 A L I D A
A L I D A
arXiv preprint
English version
Notes on Various Errors and Jacobian Derivations for SLAM
This paper delves into critical concepts and meticulous calculations pertinent to Simultaneous Localization and Mapping (SLAM), with a focus on error analysis and Jacobian matrices. We introduce various types of errors commonly encountered in SLAM, includi
arxiv.org
1. Introduction
본 포스트에서는 SLAM에서 사용하는 다양한 에러에 대한 정의 및 이를 최적화하기 위해 사용하는 자코비안에 대해 설명한다.
본 포스트에서 다루는 에러는 다음과 같다.
- Reprojection error \begin{equation}
\begin{aligned}
\mathbf{e} & = \mathbf{p} - \hat{\mathbf{p}} \in \mathbb{R}^{2}
\end{aligned}
\end{equation} - Photometric error \begin{equation}
\begin{aligned}
\mathbf{e} & = \mathbf{I}_{1}(\mathbf{p}_{1})-\mathbf{I}_{2}(\mathbf{p}_{2}) \in \mathbb{R}^{1}
\end{aligned}
\end{equation} - Relative pose error \begin{equation}
\begin{aligned}
\mathbf{e}_{ij} = \text{Log} (\mathbf{z}_{ij}^{-1}\hat{\mathbf{z}}_{ij}) \in \mathbb{R}^{6}
\end{aligned}
\end{equation} - Line reprojection error \begin{equation}
\begin{aligned}
\mathbf{e}_{l} = \begin{bmatrix} \frac{\mathbf{x}_{s}^{\intercal}l_{c}}{\sqrt{l_{1}^{2} + l_{2}^{2}}}, & \frac{\mathbf{x}_{e}^{\intercal}l_{c}}{\sqrt{l_{1}^{2} + l_{2}^{2}}}\end{bmatrix} \in \mathbb{R}^{2}
\end{aligned}
\end{equation} - IMU measurement error : \begin{equation}
\begin{aligned}
\mathbf{e}_{\mathcal{B}} = \begin{bmatrix}
\delta \alpha^{b_{k}}_{b_{k+1}} \\
\delta \boldsymbol{\theta}^{b_{k}}_{b_{k+1}} \\
\delta \beta^{b_{k}}_{b_{k+1}} \\
\delta \mathbf{b}_{a}\\
\delta \mathbf{b}_{g}\\
\end{bmatrix} = \begin{bmatrix}
\mathbf{R}^{b_{k}}_{w}(\mathbf{p}^{w}_{b_{k+1}} - \mathbf{p}^{w}_{b_{k}} - \mathbf{v}^{w}_{b_{k}}\Delta t_{k} + \frac{1}{2} \mathbf{g}^{w}\Delta t_{k}^{2}) - \hat{\alpha}^{b_{k}}_{b_{k+1}} \\
2 \Big[ \Big( \hat{\gamma}^{b_{k}}_{b_{k+1}} \Big)^{-1} \otimes (\mathbf{q}^{w}_{b_{k}})^{-1} \otimes \mathbf{q}^{w}_{b_{k+1}} \Big]_{xyz} \\
\mathbf{R}^{b_{k}}_{w} ( \mathbf{v}^{w}_{b_{k+1}} - \mathbf{v}^{w}_{b_{k}} + \mathbf{g}^{w}\Delta t_{k}) - \hat{\beta}^{b_{k}}_{b_{k+1}} \\
\mathbf{b}_{a_{k+1}} - \mathbf{b}_{a_{k}} \\
\mathbf{b}_{g_{k+1}} - \mathbf{b}_{g_{k}} \\
\end{bmatrix}
\end{aligned}
\end{equation}
카메라 포즈는 회전행렬 $\mathbf{R} \in SO(3)$로 표현하느냐 또는 변환행렬 $\mathbf{T} \in SE(3)$로 표현하느냐에 따라 서로 다른 자코비안이 유도된다. 두 가지 자코비안을 구하기 위해 reprojection 에러의 경우 SO(3)에 대한 자코비안을 유도하고 photometric 에러의 경우 SE(3)에 대한 자코비안을 유도한다. 또한 3차원 공간 상의 점 또한 $\mathbf{X}=[X,Y,Z,W]^{\intercal}$로 표현하는 방법과 inverse depth $\rho$로 표현하는 방법에 따라 자코비안이 달라진다. 두 경우에 대한 자코비안 유도 과정에 대해서도 설명한다.
본 포스트에서 다루는 자코비안은 다음과 같다.
- Camera pose (SO(3)-based) \begin{equation}
\begin{aligned}
\frac{\partial \mathbf{e}}{\partial \mathbf{R}} \rightarrow \frac{\partial \mathbf{e}}{\partial \Delta \mathbf{w}} \end{aligned}
\end{equation} - Camera pose (SE(3)-based) \begin{equation}
\begin{aligned}
\frac{\partial \mathbf{e}}{\partial \mathbf{T}} \rightarrow \frac{\partial \mathbf{e}}{\partial \Delta \xi} \end{aligned}
\end{equation} - Map point \begin{equation}
\begin{aligned}
\frac{\partial \mathbf{e}}{\partial \mathbf{X}} \end{aligned}
\end{equation} - Relative pose (SE(3)-based) \begin{equation}
\begin{aligned}
& \frac{\partial \mathbf{e}_{ij}}{\partial \Delta \xi_{i}}, \frac{\partial \mathbf{e}_{ij}}{\partial \Delta \xi_{j}} \end{aligned}
\end{equation} - 3D plücker line \begin{equation}
\begin{aligned}
& \frac{\partial \mathbf{e}_{l}}{\partial l}, \frac{\partial l}{\partial \mathcal{L}_{c}}, \frac{\partial \mathcal{L}_{c}}{\partial \mathcal{L}_{w}}, \frac{\partial \mathcal{L}_{w}}{\partial\delta_{\boldsymbol{\theta}}} \end{aligned}
\end{equation} - Quaternion representation \begin{equation}
\begin{aligned}
& \frac{\partial \mathbf{X}'}{\partial \mathbf{q}}
\end{aligned} \end{equation} - Camera intrinsics \begin{equation}
\begin{aligned}
& \frac{\partial \mathbf{e}}{\partial f_{x}}, \frac{\partial \mathbf{e}}{\partial f_{y}}, \frac{\partial \mathbf{e}}{\partial c_{x}}, \frac{\partial \mathbf{e}}{\partial c_{y}} \end{aligned}
\end{equation} - Inverse depth \begin{equation}
\begin{aligned}
\frac{\partial \mathbf{e}}{\partial \rho} \end{aligned}
\end{equation} - IMU error-state system kinematics : \begin{equation} \begin{aligned} \mathbf{J}^{b_{k}}_{b_{k+1}} \end{aligned} \end{equation}
- IMU measurement : \begin{equation} \begin{aligned}
\frac{\partial \mathbf{e}_{\mathcal{B}} }{\partial [\mathbf{p}^{w}_{b_{k}}, \mathbf{q}^{w}_{b_{k}}]},\frac{\partial \mathbf{e}_{\mathcal{B}} }{\partial [\mathbf{v}^{w}_{b_{k}}, \mathbf{b}_{a_{k}}, \mathbf{b}_{g_{k}}]} , \frac{\partial \mathbf{e}_{\mathcal{B}} }{\partial [\mathbf{p}^{w}_{b_{k+1}}, \mathbf{q}^{w}_{b_{k+1}}]}, \frac{\partial \mathbf{e}_{\mathcal{B}} }{\partial [\mathbf{v}^{w}_{b_{k+1}}, \mathbf{b}_{a_{k+1}}, \mathbf{b}_{g_{k+1}}]}
\end{aligned}
\end{equation}
2. Optimization formulation
2.1. Error derivation
SLAM에서 에러는 센서 데이터에 의한 관측값(measurement) $\mathbf{z}$과 수학적 모델링에 의한 예측값(estimate) $\hat{\mathbf{z}}$의 차이로 정의한다.
\begin{equation}
\boxed{ \begin{aligned}
\mathbf{e}(\mathbf{x}) = \mathbf{z} - \mathbf{\hat{z}}(\mathbf{x})
\end{aligned} }
\end{equation}
- $\mathbf{x}$: 모델의 상태 변수
위와 같이 관측값과 예측값의 차이를 에러로 정하고 에러를 최소로 하는 최적의 상태변수 $\mathbf{x}$를 계산하는 것이 SLAM에서 최적화 문제가 된다. 이 때, 일반적인 경우 SLAM의 상태변수에는 회전과 관련된 비선형 항이 포함되므로 비선형 최소제곱법(non-linear least squares) 방법이 주로 사용된다.
2.2. Error function derivation
일반적으로 다량의 센서 데이터가 들어오면 이에 대한 수십~수백개의 에러가 벡터 형태로 계산된다. 이 때, 에러가 정규분포를 따른다고 가정하고 에러 함수로 변환하는 작업을 수행한다.
\begin{equation}
\begin{aligned}
\mathbf{e}(\mathbf{x}) = \mathbf{z} - \mathbf{\hat{z}}(\mathbf{x}) \sim \mathcal{N}(0, \mathbf{\Sigma})
\end{aligned}
\end{equation}
에러 함수를 모델링하기 위한 확률변수 $\mathbf{x}$에 대한 다변수 정규분포는 다음과 같다.
\begin{equation}\begin{aligned}p(\mathbf{x})=\frac{1}{\sqrt{(2\pi)^n|\boldsymbol\Sigma|}}\exp\left(-\frac{1}{2}({\mathbf{x}}-{\boldsymbol\mu})^{\intercal}{\boldsymbol\Omega}({\mathbf{x}}-{\boldsymbol\mu})\right) \sim \mathcal{N}(\boldsymbol\mu, \mathbf{\Sigma})\end{aligned}\end{equation}
- $\mathbf{x} \in \mathbb{R}^{n}$
- $\boldsymbol\mu \in \mathbb{R}^{n}$: mean vector
- $\boldsymbol\Sigma \in \mathbb{R}^{n\times n}$: covariance matrix
- $|\boldsymbol\Sigma|$: determinant of $\boldsymbol\Sigma$
- $\mathbf{\Omega} = \mathbf{\Sigma}^{-1}$ : information matrix (inverse of covariance matrix)
에러를 평균이 $0$이고 분산이 $\mathbf{\Sigma}$인 다변수 정규분포로 모델링할 수 있다.
\begin{equation}\begin{aligned}p(\mathbf{e})=\frac{1}{\sqrt{(2\pi)^n|\boldsymbol\Sigma|}}\exp\left(-\frac{1}{2}({\mathbf{z}}-\hat{\mathbf{z}}(\mathbf{x}))^{\intercal}{\boldsymbol\Sigma}^{-1}({\mathbf{z}}-\hat{\mathbf{z}}(\mathbf{x}))\right) \end{aligned}\end{equation}
위 식으로부터 다음과 같은 비례식이 성립한다.
\begin{equation}
\begin{aligned}
p(\mathbf{e}) & \propto \exp \bigg( -\frac{1}{2}(\mathbf{z} - \mathbf{\hat{z}}(\mathbf{x}))^{\intercal}\mathbf{\Omega}(\mathbf{z} - \mathbf{\hat{z}}(\mathbf{x})) \bigg) \\
\end{aligned}
\end{equation}
위 식에 log-likelihood를 적용한 $\ln p(\mathbf{e})$는 다음과 같다.
\begin{equation}
\begin{aligned}
\ln p(\mathbf{e}) & \propto -\frac{1}{2}(\mathbf{z} - \mathbf{\hat{z}}(\mathbf{x}))^{\intercal}\mathbf{\Omega}(\mathbf{z} - \mathbf{\hat{z}}(\mathbf{x})) \\
& \propto -\frac{1}{2}\mathbf{e}(\mathbf{x})^{\intercal}\mathbf{\Omega}\mathbf{e}(\mathbf{x})
\end{aligned}
\end{equation}
log-likelihood $\ln p(\mathbf{e})$가 최대가 되는 $\mathbf{x}^{*}$를 찾으면 다변수 정규분포의 확률이 최대가 된다. 이를 Maximum Liklihood Estimation (MLE)라고 한다. $\ln p(\mathbf{e})$는 앞에 음수(-)가 있으므로 negative log-likelihood가 최소가되는 $\ln p(\mathbf{e})$를 찾으면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{x}^{*} & = \arg\max \ln p(\mathbf{e}) \\
& = \arg\max -\frac{1}{2}\mathbf{e}(\mathbf{x})^{\intercal}\mathbf{\Omega}\mathbf{e}(\mathbf{x})
\\
& = \arg\min\mathbf{e}(\mathbf{x})^{\intercal}\mathbf{\Omega}\mathbf{e}(\mathbf{x})
\end{aligned}
\end{equation}
단일 에러가 아닌 모든 에러를 더하여 표현하면 다음과 같고 이를 에러 함수 $\mathbf{E}$ 라고 한다. 실제 최적화 문제에서는 단일 에러 $\mathbf{e}_{i}$가 아닌 에러 함수 $\mathbf{E}$를 최소화하는 $\mathbf{x}^{*}$를 찾는다.
\begin{equation}
\boxed { \begin{aligned}
\mathbf{E}(\mathbf{x}) & = \sum_{i}\mathbf{e}_{i} (\mathbf{x}) ^{\intercal}\mathbf{\Omega}_{i}\mathbf{e}_{i} (\mathbf{x}) \\
\mathbf{x}^{*} & = \arg\min \mathbf{E}(\mathbf{x})
\end{aligned} }
\end{equation}
2.3. Non-linear least squares
최종적으로 풀어야 하는 최적화 수식은 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{x}^{*} = \arg\min \mathbf{E}(\mathbf{x}) = \arg\min \sum_{i}\mathbf{e}_{i} (\mathbf{x}) ^{\intercal}\mathbf{\Omega}_{i}\mathbf{e}_{i} (\mathbf{x})
\end{aligned}
\end{equation}
위 공식에서 에러를 최소화하는 최적 파라미터 $\mathbf{x}^{*}$를 찾아야 한다. 하지만 위 공식은 SLAM에서 일반적으로 회전에 대한 비선형 항을 포함하므로 closed-form solution이 존재하지 않는다. 따라서 비선형 최적화 방법 (Gauss-Newton (GN), Levenberg-Marquardt (LM))을 사용하여 문제를 풀어야 한다.
실제 SLAM의 최적화 수식을 유도하는 과정은 크게 두 방법이 존재한다. 첫 번째로 앞서 설명한 것처럼 MLE를 통해 information matrix를 고려하여 $\mathbf{e}_{i}^{\intercal}\boldsymbol{\Omega}_{i}\mathbf{e}_{i}$ 수식을 최적화하는 방법이 있고 두 번째 방법은 확률을 고려하지 않고 최소제곱법 형태로 나타내어 information matrix가 없는 $\mathbf{e}_{i}^{\intercal}\mathbf{e}_{i}$ 수식을 최적화를 수행하는 방법이 있다. 본 포스트에서는 확률을 고려한 MLE 방법에 대해 설명한다.
예를 들어, GN 방법을 사용해서 해당 문제를 푼다고 가정해보자. 문제를 푸는 순서는 다음과 같다.
- 에러함수를 정의한다
- 테일러 전개로 근사 선형화한다
- 1차 미분 후 0으로 설정한다.
- 이 때 값을 구하고 이를 에러함수에 대입한다
- 값이 수렴할 때 까지 반복한다.
에러함수 $\mathbf{e}$를 자세히 나타내면 $\mathbf{e}(\mathbf{x})$와 같고 이는 로봇의 포즈 벡터 $\mathbf{x}$에 따라 에러함수의 값이 달라지는 것을 의미한다. GN 방법은 $\mathbf{e}(\mathbf{x})$에 반복적(iterative)으로 에러가 감소하는 방향으로 증분량 $\Delta \mathbf{x}$를 업데이트한다.
\begin{equation}
\begin{aligned}
\mathbf{e}(\mathbf{x}+\Delta \mathbf{x})^{\intercal}\Omega\mathbf{e}(\mathbf{x}+\Delta \mathbf{x})
\end{aligned}
\end{equation}
이 때, $\mathbf{e}(\mathbf{x}+\Delta \mathbf{x})$를 $\mathbf{x}$ 부근에서 1차 테일러 전개를 사용하면 위 식은 다음과 같이 근사된다.
\begin{equation}
\begin{aligned}
\mathbf{e}(\mathbf{x} + \Delta \mathbf{x}) \rvert_{\mathbf{x}} & \approx \mathbf{e}(\mathbf{x}) + \mathbf{J}(\mathbf{x} + \Delta \mathbf{x} - \mathbf{x})\\
& = \mathbf{e}(\mathbf{x}) + \mathbf{J}\Delta \mathbf{x}
\end{aligned}
\end{equation}
이 때, $\mathbf{J} = \frac{\partial \mathbf{e}(\mathbf{x} + \Delta \mathbf{x})}{\partial \mathbf{x}}$이다. 이를 에러함수 전체에 적용하면 아래와 같다.
\begin{equation}
\begin{aligned}
\mathbf{e}(\mathbf{x}+\Delta \mathbf{x})^{\intercal}\Omega\mathbf{e}(\mathbf{x}+\Delta \mathbf{x}) \approx (\mathbf{e}(\mathbf{x})+\mathbf{J}\Delta \mathbf{x})^{\intercal}\Omega
(\mathbf{e}(\mathbf{x})+\mathbf{J}\Delta \mathbf{x})
\end{aligned}
\end{equation}
위 식을 전개한 후 치환하면 아래와 같다.
\begin{equation}
\begin{aligned}
& = \underbrace{\mathbf{e}^{\intercal}\Omega\mathbf{e}}_{\mathbf{c}} + 2 \underbrace{\mathbf{e}^{\intercal}\Omega\mathbf{J}}_{\mathbf{b}} \Delta \mathbf{x} + \Delta \mathbf{x}^{\intercal} \underbrace{\mathbf{J}^{\intercal}\Omega\mathbf{J}}_{\mathbf{H}} \Delta \mathbf{x} \\
& = \mathbf{c}+ 2\mathbf{b}\Delta \mathbf{x} + \Delta \mathbf{x}^{\intercal} \mathbf{H} \Delta \mathbf{x}
\end{aligned}
\end{equation}
위 전체 에러에 적용하면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{E}(\mathbf{x}+\Delta \mathbf{x}) = \sum_{i}\mathbf{e}_{i}(\mathbf{x})^{\intercal}\Omega_{i}\mathbf{e}_{i}(\mathbf{x}) = \mathbf{c}+ 2\mathbf{b}\Delta \mathbf{x} + \Delta \mathbf{x}^{\intercal} \mathbf{H} \Delta \mathbf{x}
\end{aligned}
\end{equation}
$\mathbf{E}(\mathbf{x}+\Delta \mathbf{x})$은 $\Delta \mathbf{x}$에 대한 2차식(Quadratic) 형태이고 $\mathbf{H} = \mathbf{J}^{\intercal}\Omega \mathbf{J}$는 positive definite 행렬이므로 $\mathbf{E}(\mathbf{x} + \Delta \mathbf{x})$를 1차 미분하여 0으로 설정한 값이 $\Delta \mathbf{x}$의 극소가 된다.
\begin{equation}
\begin{aligned}
\frac{\partial \mathbf{E}(\mathbf{x}+\Delta \mathbf{x})}{\partial \Delta \mathbf{x}} \approx 2\mathbf{b} + 2\mathbf{H} \Delta \mathbf{x} = 0
\end{aligned}
\end{equation}
이를 정리하면 다음과 같은 공식이 도출된다.
\begin{equation}
\begin{aligned}
\mathbf{H}\Delta \mathbf{x} = - \mathbf{b}
\end{aligned}
\end{equation}
이렇게 구한 $\Delta \mathbf{x} = -\mathbf{H}^{-1}\mathbf{b}$를 $\mathbf{x}$에 업데이트해준다.
\begin{equation}
\begin{aligned}
\mathbf{x} \leftarrow \mathbf{x} + \Delta \mathbf{x}
\end{aligned}
\end{equation}
지금까지 과정을 반복적(iterative)으로 수행하는 알고리즘을 Gauss-Newton 방법이라고 한다. LM 방법은 GN 방법과 비교했을 때 전체적인 프로세스는 동일하나 증분량을 구하는 공식에서 damping factor $\lambda$항이 추가된다.
\begin{equation}
\boxed{ \begin{aligned}
& \text{(GN) }\mathbf{H}\Delta \mathbf{x} = - \mathbf{b} \\
& \text{(LM) }(\mathbf{H} + \lambda \mathbf{I})\Delta \mathbf{x} = - \mathbf{b}
\end{aligned} }
\end{equation}
3. Reprojection error
Reprojection 에러는 feature-based Visual SLAM에서 주로 사용되는 에러이다. 주로 feature-based method 기반의 visual odometry(VO) 또는 bundle adjustment(BA)를 수행할 때 사용된다. BA에 대한 자세한 내용은 [SLAM] Bundle Adjustment 개념 리뷰 포스트를 참조하면 된다.
NOMENCLATURE of reprojection error
- $\tilde{\mathbf{p}} = \pi_{h}(\cdot) : \begin{bmatrix} X' \\ Y' \\ Z' \\1 \end{bmatrix} \rightarrow \begin{bmatrix} X'/Z' \\ Y'/Z' \\ 1 \end{bmatrix} = \begin{bmatrix} \tilde{u} \\ \tilde{v} \\ 1 \end{bmatrix}$
- 이미지 평면에 프로젝션하기 위해 3차원 공간 상의 점 $\mathbf{X}'$를 non-homogeneous 변환한 점
- $\hat{\mathbf{p}} = \pi_{k}(\cdot) = \tilde{\mathbf{K}} \tilde{\mathbf{p}} = \begin{bmatrix} f & 0 & c_{x} \\ 0 & f & c_{y} \end{bmatrix} \begin{bmatrix} \tilde{u} \\ \tilde{v} \\ 1 \end{bmatrix}= \begin{bmatrix} f\tilde{u} + c_{x} \\ f\tilde{v} + c_{y} \end{bmatrix} = \begin{bmatrix} u \\ v \end{bmatrix}$
- 렌즈 왜곡을 보정한 후 이미지 평면에 프로젝션한 점. 만약 왜곡 보정이 입력 단계에서 이미 수행된 경우 $\pi_{k}(\cdot) = \tilde{\mathbf{K}}(\cdot)$이 된다.
- $\mathbf{K} = \begin{bmatrix} f & 0 & c_{x} \\ 0 & f & c_{y} \\ 0 & 0 & 1 \end{bmatrix}$: 카메라 내부(intrinsic) 파라미터
- $\tilde{\mathbf{K}} = \begin{bmatrix} f & 0 & c_{x} \\ 0 & f & c_{y} \end{bmatrix}$: $\mathbb{P}^{2} \rightarrow \mathbb{R}^{2}$로 프로젝션하기 위해 내부 파라미터의 마지막 행을 생략했다.
- $\mathcal{X} = [\mathcal{T}_{1}, \cdots, \mathcal{T}_{m}, \mathbf{X}_{1}, \cdots, \mathbf{X}_{n}]^{\intercal}$: 모델의 상태변수
- $m$ : 카메라 포즈의 개수
- $n$: 3차원 점의 개수
- $\mathcal{T}_{i} = [\mathbf{R}_{i}, \mathbf{t}_{i}]$
- $\mathbf{e}_{ij} = \mathbf{e}_{ij}(\mathcal{X})$: 간략한 표기를 위해 $\mathcal{X}$ 생략하기도 한다
- $\mathbf{p}_{ij}$: 관측된(observed) 특정짐의 픽셀 좌표
- $\hat{\mathbf{p}}_{ij}$: 예측된(estimated) 특징점의 픽셀 좌표
- $\mathbf{T}_{i}\mathbf{X}_{j}$: Transformation, 3차원 점 $\mathbf{X}_{j}$를 카메라 좌표계 $\{i\}$로 변환, $\bigg( \mathbf{T}_{i}\mathbf{X}_{j} = \begin{bmatrix} \mathbf{R}_{i} \mathbf{X}_{j} + \mathbf{t}_{i} \\ 1 \end{bmatrix} \in \mathbb{R}^{4\times1} \bigg)$
- $\mathbf{X}' = \mathbf{TX} = [X', Y', Z',1]^{\intercal} = [\tilde{\mathbf{X}}', 1]^{\intercal} $
- $\oplus$ : SO(3) 회전행렬 $\mathbf{R}$과 3차원 벡터 $\mathbf{t}, \mathbf{X}$를 한 번에 업데이트할 수 있는 연산자.
- $\mathbf{J} = \frac{\partial \mathbf{e}}{\partial \mathcal{X}} = \frac{\partial \mathbf{e}}{\partial [\mathcal{T}, \mathbf{X}]}$
- $\mathbf{w} = \begin{bmatrix} w_{x}&w_{y}&w_{z} \end{bmatrix}^{\intercal}$: 각속도
- $[\mathbf{w}]_{\times} = \begin{bmatrix} 0 & -w_{z} & w_{y} \\ w_{z} & 0 & -w_{x} \\ -w_{y} & w_{x} & 0 \end{bmatrix}$ : 각속도 $\mathbf{w}$의 반대칭 행렬
- $\text{Exp}(\mathbf{w}) = \exp([\mathbf{w}]_{\times})$
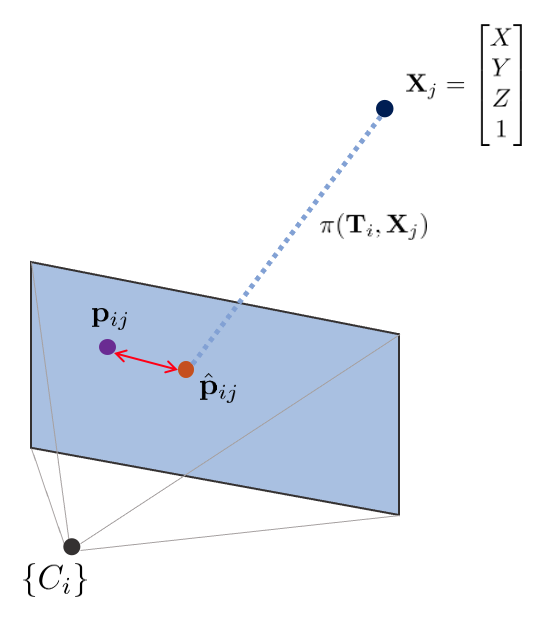
i번째 핀홀카메라 $\{C_{i}\}$의 포즈 $\mathbf{T}_{i}$와 j번째 월드 상의 한 점 $\mathbf{X}_{j}$가 있을 때 $\mathbf{X}_{j}$는 다음과 같은 변환을 통해 이미지 평면 상에 투영된다.
\begin{equation} \begin{aligned} \text{projection model: }\quad\hat{\mathbf{p}}_{ij} = \pi(\mathbf{T}_{i}, \mathbf{X}_{j}) \end{aligned} \end{equation}

위와 같이 카메라 내부/외부(intrinsic/extrinsic) 파라미터를 활용한 모델을 projection model이라고 한다. 이를 통한 reprojection 에러는 다음과 같이 정의한다.
\begin{equation}
\boxed{
\begin{aligned}
\mathbf{e}_{ij}(\mathcal{X}) & = \mathbf{p}_{ij} - \hat{\mathbf{p}}_{ij} \\
& = \mathbf{p}_{ij} - \pi(\mathbf{T}_{i}, \mathbf{X}_{j}) \\
& = \mathbf{p}_{ij} - \pi_{k}(\pi_{h}(\mathbf{T}_{i}\mathbf{X}_{j}))
\end{aligned} } \label{eq:reproj1}
\end{equation}
모든 카메라 포즈, 3차원 점들에 대한 에러 함수는 다음과 같이 정의된다.
\begin{equation}
\begin{aligned}
\mathbf{E}(\mathcal{X}) & = \sum_{i}\sum_{j} \left\| \mathbf{e}_{ij}(\mathcal{X}) \right\|^{2} \\
\end{aligned}
\end{equation}
\begin{equation}
\begin{aligned}
\mathcal{X}^{*} & = \arg\min_{\mathcal{X}^{*}} \mathbf{E}(\mathcal{X}) \\
& = \arg\min_{\mathcal{X}^{*}} \sum_{i}\sum_{j} \left\| \mathbf{e}_{ij}(\mathcal{X}) \right\|^{2} \\
& = \arg\min_{\mathcal{X}^{*}} \sum_{i}\sum_{j} \mathbf{e}_{ij}(\mathcal{X})^{\intercal}\mathbf{e}_{ij}(\mathcal{X})\\
& = \arg\min_{\mathcal{X}^{*}} \sum_{i}\sum_{j} (\mathbf{p}_{ij} - \hat{\mathbf{p}}_{ij})^{\intercal}(\mathbf{p}_{ij} - \hat{\mathbf{p}}_{ij})
\end{aligned} \label{eq:10}
\end{equation}
$\mathbf{E}(\mathcal{X}^{*})$를 만족하는 $\left\|\mathbf{e}(\mathcal{X}^{*})\right\|^{2}$를 non-linear least squares를 통해 반복적으로 계산할 수 있다. 작은 증분량 $\Delta \mathcal{X}$를 반복적으로 $\mathcal{X}$에 업데이트함으로써 최적의 상태를 찾는다.
\begin{equation}
\begin{aligned}
\arg\min_{\mathcal{X}^{*}} \mathbf{E}(\mathcal{X} + \Delta \mathcal{X}) & = \arg\min_{\mathcal{X}^{*}} \sum_{i}\sum_{j} \left\|\mathbf{e}(\mathcal{X} +\Delta \mathcal{X})\right\|^{2}
\end{aligned}
\end{equation}
엄밀하게 말하면 상태 증분량 $\Delta \mathcal{X}$은 SO(3) 회전행렬을 포함하므로 $\oplus$ 연산자를 통해 기존 상태 $\mathcal{X}$에 더해지는게 맞지만 표현의 편의를 위해 $+$ 연산자를 사용하였다.
\begin{equation}
\begin{aligned}
\mathbf{e}( \mathcal{X} \oplus \Delta \mathcal{X})
\quad \rightarrow \quad\mathbf{e}(\mathcal{X} + \Delta \mathcal{X})
\end{aligned}
\end{equation}
위 식은 테일러 1차 근사를 통해 다음과 같이 표현이 가능하다.
\begin{equation}
\begin{aligned}
\mathbf{e}(\mathcal{X} + \Delta \mathcal{X}) & \approx \mathbf{e}(\mathcal{X}) + \mathbf{J}\Delta \mathcal{X} \\ & = \mathbf{e}(\mathcal{X}) + \mathbf{J}_{c} \Delta \mathcal{T} + \mathbf{J}_{p} \Delta \mathbf{X} \\
& = \mathbf{e}(\mathcal{X}) + \frac{\partial \mathbf{e}}{\partial \mathcal{T}} \Delta \mathcal{T} + \frac{\partial \mathbf{e}}{\partial \mathbf{X}}\Delta \mathbf{X} \\
\end{aligned}
\end{equation}
\begin{equation}
\begin{aligned}
\arg\min_{\mathcal{X}^{*}} \mathbf{E}(\mathcal{X} + \Delta \mathcal{X}) & \approx \arg\min_{\mathcal{X}^{*}} \sum_{i}\sum_{j} \left\|\mathbf{e}(\mathcal{X}) + \mathbf{J}\Delta \mathcal{X} \right\|^{2} \\
\end{aligned}
\end{equation}
이를 미분하여 최적의 증분량 $\Delta \mathcal{X}^{*}$ 값을 구하면 다음과 같다. 자세한 유도 과정은 본 섹션에서는 생략한다. 유도 과정에 대해 자세히 알고 싶으면 이전 섹션을 참조하면 된다.
\begin{equation}
\begin{aligned}
& \mathbf{J}^{\intercal}\mathbf{J} \Delta \mathcal{X}^{*} = -\mathbf{J}^{\intercal}\mathbf{e} \\
& \mathbf{H}\Delta \mathcal{X}^{*} = - \mathbf{b} \\
\end{aligned} \label{eq:6}
\end{equation}
위 식은 선형시스템 $\mathbf{Ax} = \mathbf{b}$ 형태이므로 schur complement, cholesky decomposition과 같은 다양한 선형대수학 테크닉을 사용하여 $\Delta \mathcal{X}^{*}$를 구할 수 있다. 이 때, 기존 상태 $\mathcal{X}$ 중 $\mathbf{t}, \mathbf{X}$는 선형 벡터 공간에 존재하므로 오른쪽에서 더하는 지 또는 왼쪽에서 더하는 지에 따른 차이가 없지만 회전 행렬 $\mathbf{R}$은 비선형 SO(3)군에 속하므로 오른쪽에 곱하느냐 왼쪽에 곱하느냐에 따라 각각 로컬 좌표계에서 본 포즈를 업데이트할 것 인지(오른쪽) 전역 좌표계에서 본 포즈를 업데이트할 것 인지(왼쪽) 달라지게 된다. Reprojection 에러는 전역 좌표계의 변환 행렬을 업데이트하므로 일반적으로 왼쪽 곱셈 방법을 사용한다.\begin{equation}
\begin{aligned}
\mathcal{X} \leftarrow \mathcal{X} \oplus \Delta \mathcal{X}^{*} \\
\end{aligned}
\end{equation}
$\mathcal{X}$는 $[\mathcal{T}, \mathbf{X}]$로 구성되어 있으므로 다음과 같이 풀어 쓸 수 있다.
\begin{equation}
\begin{aligned}
\mathcal{T} \leftarrow \mathcal{T} & \oplus \Delta \mathcal{T}^{*}\\
\mathbf{X} \leftarrow \mathbf{X} & \oplus \Delta \mathbf{X}^{*} \\
\end{aligned}
\end{equation}
왼쪽 곱셈 $\oplus$ 연산의 정의는 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{R} \oplus \Delta \mathbf{R}^{*} & = \Delta \mathbf{R}^{*} \mathbf{R} \\
& = \text{Exp}(\Delta \mathbf{w}^{*})\mathbf{R} \quad \cdots \text{ globally updated (left mult)} \\
\mathbf{t} \oplus \Delta \mathbf{t}^{*} & = \mathbf{t} + \Delta \mathbf{t}^{*} \\
\mathbf{X} \oplus \Delta \mathbf{X}^{*} & = \mathbf{X} + \Delta \mathbf{X}^{*}
\end{aligned} \label{eq:1}
\end{equation}
3.1. Jacobian of the reprojection error
3.1.1. Jacobian of camera pose
포즈에 대한 자코비안 $\mathbf{J}_{c}$은 다음과 같이 분해할 수 있다.
\begin{equation} \begin{aligned} \mathbf{J}_{c} = \frac{\partial \mathbf{e}}{\partial \mathcal{T}} & = \frac{\partial}{\partial \mathcal{T}}(\mathbf{p} - \hat{\mathbf{p}}) \\ & = \frac{\partial }{\partial \mathcal{T}} \bigg(\mathbf{p} - \pi_{k}(\pi_{h}(\mathbf{T}_{i} \mathbf{X}_{j})) \bigg ) \\ & = \frac{\partial}{\partial \mathcal{T}} \bigg(-\pi_{k}(\pi_{h}(\mathbf{T}_{i} \mathbf{X}_{j})) \bigg ) \end{aligned} \end{equation}
Chain rule을 사용하여 위 식을 정리하면 다음과 같다. 이 때, 편의를 위해 $\mathbf{T}_{i}\mathbf{X}_{j} \rightarrow \mathbf{X}' $로 표기한다.
\begin{equation}
\begin{aligned}
\mathbf{J}_{c}& = \frac{\partial \hat{\mathbf{p}}}{\partial \tilde{\mathbf{p}}}
\frac{\partial \tilde{\mathbf{p}}}{\partial \mathbf{X}'}
\frac{\partial \mathbf{X}'}{\partial [\mathbf{w}, \mathbf{t}]} \\
& = \mathbb{R}^{2 \times 3} \cdot \mathbb{R}^{3\times 4} \cdot \mathbb{R}^{4 \times 6} = \mathbb{R}^{2 \times 6}
\end{aligned} \label{eq:2}
\end{equation}
이 때, 회전행렬 $\mathbf{R}$에 대한 자코비안 $\frac{\partial \mathbf{X}'}{\partial \mathbf{R}}$을 구하는 것이 아닌 각속도 $\mathbf{w}$에 대한 자코비안 $\frac{\partial \mathbf{X}'}{\partial \mathbf{w}}$을 구하는 이유는 다음 섹션에서 설명한다.또한 에러를 $\mathbf{p} - \hat{\mathbf{p}}$로 정의하느냐 $\hat{\mathbf{p}} - \mathbf{p}$로 정의하느냐에 따라 $\mathbf{J}_{c}$의 부호 또한 변경되므로 이는 실제 코드로 구현할 때 유의하여 적용해야 한다. 해당 자료에서는 부호는 $+$로 간주하고 표기하였다.
렌즈에 의한 왜곡(distortion)은 일반적으로 계산의 복잡성으로 인해 자코비안 계산 시 고려하지 않는다. 또한 렌즈 왜곡 보정(undistortion)이 이미지 입력 과정에서 이미 수행되었다고 가정하면 이를 고려할 필요가 없어진다.
따라서 $\frac{\partial \hat{\mathbf{p}}}{\partial \tilde{\mathbf{p}}}$은 다음과 같이 단순히 카메라 내부 행렬 $\mathbf{K}$를 곱하는 것으로 구할 수 있다. 아래 수식에서는 마지막 행 $[0\ 0\ 1]$을 생략한 $\tilde{\mathbf{K}}$가 사용되었다.
\begin{equation}
\boxed{
\begin{aligned}
\frac{\partial \hat{\mathbf{p}}}{\partial \tilde{\mathbf{p}}} & =
\frac{\partial }{\partial \tilde{\mathbf{p}}} \tilde{\mathbf{K}} \tilde{\mathbf{p}} \\
& = \tilde{\mathbf{K}} \\
& = \begin{bmatrix} f & 0 & c_{x} \\ 0 & f & c_{y} \end{bmatrix} \in \mathbb{R}^{2 \times 3}
\end{aligned} }
\end{equation}
다음으로 $\frac{\partial \tilde{\mathbf{p}}}{\partial \mathbf{X}'}$은 다음과 같다.
\begin{equation}
\boxed{
\begin{aligned}
\frac{\partial \tilde{\mathbf{p}}}{\partial \mathbf{X}'} & =
\frac{\partial [\tilde{u}, \tilde{v}, 1]}{\partial [X', Y', Z',1]} \\
& = \begin{bmatrix} \frac{1}{Z'} & 0 & \frac{-X'}{Z'^{2}} & 0 \\
0 & \frac{1}{Z'} & \frac{-Y'}{Z'^{2}} & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix} \in \mathbb{R}^{3\times 4}
\end{aligned} }
\end{equation}
다음으로 $\frac{\partial \mathbf{X}'}{\partial \mathbf{t}}$를 구해야 한다. 이는 다음과 같이 비교적 간단하게 구할 수 있다.
\begin{equation}
\boxed{
\begin{aligned}
\frac{\partial \mathbf{X}'}{\partial \mathbf{t}} & = \frac{\partial }{\partial [t_{x}, t_{y}, t_{z}]} \begin{bmatrix} \mathbf{R}\mathbf{X} + \mathbf{t} \\ 1 \end{bmatrix} \\
& = \frac{\partial }{\partial [t_{x}, t_{y}, t_{z}]} \begin{bmatrix} \mathbf{t} \\ 1 \end{bmatrix} \\
& = \frac{\partial }{\partial [t_{x}, t_{y}, t_{z}]}(\begin{bmatrix} t_{x} \\ t_{y} \\ t_{z} \\ 1 \end{bmatrix}) \\
& = \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \end{bmatrix} \in \mathbb{R}^{4\times 3}
\end{aligned} }
\end{equation}
3.1.2. Lie theory-based SO(3) optmization
마지막으로 $\frac{\partial \mathbf{X}'}{\partial \mathbf{w}}$를 구해야 한다. 이 때, 회전 관련 파라미터를 회전행렬 $\mathbf{R}$이 아닌 각속도 $\mathbf{w}$로 표현하였다. 회전행렬 $\mathbf{R}$은 파라미터의 개수가 9개인 반면에 실제 회전에는 3개의 자유도로 제한되므로 over-parameterized 되었다. over-parameterized 표현법의 단점은 다음과 같다.
- 중복되는 파라미터를 계산해야 하기 때문에 최적화 수행 시 연산량이 증가한다.
- 추가적인 자유도로 인해 수치적인 불안정성(numerical instability) 문제가 야기될 수 있다.
- 파라미터가 업데이트될 때마다 항상 제약조건을 만족하는 지 체크해줘야 한다.
lie theory를 사용하면 제약조건으로부터 자유롭게 최적화를 수행할 수 있다. 따라서 lie group SO(3) $\mathbf{R}$ 대신 lie algebra so(3) $[\mathbf{w}]_{\times}$을 사용하여 제약조건으로부터 자유롭게 파라미터를 업데이트할 수 있게 된다. 이 때, $\mathbf{w} \in \mathbb{R}^{3}$는 각속도 벡터를 의미한다.
\begin{equation}
\begin{aligned}
\frac{\partial \mathbf{e}}{\partial [\mathbf{R}, \mathbf{t}]} \rightarrow \frac{\partial \mathbf{e}}{\partial [\mathbf{w}, \mathbf{t}]} \\
\end{aligned}
\end{equation}
하지만 $\mathbf{X}'$에서 $\mathbf{w}$이 바로 보이지 않으므로 $\mathbf{X}'$를 lie algebra로 표현해야 한다. 이 때, 회전과 관련된 $\mathbf{w}$ 항에 대한 자코비안을 구해야 하므로 3차원 점 $\mathbf{X}_{t}$를 $\mathbf{X}$가 $\mathbf{t}$만큼 병진 이동한 후, $\mathbf{X}'$를 동일한 위치의 $\mathbf{X}_{t}$가 $\mathbf{R}$만큼 회전한 점이라고 하자.
\begin{equation} \begin{aligned} \mathbf{X}_{t} & = \mathbf{X} + \mathbf{t} \\ \mathbf{X}' & = \mathbf{R}\mathbf{X}_{t} \\ & = \text{Exp}(\mathbf{w})\mathbf{X}_{t} \end{aligned} \end{equation}
$\text{Exp}(\mathbf{w}) \in SO(3)$는 각속도 $\mathbf{w}$를 exponential mapping하여 3차원 회전행렬 $\mathbf{R}$로 변환하는 연산을 말한다. exponential mapping에 대한 자세한 내용은 해당 링크를 참조하면 된다. \begin{equation} \begin{aligned} \text{Exp}(\mathbf{w}) = \mathbf{R} \end{aligned} \end{equation}
이 때, 작은 lie algebra 증분량 $\Delta \mathbf{w}$를 기존 $\text{Exp}(\mathbf{w})$에 업데이트하는 방식에 따라 두 가지 방법으로 나뉘게 된다. 우선 $[1]$ 기본적인 lie algebra를 사용한 업데이트 방법이 있다. 다음으로 $[2]$ 섭동(perturbation) 모델을 활용한 업데이트 방법이 있다.
\begin{equation}
\begin{aligned}
\text{Exp}(\mathbf{w}) & \leftarrow \text{Exp}(\mathbf{w} + \Delta \mathbf{w}) \quad \cdots \text{[1]} \\
\text{Exp}(\mathbf{w}) & \leftarrow \text{Exp}(\Delta \mathbf{w}) \text{Exp}(\mathbf{w}) \quad \cdots \text{[2]}
\end{aligned}
\end{equation}
위 두 방법 사이에는 다음과 같은 관계가 존재한다. 자세한 내용은 해당 링크의 4.3.3 챕터를 참조하면 된다. \begin{equation} \begin{aligned} & \text{Exp}(\Delta \mathbf{w}) \text{Exp}(\mathbf{w}) = \text{Exp}(\mathbf{w}+ \mathbf{J}_{l}^{-1}\Delta \mathbf{w} ) \\ & \text{Exp}(\mathbf{w}+ \Delta \mathbf{w} ) = \text{Exp}(\mathbf{J}_{l} \Delta \mathbf{w}) \text{Exp}(\mathbf{w}) \end{aligned} \end{equation}
$[1]$ Lie algebra-based update: 우선 $[1]$ 방법을 사용해서 자코비안 $\frac{\partial \mathbf{R}\mathbf{X}_{t} }{\partial \mathbf{w}}$를 바로 계산하면 다음과 같은 복잡한 식이 유도된다.
\begin{equation} \boxed{ \begin{aligned}
\frac{\partial \mathbf{R}\mathbf{X}_{t} }{\partial \mathbf{w}} & = \lim_{\Delta \mathbf{w} \rightarrow 0} \frac{\text{Exp}(\mathbf{w} + \Delta \mathbf{w}) \mathbf{X}_{t} - \text{Exp}(\mathbf{w}) \mathbf{X}_{t} }{\Delta \mathbf{w}} \\
& \approx \lim_{\Delta \mathbf{w} \rightarrow 0} \frac{ \text{Exp}(\mathbf{J}_{l}\Delta \mathbf{w}) \text{Exp}(\mathbf{w}) \mathbf{X}_{t} - \text{Exp}(\mathbf{w}) \mathbf{X}_{t} }{\Delta \mathbf{w}} \\
& \approx \lim_{\Delta \mathbf{w} \rightarrow 0} \frac{(\mathbf{I} + [\mathbf{J}_{l} \Delta \mathbf{w}]_{\times}) \text{Exp}(\mathbf{w})\mathbf{X}_{t} - \text{Exp}(\mathbf{w})\mathbf{X}_{t}}{\Delta \mathbf{w}} \\
& = \lim_{\Delta \mathbf{w} \rightarrow 0} \frac{[\mathbf{J}_{l}\Delta \mathbf{w}]_{\times} \mathbf{R}\mathbf{X}_{t} }{\Delta \mathbf{w}} \quad \quad (\because \text{Exp}(\mathbf{w})\mathbf{X}_{t} = \mathbf{R}\mathbf{X}_{t}) \\
& = \lim_{\Delta \mathbf{w} \rightarrow 0} \frac{-[\mathbf{R}\mathbf{X}_{t}]_{\times} \mathbf{J}_{l}\Delta \mathbf{w}}{\Delta \mathbf{w}} \\
& = -[\mathbf{R}\mathbf{X}_{t}]_{\times} \mathbf{J}_{l} \\ & = -[\mathbf{X}']_{\times} \mathbf{J}_{l}
\end{aligned} } \end{equation}
위 식에서 두 번째 행은 BCH 근사를 사용하여 왼쪽 자코비안(left jacobian) $\mathbf{J}_{l}$이 유도된 형태이고 세 번째 행은 작은 회전량 $\text{Exp}(\mathbf{J}_{l} \Delta \mathbf{w})$에 대해 1차 테일러 근사가 적용된 형태이다. $\mathbf{J}_{l}$에 대한 자세한 내용은 Lie theory 개념 리뷰 포스팅을 참조하면 된다.
세 번째 행의 근사를 이해하기 위해 임의의 회전 벡터 $\mathbf{w} = [w_{x}, w_{y}, w_{z}]^{\intercal}$가 주어졌을 때 회전행렬을 exponential mapping 형태로 전개하면 다음과 같이 나타낼 수 있다. \begin{equation} \begin{aligned} \mathbf{R} & = \text{Exp}(\mathbf{w}) \\ & = \exp([\mathbf{w}]_{\times}) \\ & = \mathbf{I} + [\mathbf{w}]_{\times} + \frac{1}{2}[\mathbf{w}]_{\times}^{2} + \frac{1}{3!}[\mathbf{w}]_{\times}^{3} + \frac{1}{4!}[\mathbf{w}]^{4}_{\times} + \cdots \end{aligned} \end{equation}
작은 크기의 회전행렬 $\Delta \mathbf{R}$에 대해서는 2차 이상의 고차항을 무시하여 다음과 같이 근사적으로 나타낼 수 있다. \begin{equation} \begin{aligned} \Delta \mathbf{R} \approx \mathbf{I} + [\Delta \mathbf{w}]_{\times} \end{aligned} \end{equation}
$[2]$ Perturbation model-based update: $\mathbf{J}_{l}$을 사용하지 않고 보다 간단한 자코비안을 구하기 위해 $[2]$ lie algebra so(3)의 섭동(perturbation) 모델을 일반적으로 사용한다. 섭동 모델을 사용하여 자코비안 $\frac{\partial \mathbf{R}\mathbf{X}_{t}}{\partial \Delta \mathbf{w}}$를 구하면 다음과 같다.
\begin{equation} \boxed{ \begin{aligned}
\frac{\partial \mathbf{R}\mathbf{X}_{t}}{\partial \Delta \mathbf{w}} & = \lim_{\Delta \mathbf{w} \rightarrow 0} \frac{\text{Exp}(\Delta \mathbf{w}) \text{Exp}(\mathbf{w}) \mathbf{X}_{t} - \text{Exp}(\mathbf{w}) \mathbf{X}_{t} }{\Delta \mathbf{w}} \\
& \approx \lim_{\Delta \mathbf{w} \rightarrow 0} \frac{(\mathbf{I} + [\Delta \mathbf{w}]_{\times}) \text{Exp}(\mathbf{w}) \mathbf{X}_{t} - \text{Exp}(\mathbf{w}) \mathbf{X}_{t}}{\Delta \mathbf{w}} \\
& = \lim_{\Delta \mathbf{w} \rightarrow 0} \frac{[\Delta \mathbf{w}]_{\times} \mathbf{R}\mathbf{X}_{t}}{\Delta \mathbf{w}} \quad \quad (\because \text{Exp}(\mathbf{w})\mathbf{X}_{t} = \mathbf{R}\mathbf{X}_{t}) \\
& = \lim_{\Delta \mathbf{w} \rightarrow 0} \frac{-[\mathbf{R}\mathbf{X}_{t}]_{\times} \Delta \mathbf{w}}{\Delta \mathbf{w}} \\
& = -[\mathbf{R}\mathbf{X}_{t}]_{\times} \\ & = -[\mathbf{X}']_{\times} \\
\end{aligned} } \end{equation}
위 식 또한 두 번째 행에서 작은 회전행렬에 대한 근사 $\text{Exp}(\Delta \mathbf{w}) \approx \mathbf{I} + [\Delta \mathbf{w}]_{\times} $를 사용하였다. 따라서 $[2]$ 섭동 모델을 사용하는 경우 3차원 공간 상의 점 $\mathbf{X}'$의 반대칭 행렬을 사용하여 간단하게 자코비안 $\frac{\partial \mathbf{R}\mathbf{X}_{t}}{\partial \Delta \mathbf{w}}$을 구할 수 있는 이점이 있다. reprojection 에러 최적화의 경우 대부분 순차적으로 들어오는 이미지들의 특징점에 대한 에러를 최적화하므로 카메라 포즈 변화가 크지 않고 따라서 $\Delta \mathbf{w}$의 크기 또한 크지 않으므로 일반적으로 위의 자코비안 $\frac{\partial \mathbf{R}\mathbf{X}_{t}}{\partial \Delta \mathbf{w}}$을 주로 사용한다. $[2]$ 방법을 사용하므로 기존 회전행렬 $\mathbf{R}$에 작은 증분량 $\Delta \mathbf{w}$를 업데이트할 때 (\ref{eq:1}) 같이 업데이트한다.
\begin{equation}
\begin{aligned}
\mathbf{R} \leftarrow \Delta \mathbf{R}^{*} \mathbf{R} \quad \text{where, } \Delta \mathbf{R}^{*} = \text{Exp}(\Delta \mathbf{w}^{*})
\end{aligned}
\end{equation}
따라서 기존의 자코비안은 $\frac{\partial \mathbf{X}'}{\partial [\mathbf{w}, \mathbf{t}]}$에서 $\frac{\partial \mathbf{X}'}{\partial [\Delta \mathbf{w}, \mathbf{t}]}$로 변경되고 이는 다음과 같다.
\begin{equation}
\boxed{
\begin{aligned}
\frac{\partial }{\partial [\Delta \mathbf{w}, \mathbf{t}]} \begin{bmatrix} \mathbf{RX} + \mathbf{t} \\ 1 \end{bmatrix} & = \begin{bmatrix} 0 & Z' & - Y' & 1 & 0 & 0
\\ -Z' & 0 & X' & 0 & 1 & 0 \\ Y' & -X' & 0 & 0 & 0 & 1 \\ 0&0&0&0&0&0 \end{bmatrix} \in \mathbb{R}^{4 \times 6}
\end{aligned} }
\end{equation}
최종적인 포즈에 대한 자코비안 $\mathbf{J}_{c}$는 다음과 같다.
\begin{equation}
\boxed{
\begin{aligned}
\mathbf{J}_{c} & = \frac{\partial \hat{\mathbf{p}}}{\partial \tilde{\mathbf{p}}}
\frac{\partial \tilde{\mathbf{p}}}{\partial \mathbf{X}'}
\frac{\partial \mathbf{X}'}{\partial [\Delta \mathbf{w}, \mathbf{t}]} \\
& = \begin{bmatrix} f & 0 & c_{x} \\ 0 & f & c_{y} \end{bmatrix} \begin{bmatrix} \frac{1}{Z'} & 0 & \frac{-X'}{Z'^{2}} & 0 \\
0 & \frac{1}{Z'} & \frac{-Y'}{Z'^{2}} & 0 \\ 0 & 0 & 0 &0 \end{bmatrix}
\begin{bmatrix} 0 & Z' & -Y' & 1 & 0 & 0 \\
-Z' & 0 & X' & 0 & 1 & 0 \\
Y' & -X' & 0 & 0 & 0 & 1 \\ 0&0&0&0&0&0 \end{bmatrix} \\
& = \begin{bmatrix} \frac{f}{Z'} & 0 & -\frac{fX}{Z'^{2}} & 0 \\ 0 & \frac{f}{Z'} & -\frac{fY}{Z'^{2}} & 0\end{bmatrix}
\begin{bmatrix} 0 & Z' & -Y' & 1 & 0 & 0 \\ -Z' & 0 & X' & 0 & 1 & 0 \\ Y'& -X'& 0 & 0 & 0 & 1 \\ 0&0&0&0&0&0 \end{bmatrix} \\
& = \begin{bmatrix} -\frac{fX'Y'}{Z'^{2}} & \frac{f(1 + X'^{2})}{Z'^{2}} & -\frac{fY'}{Z'} & \frac{f}{Z'} & 0 & -\frac{fX'}{Z'^{2}} \\
-\frac{f(1+y^{2})}{Z'^{2}} & \frac{fX'Y'}{Z'^{2}} & \frac{fX'}{Z'} & 0 & \frac{f}{Z'} & -\frac{fY'}{Z'^{2}} \end{bmatrix} \in \mathbb{R}^{2 \times 6}
\end{aligned} }
\end{equation}
3.2. Jacobian of Map Point
3차원 점 $\mathbf{X}$에 대한 자코비안 $\mathbf{J}_{p}$은 다음과 같이 구할 수 있다.
\begin{equation}
\begin{aligned}
\mathbf{J}_{p} = \frac{\partial \mathbf{e}}{\partial \mathbf{X}} & = \frac{\partial}{\partial \mathbf{X}}(\mathbf{p} - \hat{\mathbf{p}}) \\
& = \frac{\partial}{\partial \mathbf{X}} \bigg(\mathbf{p} - \pi_{k}(\pi_{h}(\mathbf{T}_{i} \mathbf{X}_{j})) \bigg ) \\
& = \frac{\partial}{\partial \mathbf{X}} \bigg(-\pi_{k}(\pi_{h}(\mathbf{T}_{i} \mathbf{X}_{j})) \bigg ) \\
\end{aligned}
\end{equation}
Chain rule을 사용하여 위 식을 정리하면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{J}_{p}& = \frac{\partial \hat{\mathbf{p}}}{\partial \tilde{\mathbf{p}}}
\frac{\partial \tilde{\mathbf{p}}}{\partial \mathbf{X}'}
\frac{\partial \mathbf{X}'}{\partial \mathbf{X}} \\
& = \mathbb{R}^{2 \times 3} \cdot \mathbb{R}^{3\times 4} \cdot \mathbb{R}^{4 \times 4} = \mathbb{R}^{2 \times 4}
\end{aligned}
\end{equation}
이 중, $\frac{\partial \hat{\mathbf{p}}}{\partial \tilde{\mathbf{p}}} \frac{\partial \hat{\mathbf{p}}}{\partial \mathbf{X}'}$는 앞서 구한 자코비안과 동일하다. 따라서 $\frac{\partial \mathbf{X}'}{\partial \mathbf{X}}$만 계산하면 된다.
\begin{equation}
\boxed{
\begin{aligned}
\frac{\partial \mathbf{X}'}{\partial \mathbf{X}} & = \frac{\partial }{\partial \mathbf{X}} \begin{bmatrix} \mathbf{R}\mathbf{X} + \mathbf{t} \\ 1 \end{bmatrix} \\
& = \begin{bmatrix} \mathbf{R} \\ 0 \end{bmatrix}
\end{aligned} }
\end{equation}
따라서 $\mathbf{J}_{p}$는 다음과 같다.
\begin{equation}
\boxed{
\begin{aligned}
\mathbf{J}_{p} &= \frac{\partial \hat{\mathbf{p}}}{\partial \tilde{\mathbf{p}}}
\frac{\partial \tilde{\mathbf{p}}}{\partial \mathbf{X}'}
\frac{\partial \mathbf{X}'}{\partial \mathbf{X}} \\ & = \begin{bmatrix} f & 0 & c_{x} \\ 0 & f & c_{y} \end{bmatrix} \begin{bmatrix} \frac{1}{Z'} & 0 & \frac{-X'}{Z'^{2}} & 0 \\
0 & \frac{1}{Z'} & \frac{-Y'}{Z'^{2}} & 0\\ 0 & 0 & 0 & 0\end{bmatrix} \begin{bmatrix} \mathbf{R} \\ 0 \end{bmatrix} \\
& = \begin{bmatrix} \frac{f}{Z'} & 0 & -\frac{fX'}{Z'^{2}} & 0 \\ 0 & \frac{f}{Z'} & -\frac{fY'}{Z'^{2}} & 0 \end{bmatrix} \begin{bmatrix} \mathbf{R} \\ 0 \end{bmatrix} \in \mathbb{R}^{2\times 4}
\end{aligned} }
\end{equation}
일반적으로 $\mathbf{J}_{p}$의 마지막 열은 항상 0이므로 이를 생략하여 non-homogeneous 형태로 나타내기도 한다.
\begin{equation}
\boxed{
\begin{aligned}
\mathbf{J}_{p} & = \begin{bmatrix} \frac{f}{Z'} & 0 & -\frac{fX'}{Z'^{2}} \\ 0 & \frac{f}{Z'} & -\frac{fY'}{Z'^{2}} \end{bmatrix} \mathbf{R} \in \mathbb{R}^{2\times 3}
\end{aligned} }
\end{equation}
3.3. Code implementations
- g2o 코드: edge_project_xyz.cpp#L82
- g2o 코드: edge_project_xyz.cpp#L80
4. Photometric error
Phtometric 에러는 direct Visual SLAM에서 주로 사용되는 에러이다. 주로 direct method 기반의 visual odometry(VO) 또는 bundle adjustment(BA)를 수행할 때 사용된다. direct method에 대한 자세한 내용은 [SLAM] Optical Flow와 Direct Method 개념 및 코드 리뷰 포스트를 참조하면 된다.
NOMENCLATURE of photometric error
- $\tilde{\mathbf{p}}_{2} = \pi_{h}(\cdot) : \begin{bmatrix} X' \\ Y' \\ Z' \\1 \end{bmatrix} \rightarrow \begin{bmatrix} X'/Z' \\ Y'/Z' \\ 1 \end{bmatrix} = \begin{bmatrix} \tilde{u}_{2} \\ \tilde{v}_{2} \\ 1 \end{bmatrix}$
- 이미지 평면에 프로젝션하기 위해 3차원 공간 상의 점 $\mathbf{X}'$를 non-homogeneous 변환한 점
- $\mathbf{p}_{2} = \pi_{k}(\cdot) = \tilde{\mathbf{K}} \tilde{\mathbf{p}}_{2} = \begin{bmatrix} f & 0 & c_{x} \\ 0 & f & c_{y} \end{bmatrix} \begin{bmatrix} \tilde{u}_{2} \\ \tilde{v}_{2} \\ 1 \end{bmatrix}= \begin{bmatrix} f\tilde{u} + c_{x} \\ f\tilde{v} + c_{y} \end{bmatrix} = \begin{bmatrix} u_{2} \\ v_{2} \end{bmatrix}$
- 렌즈 왜곡을 보정한 후 이미지 평면에 프로젝션한 점. 만약 왜곡 보정이 입력 단계에서 이미 수행된 경우 $\pi_{k}(\cdot) = \tilde{\mathbf{K}}(\cdot)$이 된다.
- $\mathbf{K} = \begin{bmatrix} f & 0 & c_{x} \\ 0 & f & c_{y} \\ 0 & 0 & 1 \end{bmatrix}$: 카메라 내부(intrinsic) 파라미터
- $\tilde{\mathbf{K}} = \begin{bmatrix} f & 0 & c_{x} \\ 0 & f & c_{y} \end{bmatrix}$: $\mathbb{P}^{2} \rightarrow \mathbb{R}^{2}$로 프로젝션하기 위해 내부 파라미터의 마지막 행을 생략했다.
- $\mathcal{P}$: 이미지 내의 모든 특징점들의 집합
- $\mathbf{e}(\mathbf{T}) \rightarrow \mathbf{e}$: 일반적으로 표기를 생략하여 간단하게 나타내기도 한다.
- $\mathbf{p}^{i}_{1}, \mathbf{p}^{i}_{2}$: 첫번째 이미지와 두번째 이미지에서 i번째 특징점의 픽셀 좌표
- $\oplus$ : 두 SE(3) 군을 결합(composition)하는 연산자
- $\mathbf{J} = \frac{\partial \mathbf{e}}{\partial \mathbf{T}} = \frac{\partial \mathbf{e}}{\partial [\mathbf{R}, \mathbf{t}]}$
- $\mathbf{X}' = [X,Y,Z,1]^{\intercal} = [\tilde{\mathbf{X'}}, 1]^{\intercal} = \mathbf{TX}$
- $\mathbf{T}\mathbf{X}$: Transformation, 3차원 점 $\mathbf{X}$를 카메라 좌표계로 변환, $\bigg( \mathbf{T}\mathbf{X} = \begin{bmatrix} \mathbf{R} \mathbf{X} + \mathbf{t} \\ 1 \end{bmatrix} \in \mathbb{R}^{4\times1} \bigg)$
- $\mathbf{X}' = [X',Y',Z',1]^{\intercal} = [\tilde{\mathbf{X}}', 1]^{\intercal}$
- $\xi = [\mathbf{w}, \mathbf{v}]^{\intercal} = [w_{x}, w_{y}, w_{z}, v_{x}, v_{y}, v_{z}]^{\intercal}$: 3차원 각속도와 속도로 구성된 벡터. twist라고 불린다.
- $[\xi]_{\times} = \begin{bmatrix} [\mathbf{w}]_{\times} & \mathbf{v} \\ \mathbf{0}^{\intercal} & 0 \end{bmatrix} \in \text{se}(3)$ : hat 연산자가 적용된 twist의 lie algebra (4x4 행렬)
- $\text{Exp}(\xi) = \exp([\xi]_{\times})$
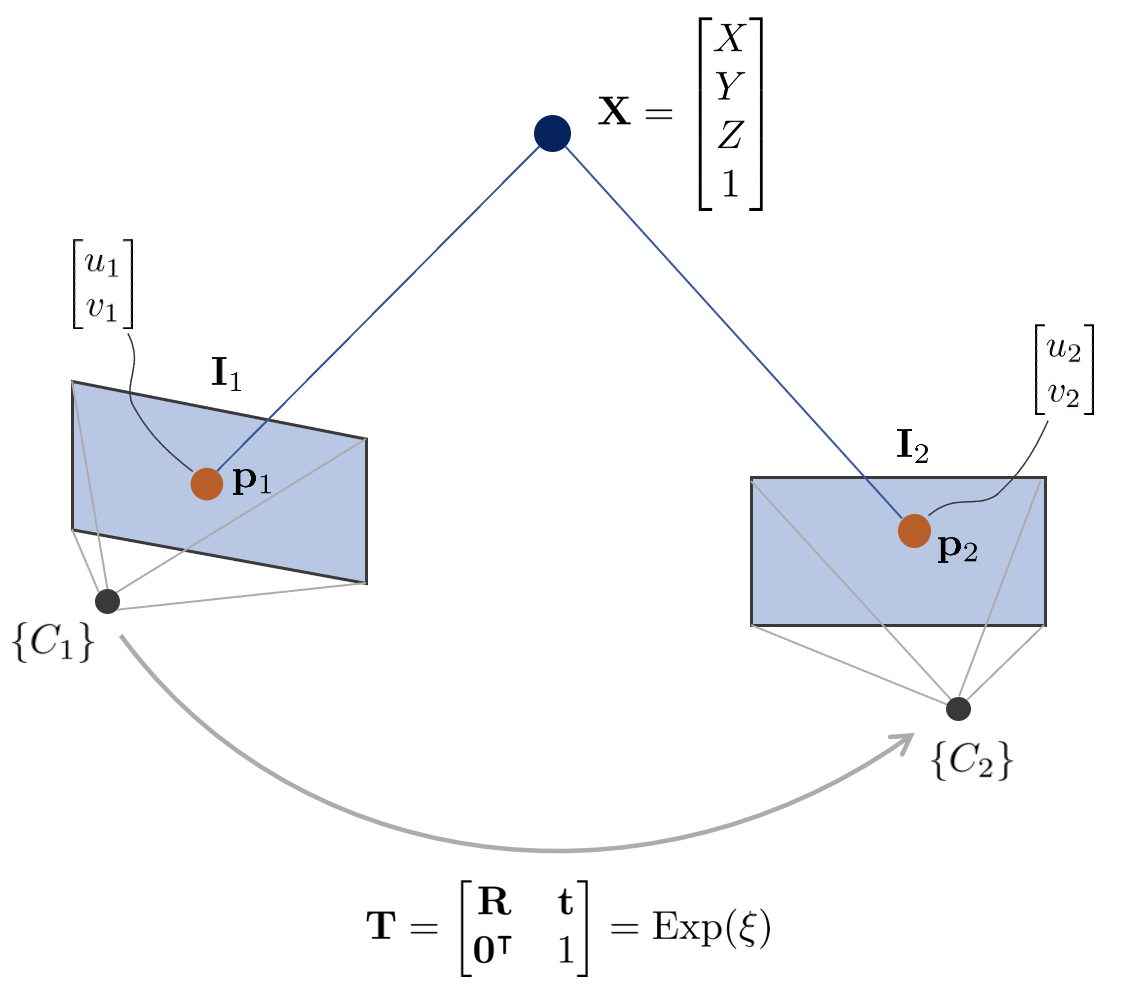
위 그림에서 3차원 점 $\mathbf{X}$의 월드 좌표는 $[X,Y,Z,1]^{\intercal} \in \mathbb{P}^{3}$이고 이에 대응하는 두 카메라 이미지 평면 상의 픽셀 좌표는 $\mathbf{p}_{1}, \mathbf{p}_{2} \in \mathbb{P}^{2}$이다. 이 때, 두 카메라 $\{C_{1}\}, \{C_{2}\}$의 내부 파라미터 $\mathbf{K}$는 동일하다고 가정한다. 카메라 $\{C_{1}\}$을 원점($\mathbf{R} = \mathbf{I}, \mathbf{t} = \mathbf{0}$)이라고 했을 때 픽셀 좌표 $\mathbf{p}_{1}, \mathbf{p}_{2}$를 3차원 점 $\mathbf{X}$을 통해 표현하면 아래와 같은 순서로 프로젝션된다.
\begin{equation}
\begin{aligned} \mathbf{p} = \pi(\mathbf{T}, \mathbf{X})
\end{aligned}
\end{equation}

\begin{equation}
\begin{aligned}
\mathbf{p}_{1} = \begin{pmatrix}
u_{1}\\v_{1}\end{pmatrix}
& = \pi(\mathbf{I}, \mathbf{X}) = \pi_{k}(\pi_{h}(\mathbf{X})) \\
\mathbf{p}_{2} = \begin{pmatrix} u_{2}\\ v_{2}\end{pmatrix} & = \pi(\mathbf{T}, \mathbf{X}) = \pi_{k}(\pi_{h}(\mathbf{TX})) \\ \end{aligned}
\end{equation}
direct method의 특징 중 하나는 feature-based와 달리 어떤 $\mathbf{p}_{2}$가 $\mathbf{p}_{1}$과 매칭하는지 알 수 있는 방법이 없다. 따라서 현재 포즈 추정치를 기반으로 $\mathbf{p}_{2}$의 위치를 찾는다. 즉, 카메라의 포즈를 최적화하여 $\mathbf{p}_{2}$와 $\mathbf{p}_{1}$을 유사하게 만드는데 이 때 photometric 에러를 최소화하여 문제를 해결한다. photometric 에러는 다음과 같다.
\begin{equation}
\boxed{
\begin{aligned}
\mathbf{e}(\mathbf{T}) & = \mathbf{I}_{1}(\mathbf{p}_{1})-\mathbf{I}_{2}(\mathbf{p}_{2}) \\
& = \mathbf{I}_{1} \bigg( \pi_{k}(\pi_{h}(\mathbf{X})) \bigg)-\mathbf{I}_{2}\bigg( \pi_{k}(\pi_{h}(\mathbf{TX})) \bigg) \\
\end{aligned} } \label{eq:photo3}
\end{equation}
photometric 에러는 grayscale 불변성 가정에 기반하며 스칼라 값을 가진다. photometric 에러를 통해 non-linear least squares를 풀기 위해 다음과 같은 에러 함수 $\mathbf{E}(\mathbf{T})$를 정의할 수 있다.
\begin{equation}
\begin{aligned}
\mathbf{E}(\mathbf{T}) & = \sum_{i \in \mathcal{P}} \left\| \mathbf{e}_{i}(\mathbf{T}) \right\|^{2} \\
\end{aligned}
\end{equation}
\begin{equation}
\begin{aligned}
\mathbf{T}^{*} & = \arg\min_{\mathbf{T}^{*}} \mathbf{E}(\mathbf{T}) \\
& = \arg\min_{\mathbf{T}^{*}} \sum_{i \in \mathcal{P}} \left\| \mathbf{e}_{i}(\mathbf{T}) \right\|^{2} \\
& = \arg\min_{\mathbf{T}^{*}} \sum_{i \in \mathcal{P}} \mathbf{e}_{i}(\mathbf{T})^{\intercal}\mathbf{e}_{i}(\mathbf{T}) \\
& = \arg\min_{\mathbf{T}^{*}} \sum_{i \in \mathcal{P}} \Big( \mathbf{I}_{1}(\mathbf{p}^{i}_{1})-\mathbf{I}_{2}(\mathbf{p}^{i}_{2}) \Big)^{\intercal} \Big( \mathbf{I}_{1}(\mathbf{p}^{i}_{1})-\mathbf{I}_{2}(\mathbf{p}^{i}_{2}) \Big)
\end{aligned}
\end{equation}
$\mathbf{E}(\mathbf{T}^{*})$를 만족하는 $\left\|\mathbf{e}(\mathbf{T}^{*})\right\|^{2}$를 non-linear least squares를 통해 반복적으로 계산할 수 있다. 작은 증분량 $\Delta \mathbf{T}$를 반복적으로 $\mathbf{T}$에 업데이트함으로써 최적의 상태를 찾는다.
\begin{equation}
\begin{aligned}
\arg\min_{\mathbf{T}^{*}} \mathbf{E}(\mathbf{T} + \Delta \mathbf{T}) & = \arg\min_{\mathbf{T}^{*}} \sum_{i \in \mathcal{P}} \left\|\mathbf{e}_{i}(\mathbf{T} + \Delta \mathbf{T})\right\|^{2}
\end{aligned}
\end{equation}
엄밀하게 말하면 상태 증분량 $\Delta \mathbf{T}$은 SE(3) 변환행렬이므로 $\oplus$ 연산자를 통해 기존 상태 $\mathbf{T}$에 더해지는게 맞지만 표현의 편의를 위해 $+$ 연산자를 사용하였다.
\begin{equation}
\begin{aligned}
\mathbf{T} \oplus \Delta \mathbf{T} \quad \rightarrow \quad \mathbf{T} + \Delta \mathbf{T}
\end{aligned}
\end{equation}
이는 1차 테일러 근사를 통해 다음과 같이 표현이 가능하다.
\begin{equation}
\begin{aligned}
\mathbf{e}(\mathbf{T} + \Delta \mathbf{T}) & \approx \mathbf{e}_{i}(\mathbf{T}) + \mathbf{J}\Delta \mathbf{T} \\
& = \mathbf{e}_{i}(\mathbf{T}) + \frac{\partial \mathbf{e}}{\partial \mathbf{T}}\Delta \mathbf{T}
\end{aligned}
\end{equation}
\begin{equation}
\begin{aligned}
\arg\min_{\mathbf{T}^{*}} \mathbf{E}(\mathbf{T} + \Delta \mathbf{T}) & = \arg\min_{\mathbf{T}^{*}} \sum_{i \in \mathcal{P}} \left\|\mathbf{e}_{i}(\mathbf{T}) + \mathbf{J}\Delta \mathbf{T}\right\|^{2}
\end{aligned}
\end{equation}
이를 미분하여 최적의 증분량 $\Delta \mathbf{T}^{*}$ 값을 구하면 다음과 같다. 자세한 유도 과정은 본 섹션에서는 생략한다. 유도 과정에 대해 자세히 알고 싶으면 이전 섹션을 참조하면 된다.
\begin{equation}
\begin{aligned}
& \mathbf{J}^{\intercal}\mathbf{J} \Delta \mathbf{T}^{*} = -\mathbf{J}^{\intercal}\mathbf{e} \\
& \mathbf{H}\Delta \mathbf{T}^{*} = - \mathbf{b} \\
\end{aligned} \label{eq:photo1}
\end{equation}
위 식은 선형시스템 $\mathbf{Ax} = \mathbf{b}$ 형태이므로 schur complement, cholesky decomposition과 같은 다양한 선형대수학 테크닉을 사용하여 $\Delta \mathbf{T}^{*}$를 구할 수 있다. 이렇게 구한 최적의 증분량을 현재 상태에 더한다. 이 때, 기존 상태 $\mathbf{T}$의 오른쪽에 곱하느냐 왼쪽에 곱하느냐에 따라서 각각 로컬 좌표계에서 본 포즈를 업데이트할 것 인지(오른쪽) 전역 좌표계에서 본 포즈를 업데이트할 것 인지(왼쪽) 달라지게 된다. Photometric 에러는 전역 좌표계의 변환 행렬을 업데이트하므로 일반적으로 왼쪽 곱셈 방법을 사용한다.
\begin{equation}
\begin{aligned}
\mathbf{T} \leftarrow \mathbf{T} \oplus \Delta \mathbf{T}^{*}
\end{aligned}
\end{equation}
왼쪽 곱셈 $\oplus$ 연산의 정의는 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{T} \oplus \Delta \mathbf{T}^{*}& = \Delta \mathbf{T}^{*}\mathbf{T} \\ & = \text{Exp}(\Delta \xi^{*}) \mathbf{T} \quad \cdots \text{ globally updated (left mult)} \end{aligned} \label{eq:photo2}
\end{equation}
4.1. Jacobian of the photometric error
(\ref{eq:photo1})를 수행하기 위해서는 photometric 에러에 대한 자코비안 $\mathbf{J}$을 구해야 한다. 이는 다음과 같이 나타낼 수 있다.
\begin{equation}
\begin{aligned}
\mathbf{J} & = \frac{\partial \mathbf{e}}{\partial \mathbf{T}} \\
& = \frac{\partial \mathbf{e}}{\partial [\mathbf{R}, \mathbf{t}]}
\end{aligned}
\end{equation}
이를 자세히 풀어서 보면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{J} = \frac{\partial \mathbf{e}}{\partial \mathbf{T}} & = \frac{\partial }{\partial \mathbf{T}} \bigg( \mathbf{I}_{1}(\mathbf{p}_{1}) - \mathbf{I}_{2}(\mathbf{p}_{2}) \bigg) \\ & = \frac{\partial }{\partial \mathbf{T}} \bigg(
\mathbf{I}_{1} \bigg( \pi_{k}(\pi_{h}(\mathbf{X})) \bigg)-\mathbf{I}_{2}\bigg( \pi_{k}(\pi_{h}(\mathbf{TX})) \bigg) \bigg) \\
& = \frac{\partial }{\partial \mathbf{T}} \bigg( -\mathbf{I}_{2}\bigg( \pi_{k}(\pi_{h}(\mathbf{TX})) \bigg) \bigg) \\ & = \frac{\partial }{\partial \mathbf{T}} \bigg( -\mathbf{I}_{2}\bigg( \pi_{k}(\pi_{h}(\mathbf{X}')) \bigg) \bigg)
\end{aligned}
\end{equation}
Chain rule을 적용하여 위 식을 다시 표현하면 다음과 같다.
\begin{equation}
\begin{aligned}
\frac{\partial \mathbf{e}}{\partial \xi} & = \frac{\partial \mathbf{I}}{\partial \mathbf{p}_{2}} \frac{\partial \mathbf{p}_{2}}{\partial \tilde{\mathbf{p}}_{2}} \frac{\partial \tilde{\mathbf{p}}_{2}}{\partial \mathbf{X}'} \frac{\partial \mathbf{X}'}{\partial \xi} \\
& = \mathbb{R}^{1\times2} \cdot \mathbb{R}^{2\times3} \cdot \mathbb{R}^{3\times4} \cdot \mathbb{R}^{4\times6} = \mathbb{R}^{1\times6}
\end{aligned}
\end{equation}
이 때, 변환행렬 $\mathbf{T}$에 대한 자코비안 $\frac{\partial \mathbf{X}'}{\partial \mathbf{T}}$을 구하는 것이 아닌 twist $\xi$에 대한 자코비안 $\frac{\partial \mathbf{X}'}{\partial \xi}$을 구하는 이유는 다음 섹션에서 설명한다. 우선 $\frac{\partial \mathbf{I}}{\partial \mathbf{p}_{2}}$은 이미지의 기울기(gradient)를 의미한다.
\begin{equation}
\boxed{
\begin{aligned}
\frac{\partial \mathbf{I}}{\partial \mathbf{p}_{2}} & = \begin{bmatrix} \frac{\partial \mathbf{I}}{\partial u} & \frac{\partial \mathbf{I}}{\partial v} \end{bmatrix} \\
& = \begin{bmatrix} \nabla \mathbf{I}_{u} & \nabla \mathbf{I}_{v} \end{bmatrix}
\end{aligned} } \label{eq:photo4}
\end{equation}
렌즈에 의한 왜곡(distortion)은 일반적으로 계산의 복잡성으로 인해 자코비안 계산 시 고려하지 않는다. 또한 렌즈 왜곡 보정(undistortion)이 이미지 입력 과정에서 이미 수행되었다고 가정하면 이를 고려할 필요가 없어진다.
따라서 $\frac{\partial \mathbf{p}_{2}}{\partial \tilde{\mathbf{p}}_{2}}$은 다음과 같이 단순히 카메라 내부 행렬 $\mathbf{K}$를 곱하는 것으로 구할 수 있다. 아래 수식에서는 마지막 행 $[0\ 0\ 1]$을 생략한 $\tilde{\mathbf{K}}$가 사용되었다.
\begin{equation}
\boxed{
\begin{aligned}
\frac{\partial \mathbf{p}_{2}}{\partial \tilde{\mathbf{p}}_{2}} & =
\frac{\partial }{\partial \tilde{\mathbf{p}}_{2}} \tilde{\mathbf{K}} \tilde{\mathbf{p}}_{2} \\
& = \tilde{\mathbf{K}} \\
& = \begin{bmatrix} f & 0 & c_{x} \\ 0 & f & c_{y} \end{bmatrix} \in \mathbb{R}^{2 \times 3}
\end{aligned} }
\end{equation}
다음으로 $\frac{\partial \tilde{\mathbf{p}}_{2}}{\partial \mathbf{X}'}$은 다음과 같다.
\begin{equation}
\boxed{
\begin{aligned}
\frac{\partial \tilde{\mathbf{p}}_{2}}{\partial \mathbf{X}'} & =
\frac{\partial [\tilde{u}_{2}, \tilde{v}_{2}, 1]}{\partial [X', Y', Z',1]} \\
& = \begin{bmatrix} \frac{1}{Z'} & 0 & \frac{-X'}{Z'^{2}} & 0\\
0 & \frac{1}{Z'} & \frac{-Y'}{Z'^{2}} &0 \\ 0 & 0 & 0 & 0 \end{bmatrix} \in \mathbb{R}^{3\times 4}
\end{aligned} } \label{eq:photo5}
\end{equation}
4.1.1. Lie theory-based SE(3) optimization
마지막으로 $\frac{\partial \mathbf{X}'}{\partial \mathbf{T}} = \frac{\partial \mathbf{X}'}{\partial [\mathbf{R}, \mathbf{t}]}$를 구해야 한다. 이 때, 위치에 관련된 항 $\mathbf{t}$는 3차원 벡터이고 해당 벡터의 크기가 3차원 위치를 표현하는 최소한의 자유도인 3 자유도와 동일하므로 최적화 업데이트를 수행할 때 별도의 제약조건이 존재하지 않는다. 반면에, 회전행렬 $\mathbf{R}$은 파라미터의 개수가 9개이고 이는 3차원 회전을 표현하는 최소 자유도인 3 자유도보다 많으므로 다양한 제약조건이 존재한다. 이를 over-parameterized 되었다고 한다. over-parameterized 표현법의 단점은 다음과 같다.
- 중복되는 파라미터를 계산해야 하기 때문에 최적화 수행 시 연산량이 증가한다.
- 추가적인 자유도로 인해 수치적인 불안정성(numerical instability) 문제가 야기될 수 있다.
- 파라미터가 업데이트될 때마다 항상 제약조건을 만족하는 지 체크해줘야 한다.
따라서 제약조건으로 부터 자유로운 최소 파라미터(minimal parameter) 표현법인 lie theory 기반 최적화 방식을 일반적으로 사용한다. lie group SE(3) 기반 최적화 방법은 비선형의 회전행렬을 포함하는 $\Delta \mathbf{T}^{*}$를 구하는 대신 회전 관련된 항은 $\mathbf{R} \rightarrow \mathbf{w}$으로 변경하고 위치 관련된 항은 $\mathbf{t} \rightarrow \mathbf{v}$로 변경하여 최적의 twist $\Delta \xi^{*}$를 구한 후 lie algebra se(3) $[\Delta \xi]_{\times}$를 exponential mapping을 통해 SE(3)에 업데이트 하는 방법을 말한다.
\begin{equation}
\begin{aligned}
\Delta \mathbf{T}^{*} & \rightarrow \Delta \xi^{*}
\end{aligned}
\end{equation}
$\xi$에 대한 자코비안은 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{J} & = \frac{\partial \mathbf{e}}{\partial [\mathbf{R}, \mathbf{t}]} && \rightarrow \frac{\partial \mathbf{e}}{\partial [\mathbf{w}, \mathbf{v}]} \\
& && \rightarrow \frac{\partial \mathbf{e}}{\partial \xi}
\end{aligned}
\end{equation}
이를 통해 기존의 식은 다음과 같이 변경된다.
\begin{equation}
\begin{aligned}
\mathbf{e}(\mathbf{T}) \quad \quad & \rightarrow \quad \quad \mathbf{e}(\xi) \\
\mathbf{E}(\mathbf{T}) \quad \quad & \rightarrow \quad \quad \mathbf{E}(\xi) \\
\mathbf{e}(\mathbf{T}) + \mathbf{J}'\Delta \mathbf{T} \quad \quad & \rightarrow \quad \quad \mathbf{e}(\xi) + \mathbf{J}\Delta \xi \\
\mathbf{H}\Delta\mathbf{T}^{*} = -\mathbf{b} \quad \quad & \rightarrow \quad \quad \mathbf{H}\Delta \xi^{*} = -\mathbf{b} \\
\mathbf{T} \leftarrow \Delta \mathbf{T}^{*}\mathbf{T} \quad \quad & \rightarrow \quad \quad \mathbf{T} \leftarrow \text{Exp}(\Delta \xi^{*}) \mathbf{T}
\end{aligned}
\end{equation}
- $\mathbf{J}' = \frac{\partial \mathbf{e}}{\partial \mathbf{T}} $
- $\mathbf{J} = \frac{\partial \mathbf{e}}{\partial \xi} $
$\text{Exp}(\xi) \in \text{SE}(3)$는 twist $\xi$를 exponential mapping하여 3차원 포즈로 변환하는 연산을 말한다. exponential mapping에 대한 자세한 내용은 해당 링크를 참조하면 된다.
\begin{equation} \begin{aligned} \text{Exp}(\Delta \xi) = \Delta \mathbf{T} \end{aligned} \end{equation}
지금까지 자코비안들은 계산하기 용이했던 반면에 $\frac{\partial \mathbf{X}'}{\partial \xi}$은 파라미터 $\xi$가 $\mathbf{X}'$에서 바로 보이지 않으므로 $\mathbf{X}'$를 lie algebra와 관련된 항으로 변경해야 한다.
\begin{equation}
\begin{aligned}
\mathbf{X}' \rightarrow \mathbf{TX} \rightarrow \text{Exp}(\xi)\mathbf{X}
\end{aligned}
\end{equation}
이 때, 작은 lie algebra 증분량 $\Delta \xi$를 기존 $\text{Exp}(\xi)$에 업데이트하는 방식에 따라 두 가지 방법으로 나뉘게 된다. 우선 [1] 기본적인 lie algebra를 사용한 업데이트 방법이 있다. 다음으로 [2] 섭동(perturbation) 모델을 활용한 업데이트 방법이 있다.
\begin{equation}
\begin{aligned}
\text{Exp}(\xi) & \leftarrow \text{Exp}(\xi + \Delta \xi) \quad \cdots \text{[1]} \\
\text{Exp}(\xi) & \leftarrow \text{Exp}(\Delta \xi)\text{Exp}(\xi) \quad \cdots \text{[2]}
\end{aligned}
\end{equation}
위 두 방법 중 $[1]$ 방법은 기존 $\xi$에 미세 증분량 $\Delta \xi$를 더한 후 exponential mapping을 수행하여 자코비안을 구하는 방법이며 $[2]$ 방법은 기존 $\xi$ 왼쪽에 섭동(perturbation) 모델 $\text{Exp}(\Delta \xi)$을 곱함으로써 기존 상태를 업데이트하는 방법이다.
두 방법 사이에는 다음과 같은 변환이 존재하며 이를 BCH 근사라고 한다. 자세한 내용은 Lie theory 개념 정리 포스팅을 참조하면 된다.
\begin{equation} \begin{aligned} \text{Exp}(\Delta \xi)\text{Exp}(\xi) & = \text{Exp}(\xi + \mathcal{J}^{-1}_{l}\Delta \xi) \\ \text{Exp}(\xi + \Delta \xi) & = \text{Exp}(\mathcal{J}_{l}\Delta \xi)\text{Exp}(\xi) \\ \end{aligned} \label{eq:bch} \end{equation}
$[1]$ 방법을 사용하여 $\frac{\partial \mathbf{X}'}{\partial \xi}$에 대한 자코비안을 계산하면 다음과 같다.
\begin{equation}
\boxed{ \begin{aligned}
\frac{\partial \mathbf{X}'}{\partial \Delta \xi} & = \lim_{\Delta \xi \rightarrow 0} \frac{\text{Exp}(\xi + \Delta \xi) - \text{Exp}(\xi)}{\Delta \xi} \\
& = \lim_{\Delta \xi \rightarrow 0} \frac{\text{Exp}(\mathcal{J}_l \Delta \xi)\text{Exp}(\xi) - \text{Exp}(\xi)}{\Delta \xi} \\
& \approx \lim_{\Delta \xi \rightarrow 0} \frac{(\mathbf{I} + [\mathcal{J}_l \Delta \xi]_{\times})\text{Exp}(\xi) - \text{Exp}(\xi)}{\Delta \xi} \\
& = \lim_{\Delta \xi \rightarrow 0} \frac{[\mathcal{J}_l \Delta \xi]_{\times}\mathbf{X}'}{\Delta \xi} \\
& = \lim_{\Delta \xi \rightarrow 0} \frac{ \Bigg[ \begin{bmatrix} \mathbf{J}_l & \mathbf{Q}_l \\ \mathbf{0} & \mathbf{J}_l \end{bmatrix} \begin{bmatrix} \Delta \omega \\ \Delta \mathbf{v} \end{bmatrix} \Bigg]_{\times} \begin{bmatrix} \tilde{\mathbf{X}}' \\ 1 \end{bmatrix}}{\Delta \xi} \\
& = \lim_{\Delta \xi \rightarrow 0} \frac{ \Bigg[ \begin{bmatrix} \mathbf{J}_l \Delta \omega + \mathbf{Q}_l \Delta \mathbf{v} \\ \mathbf{J}_l \Delta \mathbf{v} \end{bmatrix} \Bigg]_{\times} \begin{bmatrix} \tilde{\mathbf{X}}' \\ 1 \end{bmatrix}}{\Delta \xi} \\
& = \lim_{\Delta \xi \rightarrow 0} \frac{\begin{bmatrix} [\mathbf{J}_l \Delta \mathbf{w} + \mathbf{Q}_l \Delta \mathbf{v}]_{\times} & \mathbf{J}_l \Delta \mathbf{v} \\ \mathbf{0}^{\intercal} & 0 \end{bmatrix} \begin{bmatrix} \tilde{\mathbf{X}}' \\ 1 \end{bmatrix}}{\Delta \xi} \\
& = \lim_{\Delta \xi \rightarrow 0} \frac{\begin{bmatrix} [\mathbf{J}_l \Delta \mathbf{w} + \mathbf{Q}_l \Delta \mathbf{v}]_{\times} \tilde{\mathbf{X}}' + \mathbf{J}_l \Delta \mathbf{v} \\ \mathbf{0}^{\intercal} \end{bmatrix}}{[\Delta \mathbf{w}, \Delta \mathbf{v}]^{\intercal}} \\
& = \lim_{\Delta \xi \rightarrow 0} \frac{\begin{bmatrix} -[\tilde{\mathbf{X}}']_{\times}(\mathbf{J}_l \Delta \mathbf{w} + \mathbf{Q}_l \Delta \mathbf{v}) + \mathbf{J}_l \Delta \mathbf{v} \\ \mathbf{0}^{\intercal} \end{bmatrix}}{[\Delta \mathbf{w}, \Delta \mathbf{v}]^{\intercal}} \\
& = \begin{bmatrix} -[\tilde{\mathbf{X}}']_{\times}\mathbf{J}_l & -[\tilde{\mathbf{X}}']_{\times}\mathbf{Q}_l + \mathbf{J}_l \\ \mathbf{0}^{\intercal} & \mathbf{0}^{\intercal} \end{bmatrix} \in \mathbb{R}^{4 \times 6}
\end{aligned} }
\end{equation}
- $\mathcal{J}_{l} =\begin{bmatrix} \mathbf{J}_l & \mathbf{Q}_l \\ \mathbf{0} & \mathbf{J}_l \end{bmatrix}$: Lie theory 개념 정리 포스트 참조
위 식에서 보다시피 $[1]$ 방법을 사용하면 매우 복잡한 식이 유도되기 때문에 해당 방법은 잘 사용되지 않고 $[2]$의 섭동 모델을 주로 사용한다. 따라서 $\frac{\partial \mathbf{X}'}{\partial \xi}$은 다음과 같이 변형된다.
\begin{equation}
\begin{aligned}
\frac{\partial \mathbf{X}'}{\partial \xi} & \rightarrow \frac{\partial \mathbf{X}'}{\partial \Delta \xi}
\end{aligned}
\end{equation}
$\frac{\partial \mathbf{X}'}{\partial \Delta \xi}$에 대한 자코비안은 다음과 같이 계산할 수 있다.
\begin{equation} \boxed{ \begin{aligned}
\frac{\partial \mathbf{X}'}{\partial \Delta \xi} & = \lim_{\Delta \xi \rightarrow 0} \frac{\text{Exp}(\Delta \xi) \mathbf{X}' - \mathbf{X}'}{\Delta \xi} \\
& \approx \lim_{\Delta \xi \rightarrow 0} \frac{(\mathbf{I} + [\Delta \xi]_{\times})\mathbf{X}' - \mathbf{X}'}{\Delta \xi} \\
& = \lim_{\Delta \xi \rightarrow 0} \frac{[\Delta \xi]_{\times}\mathbf{X}'}{\Delta \xi} \\
& = \lim_{\Delta \xi \rightarrow 0} \frac{\begin{bmatrix} [\Delta \mathbf{w}]_{\times} & \Delta \mathbf{v} \\ \mathbf{0}^{\intercal} & 0 \end{bmatrix} \begin{bmatrix} \tilde{\mathbf{X}}' \\ 1 \end{bmatrix}}{\Delta \xi} \\
& = \lim_{\Delta \xi \rightarrow 0} \frac{\begin{bmatrix} -[\tilde{\mathbf{X}}']_{\times}\Delta \mathbf{w} + \Delta \mathbf{v} \\ \mathbf{0}^{\intercal} \end{bmatrix}}{[\Delta \mathbf{w}, \Delta \mathbf{v}]^{\intercal}} \\
&= \begin{bmatrix} -[\tilde{\mathbf{X}}']_{\times} & \mathbf{I} \\ \mathbf{0}^{\intercal} & \mathbf{0}^{\intercal} \end{bmatrix} \in \mathbb{R}^{4 \times 6}
\end{aligned} } \end{equation}
따라서 $[2]$ 섭동 모델을 사용하는 경우 3차원 공간 상의 점 $\mathbf{X}'$의 반대칭 행렬을 사용하여 간단하게 자코비안을 구할 수 있는 이점이 있다. photometric 에러 최적화의 경우 대부분 순차적으로 들어오는 이미지들의 밝기 변화에 대한 에러를 최적화하므로 카메라 포즈 변화가 크지 않고 따라서 $\Delta \xi$의 크기 또한 크지 않으므로 일반적으로 위의 자코비안을 주로 사용한다. $[2]$ 섭동 모델을 사용하므로 작은 증분량 $\Delta \xi^{*}$는 (\ref{eq:photo2})와 같이 업데이트된다.
\begin{equation}
\begin{aligned}
\mathbf{T} \leftarrow \Delta \mathbf{T}^{*}\mathbf{T}= \text{Exp}(\Delta \xi^{*}) \mathbf{T}
\end{aligned}
\end{equation}
위 식에서 두 번째 행은 작은 twist 증분량 $\text{Exp}(\Delta \xi)$에 대해 1차 테일러 근사가 적용된 형태이다. 두 번째 행의 근사를 이해하기 위해 임의의 twist $\xi = [\mathbf{w}, \mathbf{v}]^{\intercal}$가 주어졌을 때 변환행렬 $\mathbf{T}$를 exponential mapping 형태로 전개하면 다음과 같이 나타낼 수 있다. \begin{equation} \begin{aligned} \mathbf{T} & = \text{Exp}(\xi) \\ & = \exp([\xi]_{\times}) \\ & = \mathbf{I} + \begin{bmatrix} [\mathbf{w}]_{\times} & \mathbf{v} \\ \mathbf{0}^{\intercal} & 0 \end{bmatrix} + \frac{1}{2!} \begin{bmatrix} [\mathbf{w}]_{\times}^{2} & [\mathbf{w}]_{\times}\mathbf{v} \\ \mathbf{0}^{\intercal} & 0 \end{bmatrix} + \frac{1}{3!} \begin{bmatrix} [\mathbf{w}]_{\times}^{3} & [\mathbf{w}]_{\times}^{2}\mathbf{v} \\ \mathbf{0}^{\intercal} & 0 \end{bmatrix} + \cdots \\ & = \mathbf{I} + [ \xi]_{\times} + \frac{1}{2!} [ \xi]_{\times}^{2} + \frac{1}{3!} [ \xi]_{\times}^{3} + \cdots \end{aligned} \end{equation}
작은 크기의 twist 증분량 $\Delta \xi$에 대해서는 2차 이상의 고차항을 무시하여 다음과 같이 근사적으로 나타낼 수 있다. \begin{equation} \begin{aligned} \text{Exp}(\Delta \xi) \approx \mathbf{I} + [\Delta \xi]_{\times} \end{aligned} \end{equation}
최종적인 포즈에 대한 자코비안 $\mathbf{J}$은 다음과 같다.
\begin{equation}
\boxed{
\begin{aligned}
\mathbf{J} = \frac{\partial \mathbf{e}}{\partial \Delta \xi} & = \frac{\partial \mathbf{I}}{\partial \mathbf{p}_{2}} \frac{\partial \mathbf{p}_{2}}{\partial \tilde{\mathbf{p}}_{2}} \frac{\partial \tilde{\mathbf{p}}_{2}}{\partial \mathbf{X}'} \frac{\partial \mathbf{X}'}{\partial \Delta \xi} \\
& = \begin{bmatrix} \nabla \mathbf{I}_{u} & \nabla \mathbf{I}_{v} \end{bmatrix}
\begin{bmatrix} f & 0 & c_{x} \\ 0 & f & c_{y} \end{bmatrix}
\begin{bmatrix} \frac{1}{Z'} & 0 & \frac{-X'}{Z'^{2}} & 0 \\ 0 & \frac{1}{Z'} & \frac{-Y'}{Z'^{2}}&0\\ 0 & 0 & 0 & 0\end{bmatrix}
\begin{bmatrix} -[\tilde{\mathbf{X}}']_{\times} & \mathbf{I} \\ \mathbf{0}^{\intercal} & \mathbf{0}^{\intercal} \end{bmatrix} \\
& = \begin{bmatrix} \nabla \mathbf{I}_{u} & \nabla \mathbf{I}_{v} \end{bmatrix} \begin{bmatrix} \frac{f}{Z'} & 0 & -\frac{fX}{Z'^{2}} & 0\\ 0 & \frac{f}{Z'} & -\frac{fY}{Z'^{2}} & 0\end{bmatrix}
\begin{bmatrix} 0 & Z' & -Y' & 1 & 0 & 0 \\ -Z' & 0 & X' & 0 & 1 & 0 \\ Y'& -X'& 0 & 0 & 0 & 1 \\ 0 & 0 & 0&0&0&0\end{bmatrix} \\
& = \begin{bmatrix} \nabla \mathbf{I}_{u} & \nabla \mathbf{I}_{v} \end{bmatrix} \begin{bmatrix} -\frac{fX'Y'}{Z'^{2}} & \frac{f(1 + X'^{2})}{Z'^{2}} & -\frac{fY'}{Z'} & \frac{f}{Z'} & 0 & -\frac{fX'}{Z'^{2}} \\
-\frac{f(1+Y'^{2})}{Z'^{2}} & \frac{fX'Y'}{Z'^{2}} & \frac{fX'}{Z'} & 0 & \frac{f}{Z'} & -\frac{fY'}{Z'^{2}} \end{bmatrix} \in \mathbb{R}^{1 \times 6}
\end{aligned} }
\end{equation}
이 때, $\frac{\partial \mathbf{X}'}{\partial \Delta \xi}$의 마지막 행은 항상 0이므로 이를 생략하고 계산하기도 한다.
4.2. Code implementations
- Visual SLAM 입문 챕터8 코드: direct_sparse.cpp#L111
- DSO 코드: CoarseInitializer.cpp#L430
- DSO 코드2: CoarseTracker.cpp#L320
5. Relative pose error
Relative pose 에러는 주로 pose graph optimization(PGO)에서 사용하는 에러이다. PGO에 대한 자세한 내용은 [SLAM] Pose Graph Optimization 개념 설명 및 예제 코드 분석 포스트를 참조하면 된다.
NOMENCLATURE of relative pose error
- $\text{(Node) } \mathbf{x}_{i} = \begin{bmatrix} \mathbf{R}_{i} & \mathbf{t}_{i} \\ \mathbf{0}^{\intercal} & 1 \end{bmatrix} \in \mathbb{R}^{4\times 4}$
- $\text{(Edge) } \mathbf{z}_{ij} = \begin{bmatrix} \mathbf{R}_{ij} & \mathbf{t}_{ij} \\ \mathbf{0}^{\intercal} & 1 \end{bmatrix} \in \mathbb{R}^{4\times 4}$
- $\hat{\mathbf{z}}_{ij} = \ \mathbf{x}_{i}^{-1}\mathbf{x}_{j}$ : 예측값
- $\mathbf{z}_{ij}$ : 관측값 (virtual measurement)
- $\mathbf{x} = [\mathbf{x}_{1}, \cdots, \mathbf{x}_{n}]$: pose graph의 모든 포즈 노드
- $\mathbf{e}_{ij}(\mathbf{x}_{i},\mathbf{x}_{j}) \leftrightarrow \mathbf{e}_{ij}$: 표현의 편의를 위해 생략하여 표기하기도 한다.
- $\mathbf{J} = \frac{\partial \mathbf{e}}{\partial \mathbf{x}}$
- $\oplus$ : 두 SE(3) 군을 결합(composition)하는 연산자
- $\text{Log}(\cdot)$: SE(3)를 twist $\xi \in \mathbb{R}^{6}$로 변환하는 연산자. Logarithm mapping에 대한 자세한 내용은 해당 포스트를 참조하면 된다.
- $\text{Exp}(\xi) = \exp([\xi]_{\times})$
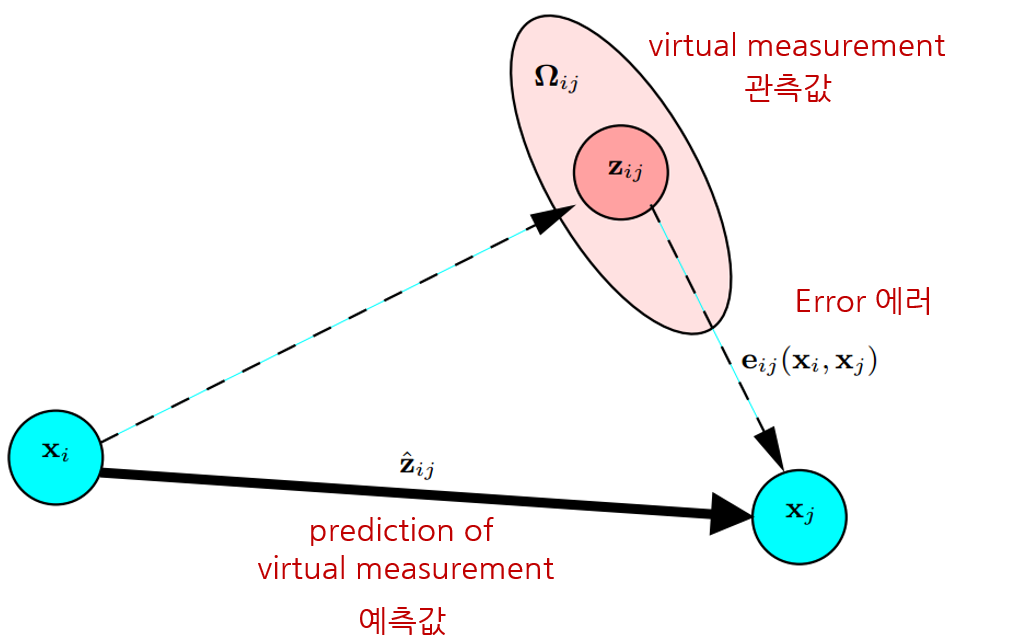
Pose graph 상에서 두 노드 $\mathbf{x}_{i}, \mathbf{x}_{j}$가 주어졌을 때 센서 데이터에 의해 새롭게 계산한 상대포즈(관측값) $\mathbf{z}_{ij}$와 기존의 알고 있는 상대포즈(예측값) $\hat{\mathbf{z}}_{ij}$의 차이를 relative pose 에러로 정의한다. (Freiburg univ. Robot Mapping Course 그림 참조).
\begin{equation}
\begin{aligned}
\mathbf{e}_{ij}(\mathbf{x}_{i},\mathbf{x}_{j}) = \mathbf{z}_{ij}^{-1}\hat{\mathbf{z}}_{ij} = \mathbf{z}_{ij}^{-1} \mathbf{x}_{i}^{-1}\mathbf{x}_{j}
\end{aligned}
\end{equation}
relative pose 에러를 최적화하는 과정을 pose graph optimization(PGO)라고 하며 graph-based SLAM의 back-end 알고리즘으로도 불린다. Front-end의 visual odometry(VO) 또는 lidar odometry(LO)에 의해 순차적으로 계산되는 노드 $\mathbf{x}_{i}, \mathbf{x}_{i+1}, \cdots$는 관측값과 예측값이 동일하기 때문에 PGO가 수행되지 않지만 loop closing이 발생하여 비순차적인 두 노드 $\mathbf{x}_{i}, \mathbf{x}_{j}$ 사이에 엣지가 연결되면 관측값과 예측값의 차이가 발생하기 때문에 PGO가 수행된다.
즉, PGO는 일반적으로 loop closing과 같은 특수한 상황이 발생할 때 수행된다. 로봇이 이동하면서 같은 장소를 재방문하는 경우 loop detection 알고리즘이 동작하여 루프를 판별한다. 이 때 루프가 탐지되면 기존 노드 $\mathbf{x}_{i}$와 재방문하여 생성된 노드 $\mathbf{x}_{j}$가 loop edge로 연결되고 여러 매칭 알고리즘 (GICP, NDT, etc...)에 의해 관측값을 생성한다. 이러한 관측값은 실제로 관측한 값이 아닌 매칭 알고리즘에 의해 생성된 가상의 관측값이므로 virtual measurement라고 불린다.
Pose graph 상의 모든 노드에 대한 relative pose 에러는 다음과 같이 정의할 수 있다.
\begin{equation}
\begin{aligned}
\mathbf{E}(\mathbf{x}) & = \sum_{i}\sum_{j} \left\| \mathbf{e}_{ij} (\mathbf{x})\right\|^{2} \\
\end{aligned}
\end{equation}
\begin{equation}
\begin{aligned}
\mathbf{x}^{*} & = \arg\min_{\mathbf{x}^{*}} \mathbf{E}(\mathbf{x}) \\
& = \arg\min_{\mathbf{x}^{*}} \sum_{i}\sum_{j} \left\| \mathbf{e}_{ij}(\mathbf{x}) \right\|^{2} \\
& = \arg\min_{\mathbf{x}^{*}} \sum_{i}\sum_{j} \mathbf{e}_{ij}(\mathbf{x})^{\intercal}\mathbf{e}_{ij} (\mathbf{x})
\end{aligned}
\end{equation}
$\mathbf{E}(\mathbf{x}^{*})$를 만족하는 $\left\|\mathbf{e}(\mathbf{x}^{*})\right\|^{2}$를 non-linear least squares를 통해 반복적으로 계산할 수 있다. 작은 증분량 $\Delta \mathbf{x}$를 반복적으로 $\mathbf{x}$에 업데이트함으로써 최적의 상태를 찾는다.
\begin{equation}
\begin{aligned}
\arg\min_{\mathbf{x}^{*}} \mathbf{E}(\mathbf{x} + \Delta \mathbf{x}) & = \arg\min_{\mathbf{x}^{*}} \sum_{i}\sum_{j} \left\|\mathbf{e}_{ij}(\mathbf{x}_{i} + \Delta \mathbf{x}_{i},\mathbf{x}_{j} + \Delta \mathbf{x}_{j})\right\|^{2}
\end{aligned}
\end{equation}
엄밀하게 말하면 상태 증분량 $\Delta \mathbf{x}$은 SE(3) 변환행렬이므로 $\oplus$ 연산자를 통해 기존 상태 $\mathbf{x}$에 더해지는게 맞지만 표현의 편의를 위해 $+$ 연산자를 사용하였다.
\begin{equation}
\begin{aligned}
\mathbf{e}_{ij}(\mathbf{x}_{i} \oplus \Delta \mathbf{x}_{i},\mathbf{x}_{j} \oplus \Delta \mathbf{x}_{j})
\quad \rightarrow \quad\mathbf{e}_{ij}(\mathbf{x}_{i} + \Delta \mathbf{x}_{i},\mathbf{x}_{j} + \Delta \mathbf{x}_{j})
\end{aligned}
\end{equation}
위 식은 테일러 1차 근사를 통해 다음과 같이 표현이 가능하다.
\begin{equation}
\begin{aligned}
\mathbf{e}_{ij}(\mathbf{x}_{i} + \Delta \mathbf{x}_{i},\mathbf{x}_{j} + \Delta \mathbf{x}_{j}) & \approx \mathbf{e}_{ij}(\mathbf{x}_{i} ,\mathbf{x}_{j} ) + \mathbf{J}_{ij} \begin{bmatrix} \Delta \mathbf{x}_{i} \\ \Delta \mathbf{x}_{j} \end{bmatrix} \\ & = \mathbf{e}_{ij}(\mathbf{x}_{i} ,\mathbf{x}_{j} ) + \mathbf{J}_{i}\Delta \mathbf{x}_{i} + \mathbf{J}_{j}\Delta \mathbf{x}_{j} \\
& = \mathbf{e}_{ij}(\mathbf{x}_{i} ,\mathbf{x}_{j} ) + \frac{\partial \mathbf{e}_{ij}}{\partial \mathbf{x}_{i}} \Delta \mathbf{x}_{i} + + \frac{\partial \mathbf{e}_{ij}}{\partial \mathbf{x}_{j}} \Delta \mathbf{x}_{j}
\end{aligned} \label{eq:rel14}
\end{equation}
\begin{equation}
\begin{aligned}
\arg\min_{\mathbf{x}^{*}} \mathbf{E}(\mathbf{x} + \Delta \mathbf{x}) & \approx \arg\min_{\mathbf{x}^{*}} \sum_{i}\sum_{j} \left\|\mathbf{e}_{ij}(\mathbf{x}_{i},\mathbf{x}_{j}) + \mathbf{J}_{ij} \begin{bmatrix} \Delta \mathbf{x}_{i} \\ \Delta \mathbf{x}_{j} \end{bmatrix} \right\|^{2} \\
\end{aligned}
\end{equation}
이를 미분하여 모든 노드에 대한 최적의 증분량 $\Delta \mathbf{x}^{*}$ 값을 구하면 다음과 같다. 자세한 유도 과정은 본 섹션에서는 생략한다. 유도 과정에 대해 자세히 알고 싶으면 이전 섹션을 참조하면 된다.
\begin{equation}
\begin{aligned}
& \mathbf{J}^{\intercal}\mathbf{J} \Delta \mathbf{x}^{*} = -\mathbf{J}^{\intercal}\mathbf{e} \\
& \mathbf{H}\Delta \mathbf{x}^{*} = - \mathbf{b} \\
\end{aligned} \label{eq:rel6}
\end{equation}
위 식은 선형시스템 $\mathbf{Ax} = \mathbf{b}$ 형태이므로 schur complement, cholesky decomposition과 같은 다양한 선형대수학 테크닉을 사용하여 $\Delta \mathbf{x}^{*}$를 구할 수 있다. 이렇게 구한 최적의 증분량을 현재 상태에 더한다. 이 때, 기존 상태 $\mathbf{x}$의 오른쪽에 곱하느냐 왼쪽에 곱하느냐에 따라서 각각 로컬 좌표계에서 본 포즈를 업데이트할 것 인지(오른쪽) 전역 좌표계에서 본 포즈를 업데이트할 것 인지(왼쪽) 달라지게 된다. relative pose 에러는 두 노드의 상대 포즈에 관련되어 있으므로 로컬 좌표계에서 업데이트하는 오른쪽 곱셈이 적용된다.
\begin{equation}
\begin{aligned}
\mathbf{x} \leftarrow \mathbf{x} \oplus \Delta \mathbf{x}^{*}
\end{aligned}
\end{equation}
오른쪽 곱셈 $\oplus$ 연산의 정의는 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{x} \oplus \Delta \mathbf{x}^{*}& = \mathbf{x} \Delta \mathbf{x}^{*} \\& = \mathbf{x} \text{Exp}(\Delta \xi^{*}) \quad \cdots \text{ locally updated (right mult)} \end{aligned} \label{eq:rel2}
\end{equation}
5.1. Jacobian of relative pose error
(\ref{eq:rel6})를 수행하기 위해서는 relative pose 에러에 대한 자코비안 $\mathbf{J}$을 구해야 한다. 비순차적인 두 노드 $\mathbf{x}_{i}, \mathbf{x}_{j}$가 주어졌을 때 이에 대한 자코비안 $\mathbf{J}_{ij}$ 다음과 같이 나타낼 수 있다.
\begin{equation}
\begin{aligned}
\mathbf{J}_{ij} & = \frac{\partial \mathbf{e}_{ij}}{\partial \mathbf{x}_{ij}} \\ & = \frac{\partial \mathbf{e}_{ij}}{\partial [\mathbf{x}_{i}, \mathbf{x}_{j}]} \\ & = [\mathbf{J}_{i}, \mathbf{J}_{j}]
\end{aligned}
\end{equation}
이를 자세히 풀어서 보면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{J}_{ij} = \frac{\partial \mathbf{e}_{ij}}{\partial [\mathbf{x}_{i}, \mathbf{x}_{j}]} & = \frac{\partial }{\partial [\mathbf{x}_{i}, \mathbf{x}_{j}]} \bigg( \mathbf{z}_{ij}^{-1} \hat{\mathbf{z}}_{ij} \bigg) \\ & = \frac{\partial }{\partial [\mathbf{R}_{i}, \mathbf{t}_{i}, \mathbf{R}_{j}, \mathbf{t}_{j}]} \bigg( \mathbf{z}_{ij}^{-1} \hat{\mathbf{z}}_{ij} \bigg) \\
\end{aligned}
\end{equation}
5.1.1. Lie theory-based SE(3) optimization
위 자코비안을 구할 때, 위치에 관련된 항 $\mathbf{t}$는 3차원 벡터이고 해당 벡터의 크기가 3차원 위치를 표현하는 최소한의 자유도인 3 자유도와 동일하므로 최적화 업데이트를 수행할 때 별도의 제약조건이 존재하지 않는다. 반면에, 회전행렬 $\mathbf{R}$은 파라미터의 개수가 9개이고 이는 3차원 회전을 표현하는 최소 자유도인 3 자유도보다 많으므로 다양한 제약조건이 존재한다. 이를 over-parameterized 되었다고 한다. over-parameterized 표현법의 단점은 다음과 같다.
- 중복되는 파라미터를 계산해야 하기 때문에 최적화 수행 시 연산량이 증가한다.
- 추가적인 자유도로 인해 수치적인 불안정성(numerical instability) 문제가 야기될 수 있다.
- 파라미터가 업데이트될 때마다 항상 제약조건을 만족하는 지 체크해줘야 한다.
따라서 제약조건으로 부터 자유로운 최소 파라미터(minimal parameter) 표현법인 lie theory 기반 최적화 방식을 일반적으로 사용한다. lie group SE(3) 기반 최적화 방법은 비선형의 회전행렬을 포함하는 $\Delta \mathbf{T}^{*}$를 구하는 대신 회전 관련된 항은 $\mathbf{R} \rightarrow \mathbf{w}$으로 변경하고 위치 관련된 항은 $\mathbf{t} \rightarrow \mathbf{v}$로 변경하여 최적의 twist $\Delta \xi^{*}$를 구한 후 lie algebra se(3) $[\Delta \xi]_{\times}$를 exponential mapping을 통해 SE(3)에 업데이트 하는 방법을 말한다.
\begin{equation}
\begin{aligned}
\begin{bmatrix} \Delta \mathbf{x}_{i}^{*}, \Delta \mathbf{x}_{j}^{*} \end{bmatrix} \rightarrow [\Delta \xi_{i}^{*}, \Delta \xi_{j}^{*}]
\end{aligned}
\end{equation}
$\xi$에 대한 자코비안은 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{J}_{ij} & = \frac{\partial \mathbf{e}_{ij}}{\partial [\mathbf{x}_{i}, \mathbf{x}_{j}]} && \rightarrow \frac{\partial \mathbf{e}_{ij}}{\partial [\xi_{i}, \xi_{j}]}
\end{aligned}
\end{equation}
이를 통해 기존의 식은 다음과 같이 변경된다.
\begin{equation}
\begin{aligned}
\mathbf{e}_{ij}(\mathbf{x}_{i}, \mathbf{x}_{j}) \quad \quad & \rightarrow \quad \quad \mathbf{e}_{ij}(\xi_{i}, \xi_{j}) \\
\mathbf{E}(\mathbf{x}) \quad \quad & \rightarrow \quad \quad \mathbf{E}(\xi) \\
\mathbf{e}_{ij}(\mathbf{x}_{i}, \mathbf{x}_{j}) + \mathbf{J}_{i}' \Delta \mathbf{x}_{i} + \mathbf{J}_{j}' \Delta \mathbf{x}_{j} \quad \quad & \rightarrow \quad \quad \mathbf{e}_{ij}(\xi_{i}, \xi_{j}) + \mathbf{J}_{i}\Delta \xi_{i} + \mathbf{J}_{j}\Delta \xi_{j} \\
\mathbf{H}\Delta\mathbf{x}^{*} = -\mathbf{b} \quad \quad & \rightarrow \quad \quad \mathbf{H}\Delta \xi^{*} = -\mathbf{b} \\
\mathbf{x} \leftarrow \Delta \mathbf{x}^{*}\mathbf{x} \quad \quad & \rightarrow \quad \quad \mathbf{x} \leftarrow \text{Exp}(\Delta \xi^{*}) \mathbf{x}
\end{aligned}
\end{equation}
- $\mathbf{J}_{ij}' = \frac{\partial \mathbf{e}}{\partial [\mathbf{x}_{i}, \mathbf{x}_{j}]}$
- $\mathbf{J}_{ij} = \frac{\partial \mathbf{e}}{\partial [\xi_{i}, \xi_{j}]} $
$\text{Exp}(\xi) \in \text{SE}(3)$는 twist $\xi$를 exponential mapping하여 3차원 포즈로 변환하는 연산을 말한다. exponential mapping에 대한 자세한 내용은 해당 링크를 참조하면 된다. \begin{equation} \begin{aligned} \text{Exp}(\Delta \xi) = \Delta \mathbf{x} \end{aligned} \end{equation}
$\frac{\partial }{\partial \xi}( \mathbf{z}_{ij}^{-1} \hat{\mathbf{z}}_{ij})$은 파라미터 $\xi$가 $\mathbf{z}_{ij}^{-1} \hat{\mathbf{z}}_{ij}$에서 바로 보이지 않으므로 이를 lie algebra와 관련된 항으로 변경해야 한다.
\begin{equation}
\begin{aligned}
\mathbf{z}_{ij}^{-1}\hat{\mathbf{z}}_{ij} & \rightarrow \text{Log}(\mathbf{z}_{ij}^{-1}\hat{\mathbf{z}}_{ij})
\end{aligned}
\end{equation}
이 때, $\text{Log}(\cdot)$는 SE(3)에서 twist $\xi \in \mathbb{R}^{6}$로 변경하는 logarithm mapping을 의미한다. Logarithm mapping에 대한 자세한 내용은 해당 포스트를 참조하면 된다. 따라서 SE(3) 버전 relative pose 에러 $\mathbf{e}_{ij}$는 다음과 같이 변경된다.
\begin{equation}
\boxed{ \begin{aligned}
\mathbf{e}_{ij}(\mathbf{x}_{i},\mathbf{x}_{j}) = \mathbf{z}_{ij}^{-1}\hat{\mathbf{z}}_{ij} \quad \rightarrow \quad \mathbf{e}_{ij}(\xi_{i}, \xi_{j})& = \text{Log}(\mathbf{z}_{ij}^{-1}\hat{\mathbf{z}}_{ij})
\end{aligned} } \label{eq:rel22}
\end{equation}
이를 자세히 풀어쓰면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{e}_{ij}(\xi_{i}, \xi_{j}) & = \text{Log}(\mathbf{z}_{ij}^{-1}\hat{\mathbf{z}}_{ij}) \\ & = \text{Log}(\mathbf{z}_{ij}^{-1}\mathbf{x}_{i}^{-1}\mathbf{x}_{j}) \\ & = \text{Log}(\text{Exp}(-\xi_{ij})\text{Exp}(-\xi_{i})\text{Exp}(\xi_{j}))
\end{aligned}
\end{equation}
위 식을 보면 $\mathbf{z}_{ij}$ 안에 $\xi_{i}, \xi_{j}$ 파라미터가 exponential mapping으로 연결되어 있는 것을 알 수 있다. 위 식 두 번째 라인의 공식에 왼쪽 섭동(perturbation) 모델을 적용하여 증분량을 표현하면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{e}_{ij}(\xi_{i} + \Delta \xi_{i}, \xi_{j} + \Delta \xi_{j}) & = \text{Log}(\hat{\mathbf{z}}_{ij}^{-1}\mathbf{x}_{i}^{-1}\text{Exp}(-\Delta \xi_{i})\text{Exp}(\Delta \xi_{j})\mathbf{x}_{j})
\end{aligned} \label{eq:rel10}
\end{equation}
위 식에서 증분량 항을 왼쪽 또는 오른쪽으로 이동시켜야 $\mathbf{e} + \mathbf{J}\Delta\xi$ 꼴로 항이 정리된다. 이를 수행하기 위해 아래와 같은 adjoint matrix of SE(3)의 성질을 이용해야 한다. Adjoint martix에 대한 자세한 내용은 해당 포스트를 참조하면 된다. \begin{equation} \begin{aligned} \text{Exp}(\text{Ad}_{\mathbf{T}} \xi) = \mathbf{T} \text{Exp}(\xi) \mathbf{T}^{-1} \end{aligned} \end{equation}
위 식을 $\mathbf{T} \rightarrow \mathbf{T}^{-1}$에 대한 식으로 변형하면 다음과 같다. \begin{equation} \begin{aligned} \text{Exp}(\text{Ad}_{\mathbf{T}^{-1}} \xi) = \mathbf{T}^{-1} \text{Exp}(\xi) \mathbf{T} \end{aligned} \end{equation}
그리고 정리하면 다음과 같은 공식을 얻을 수 있다. \begin{equation} \begin{aligned} \text{Exp}(\xi) \mathbf{T} = \mathbf{T} \text{Exp}(\text{Ad}_{\mathbf{T}^{-1}} \xi) \end{aligned} \label{eq:rel11} \end{equation}
(\ref{eq:rel11})을 사용하면 (\ref{eq:rel10})의 중간에 있는 $\text{Exp}(\cdot)\text{Exp}(\cdot)$ 항을 오른쪽 또는 왼쪽으로 이동시킬 수 있다. 본 포스트에서는 오른쪽으로 이동시키는 과정에 대해 설명한다. 이를 $\Delta \xi_{i}, \Delta \xi_{j}$ 별로 각각 전개하면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{e}_{ij}(\xi_{i} + \Delta \xi_{i}, \xi_{j}) & = \text{Log}(\hat{\mathbf{z}}_{ij}^{-1}\mathbf{x}_{i}^{-1}\text{Exp}(-\Delta \xi_{i}) \mathbf{x}_{j}) \\ &= \text{Log}(\mathbf{z}_{ij}^{-1}\mathbf{x}_{i}^{-1}\mathbf{x}_{j} \text{Exp}(-\text{Ad}_{\mathbf{x}_{j}^{-1}}\Delta \xi_{i})) \quad \cdots \text{[1]} \\
\mathbf{e}_{ij}(\xi_{i}, \xi_{j} + \Delta \xi_{j}) & = \text{Log}(\hat{\mathbf{z}}_{ij}^{-1}\mathbf{x}_{i}^{-1}\text{Exp}(\Delta \xi_{j})\mathbf{x}_{j}) \\ &= \text{Log}(\mathbf{z}_{ij}^{-1}\mathbf{x}_{i}^{-1}\mathbf{x}_{j} \text{Exp}(\text{Ad}_{\mathbf{x}_{j}^{-1}}\Delta \xi_{j})) \quad \cdots \text{[2]}
\end{aligned} \label{eq:rel21}
\end{equation}
이를 간단하게 표현하기 위해 치환하여 표시하면 $[1], [2]$는 각각 다음과 같다.
\begin{equation}
\begin{aligned}
\text{Log}( \text{Exp}(\mathbf{a}) \text{Exp}(\mathbf{b})) \quad \cdots \text{[1]} \\
\text{Log}(\text{Exp}(\mathbf{a}) \text{Exp}(\mathbf{c})) \quad \cdots \text{[2]}
\end{aligned} \label{eq:rel13}
\end{equation}
- $\text{Exp}(\mathbf{a}) = \mathbf{z}_{ij}^{-1}\mathbf{x}_{i}^{-1}\mathbf{x}_{j}$: 변환행렬을 exponential 항으로 표현한 모습. 앞서 (\ref{eq:rel22}) 정의에 따라 $\mathbf{a} = \mathbf{e}_{ij}(\xi_{i}, \xi_{j})$이다.
- $\mathbf{b} = -\text{Ad}_{\mathbf{x}_{j}^{-1}}\Delta \xi_{i}$
- $\mathbf{c} = \text{Ad}_{\mathbf{x}_{j}^{-1}}\Delta \xi_{j}$
위 식은 오른쪽 BCH 근사를 사용하여 정리할 수 있다.
오른쪽 BCH 근사는 다음과 같다. \begin{equation} \begin{aligned} \text{Exp}(\xi)\text{Exp}(\Delta \xi) & = \text{Exp}(\xi + \mathcal{J}^{-1}_{r}\Delta \xi) \\ \text{Exp}(\xi + \Delta \xi) & = \text{Exp}(\xi) \text{Exp}(\mathcal{J}_{r}\Delta \xi)\\ \end{aligned} \end{equation}
자세한 내용은 Lie theory 개념 정리 포스팅을 참조하면 된다.
BCH 근사를 사용하여 (\ref{eq:rel13})을 정리하면 아래와 같다.
\begin{equation}
\begin{aligned}
\text{Log}(\text{Exp}(\mathbf{a}) \text{Exp}(\mathbf{b}) ) & = \text{Log}(\text{Exp}(\mathbf{a} + \mathcal{J}^{-1}_{r}\mathbf{b})) \\ & = \mathbf{a} + \mathcal{J}^{-1}_{r}\mathbf{b} \quad \cdots \text{[1]} \\
\text{Log}(\text{Exp}(\mathbf{a}) \text{Exp}(\mathbf{c}) ) & = \text{Log}(\text{Exp}(\mathbf{a} + \mathcal{J}^{-1}_{r}\mathbf{c})) \\ & = \mathbf{a} + \mathcal{J}^{-1}_{r}\mathbf{c} \quad \cdots \text{[2]}
\end{aligned}
\end{equation}
최종적으로 치환을 풀고 $\Delta \xi_{i}, \Delta \xi_{j}$ 식을 합하여 다시 쓰면 (\ref{eq:rel14})의 SE(3) 버전 공식이 된다.
\begin{equation}
\boxed{ \begin{aligned}
\mathbf{e}_{ij}(\xi_{i} + \Delta \xi_{i}, \xi_{j} + \Delta \xi_{j}) & = \mathbf{a} + \mathcal{J}^{-1}_{r}\mathbf{b} + \mathcal{J}^{-1}_{r}\mathbf{c} \\& = \mathbf{e}_{ij}(\xi_{i} , \xi_{j} ) - \mathcal{J}^{-1}_{r}\text{Ad}_{\mathbf{x}_{j}^{-1}}\Delta \xi_{i} + \mathcal{J}^{-1}_{r}\text{Ad}_{\mathbf{x}_{j}^{-1}}\Delta \xi_{j} \\ & = \mathbf{e}_{ij}(\xi_{i} , \xi_{j} ) + \frac{\partial \mathbf{e}_{ij} }{\partial \Delta \xi_{i}} \Delta \xi_{i} + \frac{\partial \mathbf{e}_{ij} }{\partial \Delta \xi_{j}} \Delta \xi_{j}
\end{aligned} }
\end{equation}
따라서 최종적인 relative pose 에러의 SE(3) 버전 자코비안은 다음과 같다.
\begin{equation}
\boxed{ \begin{aligned}
& \frac{\partial \mathbf{e}_{ij} }{\partial \Delta \xi_{i}} = -\mathcal{J}^{-1}_{r}\text{Ad}_{\mathbf{x}_{j}^{-1}} \in \mathbb{R}^{6\times6} \\
& \frac{\partial \mathbf{e}_{ij} }{\partial \Delta \xi_{j}} = \mathcal{J}^{-1}_{r}\text{Ad}_{\mathbf{x}_{j}^{-1}} \in \mathbb{R}^{6\times6}
\end{aligned} }
\end{equation}
이 때, $\mathcal{J}^{-1}_{r}$은 식이 복잡하여 일반적으로 이를 아래와 같이 근사하여 사용하여 사용하거나 $\mathbf{I}_{6}$로 놓고 사용하기도 한다.
\begin{equation}
\begin{aligned}
\mathcal{J}^{-1}_{r} \approx \mathbf{I}_{6} + \frac{1}{2} \begin{bmatrix} [\mathbf{w}]_{\times} & [\mathbf{v}]_{\times} \\ \mathbf{0} & [\mathbf{w}]_{\times} \end{bmatrix} \in \mathbb{R}^{6\times6}
\end{aligned}
\end{equation}
만약 $\mathcal{J}^{-1}_{r} = \mathbf{I}_{6}$로 가정하고 최적화를 수행하면 연산량 측면에서 감소 효과는 있지만 최적화 성능은 위와 같이 근사한 자코비안을 사용하는 방법이 미세하게 우세하다. 자세한 내용은 Visual SLAM 입문 챕터 11장을 참조하면 된다.
5.2. Code implementations
- g2o 코드: edge_se3_expmap.cpp#L55
- 위 g2o 코드에서는 에러를 $\mathbf{e}_{ij}=\mathbf{x}_{j}^{-1}\mathbf{z}_{ij}\mathbf{x}_{i}$로 정의하여 자코비안이 위 설명과 약간 달라지게 된다.
- $\frac{\partial \mathbf{e}_{ij} }{\partial \Delta \xi_{i}} = \mathcal{J}^{-1}_{l}\text{Ad}_{\mathbf{x}_{j}^{-1}\mathbf{z}_{ij}}$
- $\frac{\partial \mathbf{e}_{ij} }{\partial \Delta \xi_{j}} = -\mathcal{J}^{-1}_{r}\text{Ad}_{\mathbf{x}_{i}^{-1}\mathbf{z}_{ij}^{-1}}$
- 이는 (\ref{eq:rel21})에서 $\Delta \xi_{i}$는 왼쪽으로 항을 넘겨서 정리하고 $\Delta \xi_{j}$는 오른쪽으로 항을 넘겨서 정리한 후 합쳐준 형식과 동일하다.
- 또한 $\mathcal{J}^{-1}_{l} \approx \mathbf{I}_{6}, \mathcal{J}^{-1}_{r} \approx \mathbf{I}_{6}$으로 근사한 것으로 보인다. 따라서 실제 구현된 코드는 다음과 같다.
- $\frac{\partial \mathbf{e}_{ij} }{\partial \Delta \xi_{i}} \approx \text{Ad}_{\mathbf{x}_{j}^{-1}\mathbf{z}_{ij}}$
- $\frac{\partial \mathbf{e}_{ij} }{\partial \Delta \xi_{j}} \approx -\text{Ad}_{\mathbf{x}_{i}^{-1}\mathbf{z}_{ij}^{-1}}$
6. Line reprojection error
Line reprojection 에러는 plücker coordinate로 표현한 3차원 공간 상의 직선을 최적화할 때 사용하는 에러이다. Plücker coordinate에 대한 자세한 내용은 Plücker Coordinate 개념 정리 포스트를 참조하면 된다.
NOMENCLATURE of line reprojection error
- $\mathcal{T}_{cw} \in \mathbb{R}^{6\times6}$: Plücker 직선의 변환 행렬
- $\mathcal{K}_{L}$: 직선의 내부 파라미터 행렬(line intrinsic matrix)
- $\mathbf{U} \in SO(3)$: 3차원 직선의 회전 행렬
- $\mathbf{W} \in SO(2)$: 3차원 직선이 원점과 떨어진 거리 정보를 포함하는 행렬
- $\boldsymbol{\theta} \in \mathbb{R}^{3}$: SO(3) 회전행렬에 대응하는 파라미터
- $\theta \in \mathbb{R}$: SO(2) 회전행렬에 대응하는 파라미터
- $\mathbf{u}_{i}$: $i$번째 열벡터(column vector)
- $\mathcal{X} = [\delta_{\boldsymbol{\theta}}, \delta_\xi ]$: 상태 변수
- $\delta_{\boldsymbol{\theta}} = [ \boldsymbol{\theta}^{\intercal}, \theta ] \in \mathbb{R}^{4}$: orthonormal 표현법의 상태 변수
- $\delta_{\xi} = [\delta \xi] \in se(3)$: Lie theory를 통한 업데이트 방법은 해당 링크를 참조하면 된다
- $\oplus$ : 상태 변수 $\delta_{\boldsymbol{\theta}}, \delta_\xi$를 한 번에 업데이트할 수 있는 연산자.
- $\mathbf{J} = \frac{\partial \mathbf{e}_{l}}{\partial \mathcal{X}} = \frac{\partial \mathbf{e}_{l}}{\partial [\delta_{\boldsymbol{\theta}}, \delta_\xi]}$
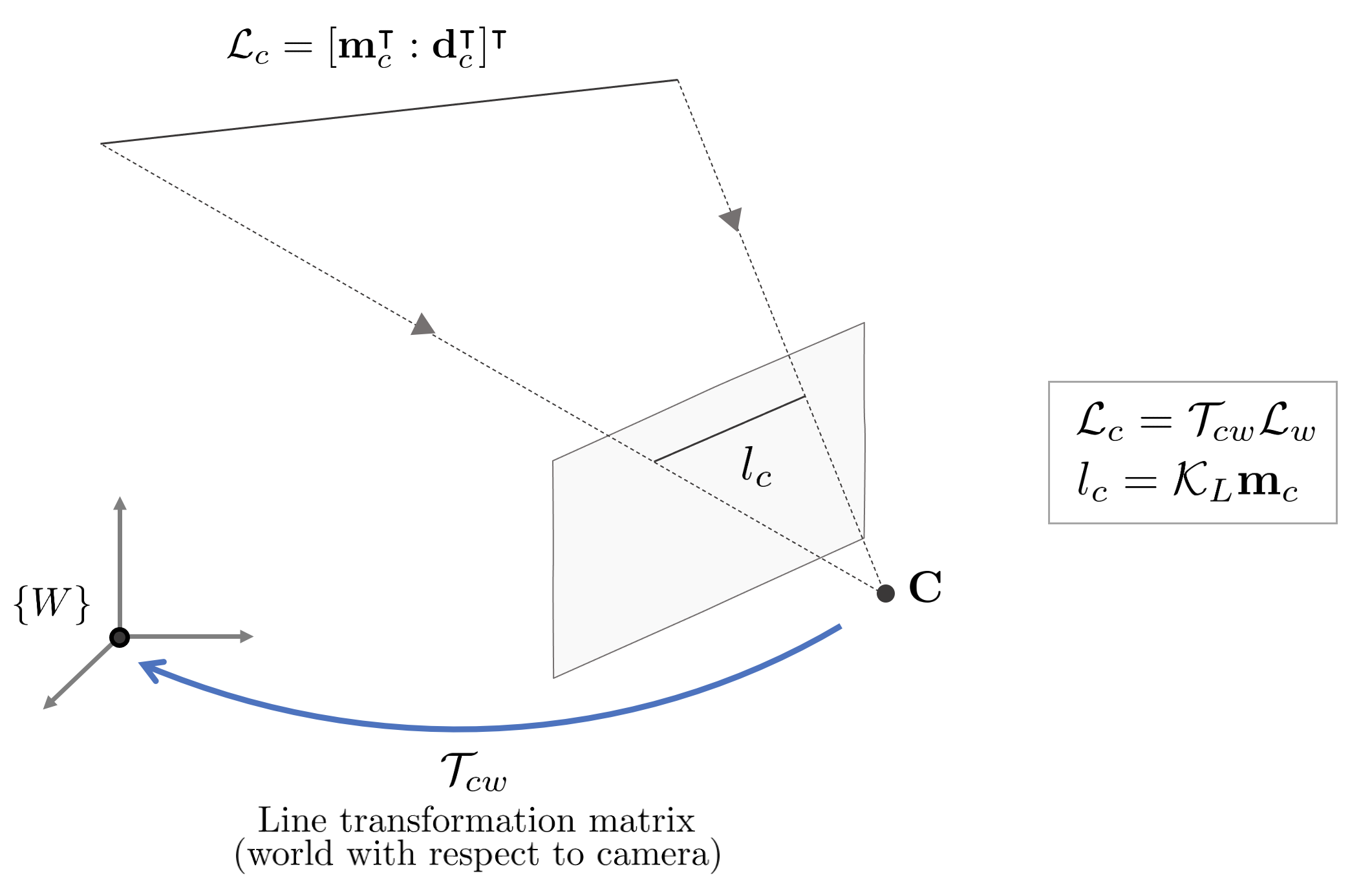
3차원 공간 상의 직선은 Plücker Coordinate를 사용하여 6차원 열벡터로 표현할 수 있다.
\begin{equation}
\begin{aligned}
\mathcal{L} & = [\mathbf{m}^{\intercal} : \mathbf{d}^{\intercal}]^{\intercal} = [ m_{x} : m_{y} : m_{z} : d_{x} : d_{y} : d_{z}]^{\intercal}
\end{aligned}
\end{equation}
앞서 설명한 $[\mathbf{d} : \mathbf{m}]$ 순서와 달리 Plücker Coordinate를 활용한 논문에서는 대부분 $[\mathbf{m} : \mathbf{d}]$ 순서를 사용하기 때문에 본 섹션에서도 해당 순서로 직선을 표현한다. 해당 직선 표현법은 스케일 모호성을 가지고 있기 때문에(up to scale) 5자유도를 가지며 $\mathbf{m}, \mathbf{d}$은 단위 벡터가 아니어도 두 벡터 값의 비율에 의해 직선을 유일하게 표현할 수 있다.
6.1. Line Transformation and projection
월드 좌표계에서 본 직선을 $\mathcal{L}_{w}$라고 하면 이를 카메라 좌표계에서 봤을 경우 다음과 같이 변환할 수 있다.
\begin{equation}
\begin{aligned}
\mathcal{L}_{c} & = \begin{bmatrix} \mathbf{m}_{c} \\ \mathbf{d}_{c} \end{bmatrix} = \mathcal{T}_{cw}\mathcal{L}_{w} = \begin{bmatrix} \mathbf{R}_{cw} & \mathbf{t}^{\wedge}\mathbf{R}_{cw} \\ 0 & \mathbf{R}_{cw} \end{bmatrix} \begin{bmatrix} \mathbf{m}_{w} \\ \mathbf{d}_{w} \end{bmatrix}
\end{aligned}
\end{equation}
해당 직선을 이미지 평면 상에 프로젝션시키면 다음과 같다.
\begin{equation}
\begin{aligned}
l_{c} & = \begin{bmatrix} l_{1} \\ l_{2} \\ l_{3} \end{bmatrix} = \mathcal{K}_{L}\mathbf{m}_{c} = \begin{bmatrix} f_{y} && \\ &f_{x} & \\ -f_{y}c_{x} & -f_{x}c_{y} & f_{x}f_{y} \end{bmatrix} \begin{bmatrix} m_{x} \\ m_{y} \\ m_{z} \end{bmatrix}
\end{aligned}
\end{equation}
$\mathcal{K}_{L}$는 $\mathcal{P} = [\det(\mathbf{N}) \mathbf{N}^{-\intercal} | \mathbf{n}^{\wedge} \mathbf{N} ]$에서 $\mathbf{P} = K [ \mathbf{I} | \mathbf{0}]$인 경우를 의미한다. 따라서 $\mathcal{P} = [\det(\mathbf{K})\mathbf{K}^{-\intercal} | \mathbf{0}]$이 되므로 $\mathcal{L}$의 $\mathbf{d}$ 항이 0으로 소거된다. 따라서 $\mathbf{K} = \begin{bmatrix} f_x & & c_x \\ & f_y & c_y \\ &&1 \end{bmatrix}$ 일 때 다음과 같은 식이 유도된다.
\begin{equation}
\begin{aligned}
\mathcal{K}_{L} = \det(\mathbf{K})\mathbf{K}^{-\intercal} = \begin{bmatrix} f_{y} && \\ &f_{x} & \\ -f_{y}c_{x} & -f_{x}c_{y} & f_{x}f_{y} \end{bmatrix} \in \mathbb{R}^{3\times3}
\end{aligned}
\end{equation}
6.2. Line reprojection error
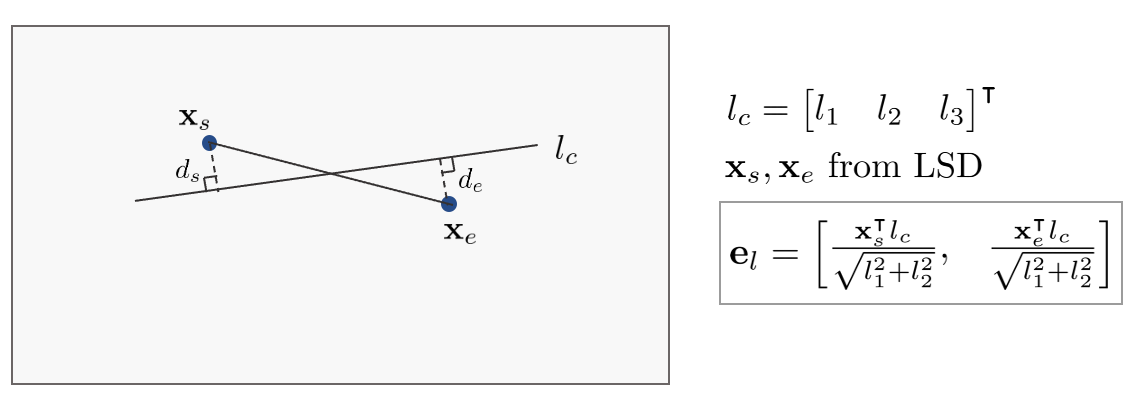
직선의 reprojection 에러 $\mathbf{e}_{l}$은 다음과 같이 나타낼 수 있다.
\begin{equation}
\begin{aligned}
\mathbf{e}_{l} = \begin{bmatrix} d_{s}, \ d_{e} \end{bmatrix}= \begin{bmatrix} \frac{\mathbf{x}_{s}^{\intercal}l_{c}}{\sqrt{l_{1}^{2} + l_{2}^{2}}}, & \frac{\mathbf{x}_{e}^{\intercal}l_{c}}{\sqrt{l_{1}^{2} + l_{2}^{2}}}\end{bmatrix} \in \mathbb{R}^{2}
\end{aligned}
\end{equation}
이는 점과 직선 사이의 거리 공식을 통해 나타낼 수 있다. 이 때, $\{\mathbf{x}_{s}, \mathbf{x}_{e}\}$는 각각 line feature extracture(e.g., LSD)를 사용하여 추출한 직선의 시작점과 끝점을 의미한다. 즉, $\mathcal{l}_{c}$가 모델링을 통해 구한 예측값이고 $\mathbf{x}_{s}, \mathbf{x}_{e}$를 잇는 직선이 센서 데이터를 통해 측정한 관측값이 된다.
6.3. Orthonormal representation
앞서 구한 $\mathbf{e}_{l}$를 사용하여 BA 최적화를 수행할 때 Plücker Coordinate 표현법을 그대로 사용하게 되면 문제가 발생한다. Plücker Coordinate는 항상 $\mathbf{m}^{\intercal}\mathbf{d} = 0$이라는 Klein quadric 제약조건을 만족해야 하기 때문에 5자유도를 가지므로 직선을 표현할 수 있는 최소 파라미터 개수인 4개의 비해 over-parameterized 되어 있다. Over-parameterized된 표현법의 단점은 다음과 같다.
- 중복되는 파라미터를 계산해야 하기 때문에 최적화 수행 시 연산량이 증가한다.
- 추가적인 자유도로 인해 수치적인 불안정성(numerical instability) 문제가 야기될 수 있다.
- 파라미터가 업데이트될 때마다 항상 제약조건을 만족하는 지 체크해줘야 한다.
따라서 직선을 최적화 할 때는 일반적으로 최소 파라미터인 4자유도로 변경하기 위해 orthonormal 표현법을 사용한다. 즉, 직선을 표현할 때는 Plücker Coordinate를 사용하지만 최적화를 수행할 때는 orthonormal 표현법으로 변형한 뒤 최적값을 업데이트하고 다시 Plücker Coordinate로 돌아오는 방식을 취한다.
Orthonormal 표현법은 다음과 같다. 3차원 공간 상의 직선은 항상 다음과 같이 표현 가능하다.
\begin{equation}
\begin{aligned}
(\mathbf{U}, \mathbf{W}) \in SO(3) \times SO(2)
\end{aligned}
\end{equation}
임의의 Plücker 직선 $\mathcal{L} = [\mathbf{m}^{\intercal} : \mathbf{d}^{\intercal}]^{\intercal}$은 이와 일대일 대응하는 $(\mathbf{U}, \mathbf{W})$를 항상 가지고 있으며 이러한 표현 방법을 orthonormal 표현법이라고 한다. 월드 상의 한 직선 $\mathcal{L}_{w} = [ \mathbf{m}_{w}^{\intercal} : \mathbf{d}_{w}^{\intercal}]^{\intercal}$이 주어졌을 때 $\mathcal{L}_{w}$을 QR decomposition 함으로써 $(\mathbf{U}, \mathbf{W})$구할 수 있다.
\begin{equation}
\begin{aligned}
\begin{bmatrix} \mathbf{m}_{w} \ | \ \mathbf{d}_{w} \end{bmatrix}= \mathbf{U} \begin{bmatrix} w_{1} & 0\\ 0& w_{2} \\0 & 0 \end{bmatrix}, \quad \text{with set: } \mathbf{W} = \begin{bmatrix} w_{1} & -w_{2} \\ w_{2} & w_{1} \end{bmatrix}
\end{aligned}
\end{equation}
이 때, 상삼각행렬(upper triangle matrix) $\mathbf{R}$의 $(1,2)$ 원소는 Plücker 제약조건(Klein quadric)으로 인해 항상 0이 된다. $\mathbf{U}, \mathbf{W}$는 각각 3차원, 2차원 회전행렬을 의미하므로 $\mathbf{U} = \mathbf{R}(\boldsymbol{\theta}), \mathbf{W} = \mathbf{R}(\theta)$와 같이 나타낼 수 있다.
\begin{equation}
\begin{aligned}
\mathbf{R}(\boldsymbol{\theta}) & = \mathbf{U} = \begin{bmatrix} \mathbf{u}_{1} & \mathbf{u}_{2} & \mathbf{u}_{3} \end{bmatrix} = \begin{bmatrix} \frac{\mathbf{m}_{w}}{\left\| \mathbf{m}_{w} \right\|} & \frac{\mathbf{d}_{w}}{\left\| \mathbf{d}_{w} \right\|} & \frac{\mathbf{m}_{w} \times \mathbf{d}_{w}}{\left\| \mathbf{m}_{w} \times \mathbf{d}_{w} \right\|} \end{bmatrix} \\
\mathbf{R}(\theta) & = \mathbf{W} = \begin{bmatrix} w_{1} & -w_{2} \\ w_{2} & w_{1} \end{bmatrix} = \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} \\
& = \frac{1}{\sqrt{\left\| \mathbf{m}_{w} \right\|^{2} + \left\| \mathbf{d}_{w} \right\|^{2}}} \begin{bmatrix} \left\| \mathbf{m}_{w} \right\| & \left\| \mathbf{d}_{w} \right\| \\ -\left\| \mathbf{d}_{w} \right\| & \left\| \mathbf{m}_{w} \right\| \end{bmatrix}
\end{aligned}
\end{equation}
실제 최적화를 수행할 때는 $\mathbf{U} \leftarrow \mathbf{U}\mathbf{R}(\boldsymbol{\theta}), \mathbf{W} \leftarrow \mathbf{W}\mathbf{R}(\theta)$과 같이 업데이트된다. 따라서 orthonormal 표현법은 3차원 공간 상의 직선을 $\delta_{\boldsymbol{\theta}} = [ \boldsymbol{\theta}^{\intercal}, \theta ] \in \mathbb{R}^{4}$를 통해 4자유도로 표현할 수 있다. 최적화를 통해 업데이트된 $[ \boldsymbol{\theta}^{\intercal}, \theta ]$는 다음과 같이 $\mathcal{L}_{w}$로 변환된다.
\begin{equation}
\begin{aligned}
\mathcal{L}_{w} = \begin{bmatrix} w_{1} \mathbf{u}_{1}^{\intercal} & w_{2} \mathbf{u}_{2}^{\intercal} \end{bmatrix}
\end{aligned}
\end{equation}
6.4. Error function formulation
직선에 대한 reprojection 에러 $\mathbf{e}_{l}$를 최적화하기 위해서는 Gauss-Newton(GN), Levenberg-Marquardt(LM) 등의 비선형 최소제곱법을 사용하여 반복적으로(iterative) 최적 변수를 업데이트해야 한다. reprojection 에러를 사용하여 에러 함수를 표현하면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{E}_{l}(\mathcal{X}) & = \sum_{i}\sum_{j} \left\| \mathbf{e}_{l,ij} \right\|^{2} \\
\end{aligned}
\end{equation}
\begin{equation}
\begin{aligned}
\mathcal{X}^{*} &= \arg\min_{\mathcal{X}^{*}} \mathbf{E}_{l}(\mathcal{X}) \\
& = \arg\min_{\mathcal{X}^{*}} \sum_{i}\sum_{j} \left\| \mathbf{e}_{l,ij} \right\|^{2} \\
& = \arg\min_{\mathcal{X}^{*}} \sum_{i}\sum_{j} \mathbf{e}_{l,ij}^{\intercal}\mathbf{e}_{l,ij} \\
\end{aligned} \label{eq:line10}
\end{equation}
$\mathbf{E}_{l}(\mathcal{X}^{*})$를 만족하는 $\left\|\mathbf{e}_{l}(\mathcal{X}^{*})\right\|^{2}$를 non-linear least squares를 통해 반복적으로 계산할 수 있다. 작은 증분량 $\Delta \mathcal{X}$를 반복적으로 $\mathcal{X}$에 업데이트함으로써 최적의 상태를 찾는다.
\begin{equation}
\begin{aligned}
\arg\min_{\mathcal{X}^{*}} \mathbf{E}_{l}(\mathcal{X} + \Delta \mathcal{X}) & = \arg\min_{\mathcal{X}^{*}} \sum_{i}\sum_{j} \left\|\mathbf{e}_{l}(\mathcal{X} +\Delta \mathcal{X})\right\|^{2}
\end{aligned}
\end{equation}
엄밀하게 말하면 상태 증분량 $\Delta \mathcal{X}$은 SE(3) 변환행렬을 포함하므로 $\oplus$ 연산자를 통해 기존 상태 $\mathcal{X}$에 더해지는게 맞지만 표현의 편의를 위해 $+$ 연산자를 사용하였다.
\begin{equation}
\begin{aligned}
\mathbf{e}_{l}( \mathcal{X} \oplus \Delta \mathcal{X})
\quad \rightarrow \quad\mathbf{e}_{l}(\mathcal{X} + \Delta \mathcal{X})
\end{aligned}
\end{equation}
위 식은 테일러 1차 근사를 통해 다음과 같이 표현이 가능하다.
\begin{equation}
\begin{aligned}
\mathbf{e}_{l}(\mathcal{X} + \Delta \mathcal{X}) & \approx \mathbf{e}_{l}(\mathcal{X}) + \mathbf{J}\Delta \mathcal{X} \\ & = \mathbf{e}_{l}(\mathcal{X}) + \mathbf{J}_{\boldsymbol{\theta}} \Delta \delta_{\boldsymbol{\theta}} +\mathbf{J}_{\xi} \Delta \delta_\xi \\
& = \mathbf{e}_{l}(\mathcal{X}) + \frac{\partial \mathbf{e}_{l}}{\partial \delta_{\boldsymbol{\theta}}} \Delta \delta_{\boldsymbol{\theta}} + \frac{\partial \mathbf{e}_{l}}{\partial \delta_\xi}\Delta \delta_\xi \\
\end{aligned}
\end{equation}
\begin{equation}
\begin{aligned}
\arg\min_{\mathcal{X}^{*}} \mathbf{E}_{l}(\mathcal{X} + \Delta \mathcal{X}) & \approx \arg\min_{\mathcal{X}^{*}} \sum_{i}\sum_{j} \left\|\mathbf{e}_{l}(\mathcal{X}) + \mathbf{J}\Delta \mathcal{X} \right\|^{2} \\
\end{aligned}
\end{equation}
이를 미분하여 최적의 증분량 $\Delta \mathcal{X}^{*}$ 값을 구하면 다음과 같다. 자세한 유도 과정은 본 섹션에서는 생략한다. 유도 과정에 대해 자세히 알고 싶으면 이전 섹션을 참조하면 된다.
\begin{equation}
\begin{aligned}
& \mathbf{J}^{\intercal}\mathbf{J} \Delta \mathcal{X}^{*} = -\mathbf{J}^{\intercal}\mathbf{e} \\
& \mathbf{H}\Delta \mathcal{X}^{*} = - \mathbf{b} \\
\end{aligned}
\end{equation}
6.4.1. The analytical jacobian of 3d line
이전 섹션에서 설명한 것처럼 비선형 최적화를 수행하기 위해서는 $\mathbf{J}$를 계산해야 한다. $\mathbf{J}$는 다음과 같이 구성되어 있다.
\begin{equation}
\begin{aligned}
& \mathbf{J} = [ \mathbf{J}_{\boldsymbol{\theta}}, \mathbf{J}_{\xi} ]
\end{aligned}
\end{equation}
$[ \mathbf{J}_{\boldsymbol{\theta}}, \mathbf{J}_{\xi} ]$는 다음과 같이 전개할 수 있다.
\begin{equation}
\begin{aligned}
& \mathbf{J}_{\boldsymbol{\theta}} = \frac{\partial \mathbf{e}_{l}}{\partial \delta_{\boldsymbol{\theta}}} = \frac{\partial \mathbf{e}_{l}}{\partial l} \frac{\partial l}{\partial \mathcal{L}_{c}} \frac{\partial \mathcal{L}_{c}}{\partial \mathcal{L}_{w}} \frac{\partial \mathcal{L}_{w}}{\partial \delta_{\boldsymbol{\theta}}} \\
& \mathbf{J}_{\xi} = \frac{\partial \mathbf{e}_{l}}{\partial \delta_{\xi}} = \frac{\partial \mathbf{e}_{l}}{\partial l} \frac{\partial l}{\partial \mathcal{L}_{c}} \frac{\partial \mathcal{L}_{c}}{\partial \delta_{\xi}}
\end{aligned}
\end{equation}
$\frac{\partial \mathbf{e}_{l}}{\partial l}$는 다음과 같이 구할 수 있다. 이 때, $l$은 벡터이고 $l_{i}$는 스칼라임에 유의한다.
\begin{equation}
\boxed{ \begin{aligned}
\frac{\partial \mathbf{e}_{l}}{\partial l} = \frac{1}{\sqrt{l_{1}^{2} + l_{2}^{2}}} \begin{bmatrix} x_{s} - \frac{l_{1} \mathbf{x}_{s}l}{\sqrt{l_{1}^{2} + l_{2}^{2}}} & y_{s} - \frac{l_{2} \mathbf{x}_{s}l}{\sqrt{l_{1}^{2} + l_{2}^{2}}} & 1 \\
x_{e} - \frac{l_{1} \mathbf{x}_{e}l}{\sqrt{l_{1}^{2} + l_{2}^{2}}} & y_{e} - \frac{l_{2} \mathbf{x}_{e}l}{\sqrt{l_{1}^{2} + l_{2}^{2}}} & 1 \end{bmatrix} \in \mathbb{R}^{2\times3}
\end{aligned} }
\end{equation}
$\frac{\partial l}{\partial \mathcal{L}_{c}}$는 다음과 같이 구할 수 있다.
\begin{equation}
\boxed{ \begin{aligned}
\frac{\partial l}{\partial \mathcal{L}_{c}} = \frac{\partial \mathcal{K}_{L}\mathbf{m}_{c}}{\partial \mathcal{L}_{c}} = \begin{bmatrix} \mathcal{K}_{L} & \mathbf{0}_{3\times3} \end{bmatrix} = \begin{bmatrix} f_{y} && & 0 &0&0 \\ &f_{x} & & 0 &0&0 \\ -f_{y}c_{x} & -f_{x}c_{y} & f_{x}f_{y} & 0 &0&0 \end{bmatrix} \in \mathbb{R}^{3\times6}
\end{aligned} }
\end{equation}
$\frac{\partial \mathcal{L}_{c}}{\partial \mathcal{L}_{w}}$는 다음과 같이 구할 수 있다.
\begin{equation}
\boxed{ \begin{aligned}
\frac{\partial \mathcal{L}_{c}}{\partial \mathcal{L}_{w}} = \frac{\partial \mathcal{T}_{cw}\mathcal{L}_{w}}{\partial \mathcal{L}_{w}}= \mathcal{T}_{cw} = \begin{bmatrix} \mathbf{R}_{cw} & \mathbf{t}^{\wedge}\mathbf{R}_{cw} \\ 0 & \mathbf{R}_{cw} \end{bmatrix} \in \mathbb{R}^{6\times6}
\end{aligned} }
\end{equation}
orthonormal 표현법에 대한 자코비안 $\frac{\partial \mathcal{L}_{w}}{\partial \delta_{\boldsymbol{\theta}}}$는 다음과 같이 구할 수 있다.
\begin{equation}
\boxed{ \begin{aligned}
\frac{\partial \mathcal{L}_{w}}{\partial \delta_{\boldsymbol{\theta}}} = \begin{bmatrix} \mathbf{0}_{3\times1} & -w_{1}\mathbf{u}_{3} & w_{1}\mathbf{u}_{2} & -w_{2}\mathbf{u}_{1} \\ w_{2}\mathbf{u}_{3} & \mathbf{0}_{3\times1} & -w_{2}\mathbf{u}_{1} & w_{1}\mathbf{u}_{2} \end{bmatrix} \in \mathbb{R}^{6 \times 4}
\end{aligned} }
\end{equation}
카메라 포즈에 대한 자코비안 $\frac{\partial \mathcal{L}_{c}}{\partial \delta_{\xi}}$는 다음과 같이 구할 수 있다.
\begin{equation}
\boxed{ \begin{aligned}
\frac{\partial \mathcal{L}_{c}}{\partial \delta_{\xi}} = \begin{bmatrix} -(\mathbf{R}\mathbf{m})^{\wedge} - (\mathbf{t}^{\wedge} \mathbf{Rd})^{\wedge} & -(\mathbf{Rd})^{\wedge} \\ -(\mathbf{Rd})^{\wedge} & \mathbf{0}_{3\times3} \end{bmatrix} \in \mathbb{R}^{6 \times 6}
\end{aligned} }
\end{equation}
6.5. Code implementations
- Structure PLP SLAM 코드: g2o/se3/pose_opt_edge_line3d_orthonormal.h#L62
- Structure PLP SLAM 코드2: g2o/se3/pose_opt_edge_line3d_orthonormal.h#L81
'Fundamental' 카테고리의 다른 글
| 3D 강체 변환(Rigid Body Transformation) 개념 정리 (6) | 2023.01.24 |
|---|---|
| [SLAM] 에러와 자코비안 정리(Errors and Jacobians) 정리 Part 2 (3) | 2023.01.13 |
| Quaternion kinematics for the error-state Kalman filter 내용 정리 Part 3 (8) | 2022.10.10 |
| [SLAM] 파티클 필터(Particle Filter) 개념 정리 (1) | 2022.10.07 |
| Quaternion kinematics for the error-state Kalman filter 내용 정리 Part 2 (5) | 2022.08.31 |





