 찾는 과정은 쉬운 작업이 아니다. 하지만 다행이도 많은 신호 처리 문제들은 선형(linear) 데이터 모델의 형태를 가지는데 이러한 특성이 쉽게 MVUE를 결정할 수 있도록 도와준다. 선형 모델임이 확인되면 MVUE 값이 즉시 명백해지는 것 뿐만 아니라 통계적인 성능도 자연스럽게 따라온다. 그러므로 최적의 추정값을 찾는 열쇠는 문제를 선형 모델로 구조화하여 그 고유한 특성을 활용하는 것이 중요하다.
행렬 $\mathbf{H}$는 $N\times2$의 크기를 가지며 일반적으로 관측 함수(observation matrix)라고 부른다. 데이터 $\mathbf{x}$는 파라미터 $\boldsymbol{\theta}$가 관측 행렬 $\mathbf{H}$를 통과한 다음에 관측되기 때문이다. 노이즈 벡터도 $\mathbf{w} \sim \mathcal{N}(\mathbf{0}, \sigma^2 \mathbf{I})$와 같이 벡터 형태로 나타낼 수 있다. 이러한 (\ref{eq:lm1})의 형태를 선형 모델(liinear model)이라고 부른다. 선형모델의 노이즈는 일반적으로 가우시안 형태를 가진다.
앞서 3장의 Theorm 3.2에서 본 것처럼 $\hat{\boldsymbol{\theta}} = \mathbf{g}(\mathbf{x})$가 MVUE가 되려면 다음 식을 만족해야 한다. \begin{equation} \label{eq:lm2} \begin{aligned} \frac{\partial \ln p(\mathbf{x};\boldsymbol{\theta}) }{\partial \boldsymbol{\theta}} = \mathbf{I}(\boldsymbol{\theta})(\mathbf{g}(\mathbf{x}) - \boldsymbol{\theta}) \end{aligned} \end{equation}
그리고 위 식을 만족할 때 $\hat{\boldsymbol{\theta}}$의 분산은 $\mathbf{I}^{-1}(\boldsymbol{\theta})$가 된다. 이러한 Theorem 3.2의 조건들을 선형 모델에 대해 확장하면 다음과 같다.
많은 신호는 주기적인 특성을 지닌다. 이러한 강한 주기적 특성은 푸리에 해석(Fourier analysis)를 통해 수학적으로 모델링할 수 있다. 푸리에 계수(coefficient)록 해당 주파수 성분이 강하게 포함되어 있다는 의미를 지닌다. 해당 예제에서는 푸리에 해석을 하는 과정이 선형 모델 파라미터를 추정하는 것과 동일한 과정임을 보인다. 다음과 같은 정현파 신호에 가우시안 노이즈가 추가된 예제를 보자.
\begin{equation} \begin{aligned} x[n] = \sum_{k=1}^{M} a_k \cos\bigg( \frac{2\pi k n}{N}\bigg) + \sum_{k=1}^{M} b_k \sin\bigg( \frac{2\pi k n}{N}\bigg) + w[n] \quad n = 0,1,\cdots, N-1 \end{aligned} \end{equation}
- $w[n] \sim \mathcal{N}(0, \sigma^{2})$ : WGN
주파수 성분은 $f_1 = 1/N$부터 $f_k =k/N$ 성분이 복합적으로 섞여 있는 것으로 가정한다. 여기서 우리는 $a_k, b_k$ 계수를 추정해야 한다. 벡터 파라미터를 다음과 같이 정의한다.
위 식에서 행렬의 크기는 $N \times 2M$이며 $p=2M$이 된다. $\mathbf{H}$가 $N > p$를 만족하려면 $M < N/2$가 되어야 한다. $\mathbf{H}$의 각 열벡터는 DFT 특성에 의해 서로 직교(orthogonal)하므로 계산을 편하게 하기 위해 이를 열벡터로 표시한다.
추정값의 분산 $\mathbf{C}_{\hat{\boldsymbol{\theta}}}$이 대각 행렬이므로 각 파라미터들은 서로 독립적이다. 이러한 독립적 특성으로 인해 $\mathbf{H}$의 열벡터가 서로 직교하여 $\mathbf{H}^{\intercal}\mathbf{H}$가 매우 단순하게 계산되었다. 만약 주파수 성분을 임의의 성분으로 변경하면 직교성이 상실되어 MVUE를 구하는 과정이 매우 복잡해진다.
4.2. Extension to the Linear Model
일반적인 경우 선형 모델의 노이즈는 WGN이 아니다. 선형 모델을 일반적인 경우로 확장하면 노이즈는 다음과 같이 모델링할 수 있다.
$\mathbf{C}$ 행렬은 더 이상 스칼라 값이 곱해진 대각 identity 행렬이 아니다. 노이즈는 0 이상의 값을 가지기 때문에 $\mathbf{C}$는 positive definite 행렬이라고 가정할 수 있고 따라서 $\mathbf{C}^{-1}$ 또한 positive definite이다. 이를 다음과 같이 분해할 수 있다.
 A L I D A
A L I D A