 A L I D A
A L I D A
본 포스트는 필자가 Kalman filter 공부하면서 배운 내용을 정리한 포스트이다.
Kalman filter를 이해하는데 필요한 기반 지식은 확률 이론(Probability Theory) 개념 정리 포스팅을 참조하면 된다.
Particle filter에 대해 알고 싶으면 파티클 필터(Particle Filter) 개념 정리 포스팅을 참조하면 된다.
Recursive bayes filter
상태 추정 문제란 일반적으로 주어진 제어입력과 관측값이 있을 때 이를 바탕으로 현재 상태(e.g., 위치, 속도, 회전 등)를 추정하는 것을 의미한다. 제어입력과 관측값이 주어졌을 때 현재 상태 $\mathbf{x}_{t}$의 믿을만한 정도, 또는 $\mathbf{x}_{t}$에 대한 Belief $\text{bel}(\mathbf{x}_{t})$은 같이 정의한다.
\begin{equation}
\begin{aligned}
\text{bel}(\mathbf{x}_{t}) = p(\mathbf{x}_{t} \ | \ \mathbf{z}_{1:t}, \mathbf{u}_{1:t})
\end{aligned}
\end{equation}
- $\mathbf{x}_{t}$ : t 시간에서 상태 변수
- $\mathbf{z}_{1:t} = \{\mathbf{z}_{1}, \cdots, \mathbf{z}_{t} \}$ : 1~t 시간에서 관측값
- $\mathbf{u}_{1:t} = \{\mathbf{u}_{1}, \cdots, \mathbf{u}_{t} \}$ : 1~t 시간에서 제어입력
- $\text{bel}(\mathbf{x}_{t})$ : Belief of $\mathbf{x}_{t}$라고 불리며 시작 시간부터 $t$초까지 센서를 통한 관측 $ \mathbf{z}_{1:t}$과 제어입력 $\mathbf{u}_{1:t}$으로 인해 현재 로봇이 $\mathbf{x}_{t}$에 위치할 확률(믿을만한 정도)을 의미
$\text{bel}(\cdot)$은 bayesian rule에 따라 표현되고 전개되기 때문에 bayes filter라고도 불린다. 위 식을 markov assumption과 bayesian rule을 사용하여 전개하면 재귀적인 필터를 유도할 수 있고 이를 recursive bayes filter라고 한다.
\begin{equation}
\begin{aligned}
& \text{bel}(\mathbf{x}_{t}) = \eta \cdot p( \mathbf{z}_{t} \ | \ \mathbf{x}_{t})\overline{\text{bel}}(\mathbf{x}_{t}) \\
& \overline{\text{bel}}(\mathbf{x}_{t}) = \int p(\mathbf{x}_{t} \ | \ \mathbf{x}_{t-1}, \mathbf{u}_{t})\text{bel}(\mathbf{x}_{t-1}) d \mathbf{x}_{t-1}\\
\end{aligned}
\end{equation}
- $\eta = 1/p(\mathbf{z}_{t}|\mathbf{z}_{1:t-1}, \mathbf{u}_{1:t})$ : 확률분포의 넓이를 1로 정규화하여 확률분포의 정의를 유지시켜주는 값
- $p( \mathbf{z}_{t} \ | \ \mathbf{x}_{t})$ : 관측 모델(observation model)
- $\int p(\mathbf{x}_{t} \ | \ \mathbf{x}_{t-1},\mathbf{u}_{t}) d \mathbf{x}_{t-1}$ : 모션 모델(motion model)
Recursive bayes filter는 위와 같이 이전 스텝의 $\text{bel}(\mathbf{x}_{t-1})$로부터 현재 스텝의 $\text{bel}(\mathbf{x}_{t})$를 구할 수 있으므로 재귀 필터라고 부른다.
Derivation of recursive bayes filter
Recursive bayes filter의 수식은 다음과 같이 유도된다.
\begin{equation}
\begin{aligned}
\text{bel}(\mathbf{x}_{t}) & = p( \mathbf{x}_{t} | \mathbf{z}_{1:t}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}, \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) d\mathbf{x}_{t-1}\\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) d\mathbf{x}_{t-1} \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t-1}) d\mathbf{x}_{t-1} \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \text{bel}(\mathbf{x}_{t-1}) d \mathbf{x}_{t-1} \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \overline{\text{bel}}(\mathbf{x}_{t-1}) \\
\end{aligned}
\end{equation}
Step 1:
\begin{equation}
\begin{aligned}
\text{bel}(\mathbf{x}_{t}) & = p({\color{Cyan} \mathbf{x}_{t} } | {\color{Cyan} \mathbf{z}_{1:t}}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p({\color{Cyan} \mathbf{z}_{t}} | {\color{Cyan} \mathbf{x}_{t}}, \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p( {\color{Cyan} \mathbf{x}_{t}} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t})
\end{aligned}
\end{equation}
Bayesian rule을 적용한다. $p(x|y) = \frac{p(y|x)p(x)}{p(y)}$
Step 2:
\begin{equation}
\begin{aligned}
\text{bel}(\mathbf{x}_{t}) & = p( \mathbf{x}_{t} | \mathbf{z}_{1:t}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | {\color{Cyan} \mathbf{x}_{t}, \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t} } ) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | {\color{Cyan} \mathbf{x}_{t} } ) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
\end{aligned}
\end{equation}
현재 상태는 바로 이전 상태에만 의존성을 지니는 Markov Assumption을 적용한다.
Step 3:
\begin{equation}
\begin{aligned}
\text{bel}(\mathbf{x}_{t}) & = p( \mathbf{x}_{t} | \mathbf{z}_{1:t}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}, \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot {\color{Cyan} p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) } \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot {\color{Cyan} \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) d\mathbf{x}_{t-1} } \\
\end{aligned}
\end{equation}
총합의 법칙(Law of total probability) 또는 Marginalization를 적용한다. $p(x) = \int_{y} p(x|y) \cdot p(y) dy$
Step 4:
\begin{equation}
\begin{aligned}
\text{bel}(\mathbf{x}_{t}) & = p( \mathbf{x}_{t} | \mathbf{z}_{1:t}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}, \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},{\color{Cyan} \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t} } ) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) d\mathbf{x}_{t-1}\\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1}, {\color{Cyan} \mathbf{u}_{t} } ) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) d\mathbf{x}_{t-1} \\
\end{aligned}
\end{equation}
현재 상태는 바로 이전 상태에만 의존성을 지니는 Markov Assumption을 적용한다.
Step 5:
\begin{equation}
\begin{aligned}
\text{bel}(\mathbf{x}_{t}) & = p( \mathbf{x}_{t} | \mathbf{z}_{1:t}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}, \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) d\mathbf{x}_{t-1}\\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, {\color{Cyan} \mathbf{u}_{1:t} } ) d\mathbf{x}_{t-1} \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, {\color{Cyan} \mathbf{u}_{1:t-1} } ) d\mathbf{x}_{t-1} \\
\end{aligned}
\end{equation}
현재 상태는 바로 이전 상태에만 의존성을 지니는 Markov Assumption을 적용한다.
Step 6:
\begin{equation}
\begin{aligned}
\text{bel}(\mathbf{x}_{t}) & = p( \mathbf{x}_{t} | \mathbf{z}_{1:t}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}, \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) d\mathbf{x}_{t-1}\\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) d\mathbf{x}_{t-1} \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \cdot {\color{Cyan} p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t-1})} d\mathbf{x}_{t-1} \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \cdot {\color{Cyan} \text{bel}(\mathbf{x}_{t-1}) } d\mathbf{x}_{t-1} \\
\end{aligned}
\end{equation}
$p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t-1})$는 $\text{bel}(\mathbf{x}_{t-1})$의 정의와 동일하므로 치환한다.
Step 7:
\begin{equation}
\begin{aligned}
\text{bel}(\mathbf{x}_{t}) & = p( \mathbf{x}_{t} | \mathbf{z}_{1:t}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}, \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot p( \mathbf{x}_{t} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) d\mathbf{x}_{t-1}\\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t}) d\mathbf{x}_{t-1} \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \cdot p(\mathbf{x}_{t-1} | \mathbf{z}_{1:t-1}, \mathbf{u}_{1:t-1}) d\mathbf{x}_{t-1} \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot {\color{Cyan} \int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \cdot \text{bel}(\mathbf{x}_{t-1}) d \mathbf{x}_{t-1} } \\
& = \eta \cdot p(\mathbf{z}_{t} | \mathbf{x}_{t}) \cdot {\color{Cyan} \overline{\text{bel}}(\mathbf{x}_{t-1}) }\\
\end{aligned}
\end{equation}
$\int_{\mathbf{x}_{t-1}} p( \mathbf{x}_{t} | \mathbf{x}_{t-1},\mathbf{u}_{t}) \cdot \text{bel}(\mathbf{x}_{t-1}) d \mathbf{x}_{t-1}$를 $\overline{\text{bel}}(\mathbf{x}_{t-1})$로 치환한다.
Gaussian belief case
$\text{bel}(\mathbf{x}_{t})$가 가우시안 분포를 따르는 경우 이를 특별히 칼만 필터(kalman filter)라고 한다.
\begin{equation}
\begin{aligned}
& \overline{\text{bel}}(\mathbf{x}_{t}) \sim \mathcal{N}(\hat{\mathbf{x}}_{t|t-1}, \mathbf{P}_{t|t-1}) \quad \text{(Kalman Filter Prediction)} \\
& \text{bel}(\mathbf{x}_{t}) \sim \mathcal{N}(\hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t}) \quad \text{(Kalman Filter Correction)}
\end{aligned}
\end{equation}
평균과 분산은 $(\hat{\mathbf{x}}$, $\mathbf{P})$ 또는 $(\hat{\boldsymbol{\mu}}, \boldsymbol{\Sigma})$로 표현하기도 한다. 이는 표기법만 다를 뿐 동일한 의미를 지닌다.
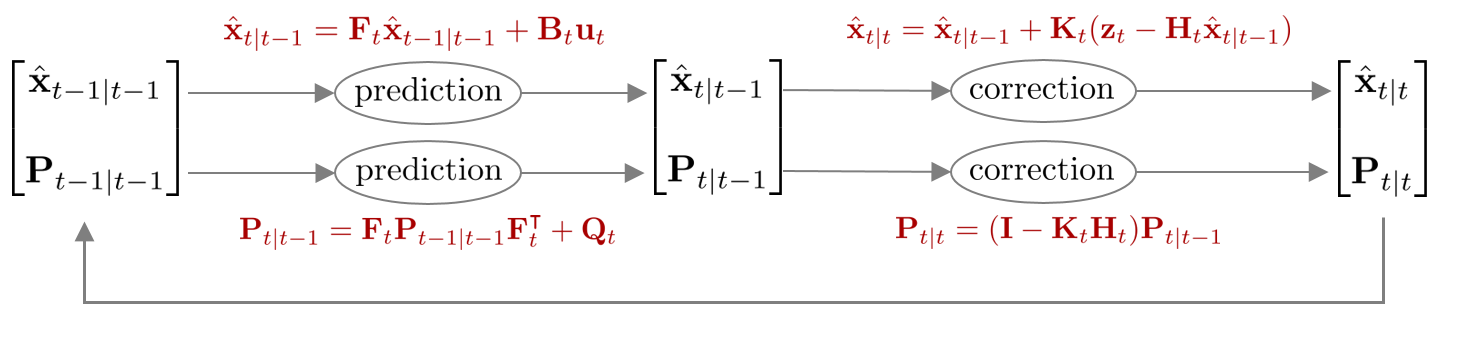
Kalman filter (KF)
NOMENCLATURE of kalman filter
- 스칼라는 일반 소문자로 표기한다 e.g., a
- 벡터는 굵은 소문자로 표기한다 e.g., $\mathbf{a}$
- 행렬은 굵은(bold) 대문자로 표기한다 e.g., $\mathbf{R}$
- prediction: $\overline{\text{bel}}(\mathbf{x}_{t}) \sim \mathcal{N}(\hat{\mathbf{x}}_{t|t-1}, {\mathbf{P}}_{t|t-1})$
- $\hat{\mathbf{x}}_{t|t-1}$ : $t-1$ 스텝의 correction 값이 주어졌을 때 $t$ 스텝의 평균. 일부 문헌은 $\mathbf{x}^{-}_{t}$로도 표기함.
- $\hat{\mathbf{P}}_{t|t-1}$ : $t-1$ 스텝의 correction 값이 주어졌을 때 $t$ 스텝의 공분산. 일부 문헌은 $\mathbf{P}^{-}_{t}$로도 표기함.
- correction: $\text{bel}(\mathbf{x}_{t}) \sim \mathcal{N}(\hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t})$
- $\hat{\mathbf{x}}_{t|t}$ : $t$ 스텝의 prediction 값이 주어졌을 때 $t$ 스텝의 평균. 일부 문헌은 $\mathbf{x}^{+}_{t}$로도 표기함.
- $\hat{\mathbf{P}}_{t|t}$ : $t$ 스텝의 prediction 값이 주어졌을 때 $t$ 스텝의 공분산. 일부 문헌은 $\mathbf{P}^{+}_{t}$로도 표기함.
시간 $t$에 로봇의 위치를 $\mathbf{x}_{t}$, 로봇의 센서로 부터 관측한 값을 $\mathbf{z}_{t}$, 로봇의 제어입력을 $\mathbf{u}_{t}$라고 하면 이를 통해 모션 모델(motion model)과 관측 모델(observation model)을 정의할 수 있다. 이 때, 모션 모델과 관측 모델은 선형이어야(linear model) 한다는 제약조건이 있다. 모션 모델과 관측 모델은 다음과 같다.
\begin{equation}
\begin{aligned}
& \text{Motion Model: } & \mathbf{x}_{t} = \mathbf{F}_{t}\mathbf{x}_{t-1} + \mathbf{B}_{t}\mathbf{u}_{t} + \mathbf{w}_{t} \\
& \text{Observation Model: } & \mathbf{z}_{t} = \mathbf{H}_{t}\mathbf{x}_{t} + \mathbf{v}_{t}
\end{aligned}
\end{equation}
- $\mathbf{x}_{t}$: 모델의 상태 변수(state variable)
- $\mathbf{u}_{t}$: 모델의 입력(input)
- $\mathbf{z}_{t}$: 모델의 관측값(measurement)
- $\mathbf{F}_{t}$: 모델의 상태천이(state transition) 행렬
- $\mathbf{B}_{t}$: 모델에 입력 $\mathbf{u}_{t}$가 주어졌을 때 $\mathbf{u}_{t}$를 상태 변수로 변환해주는 행렬
- $\mathbf{H}_{t}$: 모델의 관측(observation) 행렬
- $\mathbf{w}_{t} \sim \mathcal{N}(0, \mathbf{Q}_{t})$: 모션 모델의 노이즈. $\mathbf{Q}_{t}$는 $\mathbf{w}_{t}$의 공분산 행렬을 의미한다.
- $\mathbf{v}_{t} \sim \mathcal{N}(0, \mathbf{R}_{t})$: 관측 모델의 노이즈. $\mathbf{R}_{t}$는 $\mathbf{v}_{t}$의 공분산 행렬을 의미한다.
확률변수가 모두 가우시안 분포를 따른다고 가정하면 $p(\mathbf{x}_{t} \ | \ \mathbf{x}_{t-1}, \mathbf{u}_{t}), p(\mathbf{z}_{t} \ | \ \mathbf{x}_{t})$는 다음과 같이 나타낼 수 있다.
\begin{equation} \label{eq:kf1}
\begin{aligned}
& p(\mathbf{x}_{t} \ | \ \mathbf{x}_{t-1}, \mathbf{u}_{t}) && \sim \mathcal{N}(\mathbf{F}_{t}\mathbf{x}_{t-1} + \mathbf{B}_{t}\mathbf{u}_{t}, \mathbf{Q}_{t}) \\
& && = \frac{1}{ \sqrt{\text{det}(2\pi \mathbf{Q}_t)}}\exp\bigg( -\frac{1}{2}(\mathbf{x}_{t} -\mathbf{F}_{t}\mathbf{x}_{t-1}-\mathbf{B}_{t}\mathbf{u}_t)^{\intercal}\mathbf{Q}_t^{-1}(\mathbf{x}_{t}-\mathbf{F}_{t}\mathbf{x}_{t-1}-\mathbf{B}_{t}\mathbf{u}_{t}) \bigg)\\
\end{aligned}
\end{equation}
\begin{equation} \label{eq:kf2}
\begin{aligned}
& p(\mathbf{z}_{t} \ | \ \mathbf{x}_{t}) && \sim \mathcal{N}(\mathbf{H}_{t}\mathbf{x}_{t}, \mathbf{R}_{t}) \\
& && = \frac{1}{ \sqrt{\text{det}(2\pi \mathbf{R}_t)}}\exp\bigg( -\frac{1}{2}(\mathbf{z}_{t}-\mathbf{H}_{t}\mathbf{x}_{t})^{\intercal}\mathbf{R}_{t}^{-1}(\mathbf{z}_{t}-\mathbf{H}_{t}\mathbf{x}_{t}) \bigg)
\end{aligned}
\end{equation}
다음으로 칼만 필터를 통해 구해야 하는 $\overline{\text{bel}}(\mathbf{x}_{t}), \text{bel}(\mathbf{x}_{t})$은 아래와 같이 나타낼 수 있다.
\begin{equation} \label{eq:kf3}
\begin{aligned}
& \overline{\text{bel}}(\mathbf{x}_{t}) = \int p(\mathbf{x}_{t} \ | \ \mathbf{x}_{t-1}, \mathbf{u}_{t})\text{bel}(\mathbf{x}_{t-1}) d \mathbf{x}_{t-1} \sim \mathcal{N}(\hat{\mathbf{x}}_{t|t-1}, \mathbf{P}_{t|t-1}) \\
& \text{bel}(\mathbf{x}_{t}) = \eta \cdot p( \mathbf{z}_{t} \ | \ \mathbf{x}_{t})\overline{\text{bel}}(\mathbf{x}_{t}) \sim \mathcal{N}(\hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t})
\end{aligned}
\end{equation}
칼만 필터는 prediction 스텝에서 이전 스텝의 posterior 값과 모션 모델을 사용하여 예측값 $\overline{\text{bel}}(\mathbf{x}_{t})$을 먼저 구한 후 correction 스텝에서 예측값과 관측 모델을 사용하여 보정된 값 $\text{bel}(\mathbf{x}_{t})$을 구하는 방식으로 동작한다. (\ref{eq:kf1}), (\ref{eq:kf2})를 (\ref{eq:kf3})에 대입하여 정리하면 prediction, correction 스텝의 평균과 공분산 $(\hat{\mathbf{x}}_{t|t-1}, \mathbf{P}_{t|t-1}), (\hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t})$을 각각 구할 수 있다. 자세한 유도 과정은 [13]의 3.2.4 "Mathematical Derivation of the KF" 섹션을 참조하면 된다
초기값 $\text{bel}(\mathbf{x}_{0})$은 다음과 같이 주어진다.
\begin{equation}
\begin{aligned}
\text{bel}(\mathbf{x}_{0}) \sim \mathcal{N}(\hat{\mathbf{x}}_{0}, \mathbf{P}_{0})
\end{aligned}
\end{equation}
- $\hat{\mathbf{x}}_{0}$: 일반적으로 0으로 설정한다
- $\mathbf{P}_{0}$ : 일반적으로 작은 값(<1e-2)으로 설정한다.
Prediction step
Prediction은 $\overline{\text{bel}}(\mathbf{x}_{t})$를 구하는 과정을 말한다. $\overline{\text{bel}}(\mathbf{x}_{t})$는 가우시안 분포를 따르므로 평균 $\hat{\mathbf{x}}_{t|t-1}$과 분산 $\mathbf{P}_{t|t-1}$을 각각 구해보면 아래와 같이 구할 수 있다.
\begin{equation}
\boxed{ \begin{aligned}
& \hat{\mathbf{x}}_{t|t-1} = \mathbf{F}_{t}\hat{\mathbf{x}}_{t-1|t-1} + \mathbf{B}_{t}\mathbf{u}_{t} \\
& \mathbf{P}_{t|t-1} = \mathbf{F}_{t}\mathbf{P}_{t-1|t-1}\mathbf{F}_{t}^{\intercal} + \mathbf{Q}_{t}
\end{aligned} }
\end{equation}
Correction step
Correction은 $\text{bel}(\mathbf{x}_{t})$를 구하는 과정을 말한다. $\text{bel}(\mathbf{x}_{t})$ 또한 가우시안 분포를 따르므로 평균 $\hat{\mathbf{x}}_{t|t}$과 분산 $\mathbf{P}_{t|t}$을 각각 구해보면 다음과 같다. 이 때, $\mathbf{K}_{t}$는 칼만 게인(kalman gain)을 의미한다.
\begin{equation}
\boxed{ \begin{aligned}
& \mathbf{K}_{t} = \mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal}(\mathbf{H}_{t}\mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal} + \mathbf{R}_{t})^{-1} \\
& \hat{\mathbf{x}}_{t|t} = \hat{\mathbf{x}}_{t|t-1} + \mathbf{K}_{t}( \mathbf{z}_{t} - \mathbf{H}_{t}\hat{\mathbf{x}}_{t|t-1}) \\
& \mathbf{P}_{t|t} = (\mathbf{I} - \mathbf{K}_{t}\mathbf{H}_{t})\mathbf{P}_{t|t-1}
\end{aligned} }
\end{equation}
Summary
칼만 필터를 함수로 표현하면 다음과 같다.
\begin{equation}
\boxed{ \begin{aligned}
& \text{KalmanFilter}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{P}_{t-1|t-1}, \mathbf{u}_{t}, \mathbf{z}_{t}) \{ \\
& \quad\quad \text{(Prediction Step)}\\
& \quad\quad \hat{\mathbf{x}}_{t|t-1} = \mathbf{F}_{t}\hat{\mathbf{x}}_{t-1|t-1} + \mathbf{B}_{t}\mathbf{u}_{t} \\
& \quad\quad \mathbf{P}_{t|t-1} = \mathbf{F}_{t}\mathbf{P}_{t-1|t-1}\mathbf{F}_{t}^{\intercal} + \mathbf{Q}_{t} \\
& \\
& \quad\quad \text{(Correction Step)} \\
& \quad\quad \mathbf{K}_{t} = \mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal}(\mathbf{H}_{t}\mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal} + \mathbf{R}_{t})^{-1} \\
& \quad\quad \hat{\mathbf{x}}_{t|t} = \hat{\mathbf{x}}_{t|t-1} + \mathbf{K}_{t}( \mathbf{z}_{t} - \mathbf{H}_{t}\hat{\mathbf{x}}_{t|t-1}) \\
& \quad\quad \mathbf{P}_{t|t} = (\mathbf{I} - \mathbf{K}_{t}\mathbf{H}_{t})\mathbf{P}_{t|t-1} \\
& \quad\quad \text{return} \ \ \hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t} \\
& \}
\end{aligned} }
\end{equation}
Extended kalman filter (EKF)
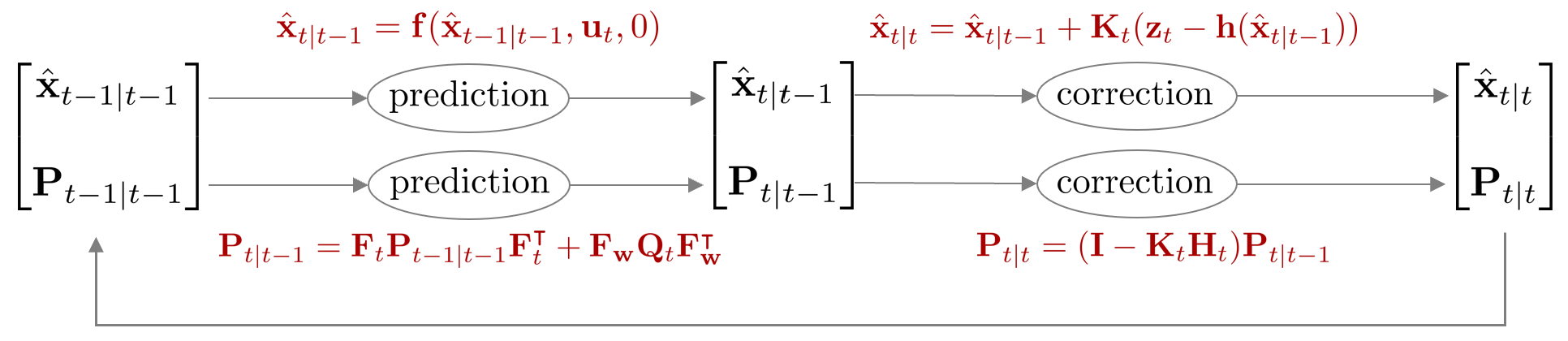
칼만 필터는 모션 모델과 관측 모델이 선형이라는 가정 하에 상태를 추정한다. 하지만 현실세계의 대부분의 현상들은 비선형으로 모델링되므로 앞서 정의한 칼만 필터를 그대로 적용하면 정상적으로 동작하지 않는다. 비선형의 모션 모델과 관측 모델에서도 칼만 필터를 사용하기 위해 확장칼만필터(extended kalman filter, EKF)가 제안되었다. EKF는 테일러 1차 근사(talyor 1st approximation)을 사용하여 비선형 모델을 선형 모델로 근사한 후 칼만 필터를 적용하는 방법을 사용한다. EKF에서 모션 모델과 관측 모델은 다음과 같다.
\begin{equation}
\begin{aligned}
& \text{Motion Model: } & \mathbf{x}_{t} = \mathbf{f}(\mathbf{x}_{t-1}, \mathbf{u}_{t} , \mathbf{w}_{t}) \\
& \text{Observation Model: } & \mathbf{z}_{t} = \mathbf{h}(\mathbf{x}_{t}, \mathbf{v}_{t})
\end{aligned}
\end{equation}
- $\mathbf{x}_{t}$: 모델의 상태 변수(state variable)
- $\mathbf{u}_{t}$: 모델의 입력(input)
- $\mathbf{z}_{t}$: 모델의 관측값(measurement)
- $\mathbf{f}(\cdot)$: 비선형 모션(motion) 모델 함수
- $\mathbf{h}(\cdot)$: 비선형 관측(observation) 모델 함수
- $\mathbf{w}_{t} \sim \mathcal{N}(0, \mathbf{Q}_{t})$: 모션 모델의 노이즈. $\mathbf{Q}_{t}$는 $\mathbf{w}_{t}$의 공분산 행렬을 의미
- $\mathbf{v}_{t} \sim \mathcal{N}(0, \mathbf{R}_{t})$: 관측 모델의 노이즈. $\mathbf{R}_{t}$는 $\mathbf{v}_{t}$의 공분산 행렬을 의미
위 식에서 $\mathbf{f}(\cdot)$은 비선형 모션 모델을 의미하고 $\mathbf{h}(\cdot)$은 비선형 관측 모델을 의미한다. $\mathbf{f}(\cdot), \mathbf{h}(\cdot)$에 각각 1차 테일러 근사를 수행하면 다음과 같다.
\begin{equation} \label{eq:20}
\begin{aligned}
& \mathbf{x}_{t} \approx \mathbf{f}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{u}_{t} , 0 ) + \mathbf{F}_{t}(\mathbf{x}_{t-1} - \hat{\mathbf{x}}_{t-1|t-1}) + \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t} \\
& \mathbf{z}_{t} \approx \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0) + \mathbf{H}_{t}(\mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1}) + \mathbf{H}_{\mathbf{v}}\mathbf{v}_{t}
\end{aligned}
\end{equation}
이 때, $\mathbf{F}_{t}$는 $\hat{\mathbf{x}}_{t-1|t-1}$에서 계산한 모션 모델의 자코비안 행렬을 의미하며 $\mathbf{H}_{t}$는 $\hat{\mathbf{x}}_{t|t-1}$에서 계산한 관측 모델의 자코비안 행렬을 의미한다. 그리고 $\mathbf{F}_{\mathbf{w}}, \mathbf{H}_{\mathbf{v}}$는 각각 $\mathbf{w}_{t}=0, \mathbf{v}_{t}=0$에서 노이즈에 대한 자코비안 행렬을 의미한다. 자코비안에 대한 자세한 내용은 해당 포스트 를 참조하면된다.
\begin{equation}
\begin{aligned}
& \mathbf{F}_{t} = \frac{\partial \mathbf{f}}{\partial \mathbf{x}_{t-1}}\bigg|_{\mathbf{x}_{t-1}=\hat{\mathbf{x}}_{t-1|t-1}} & \mathbf{F}_{\mathbf{w}} = \frac{\partial \mathbf{f}}{\partial \mathbf{w}_{t}} \bigg|_{\substack{ & \mathbf{x}_{t-1}=\hat{\mathbf{x}}_{t-1|t-1} \\ & \mathbf{w}_{t}=0}} \\
\end{aligned}
\end{equation}
\begin{equation}
\begin{aligned}
& \mathbf{H}_{t} = \frac{\partial \mathbf{h}}{\partial \mathbf{x}_{t}}\bigg|_{\mathbf{x}_{t}=\hat{\mathbf{x}}_{t|t-1}} & \mathbf{H}_{\mathbf{v}} = \frac{\partial \mathbf{h}}{\partial \mathbf{v}_{t}} \bigg|_{\substack{& \mathbf{x}_{t}=\hat{\mathbf{x}}_{t|t-1} \\ & \mathbf{v}_{t} = 0}} \\
\end{aligned}
\end{equation}
($\ref{eq:20})$ 식을 전개하면 다음과 같다.
\begin{equation} \label{eq:ekf1}
\boxed{ \begin{aligned}
\mathbf{x}_{t} & = \mathbf{F}_{t}\mathbf{x}_{t-1} +
\mathbf{f}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{u}_{t} , 0 ) - \mathbf{F}_{t} \hat{\mathbf{x}}_{t-1|t-1} + \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t} \\
& = \mathbf{F}_{t}\mathbf{x}_{t-1} + \tilde{\mathbf{u}}_{t} + \tilde{\mathbf{w}}_{t}
\end{aligned} }
\end{equation}
- $\tilde{\mathbf{u}}_{t} = \mathbf{f}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{u}_{t} , 0 ) - \mathbf{F}_{t} \hat{\mathbf{x}}_{t-1|t-1}$
- $\tilde{\mathbf{w}}_{t} = \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t} \sim \mathcal{N}(0, \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal})$
\begin{equation} \label{eq:ekf2}
\boxed{ \begin{aligned}
\mathbf{z}_{t} & = \mathbf{H}_{t}\mathbf{x}_{t} + \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0) - \mathbf{H}_{t}\hat{\mathbf{x}}_{t|t-1} + \mathbf{H}_{\mathbf{v}}\mathbf{v}_{t} \\
& = \mathbf{H}_{t}\mathbf{x}_{t} + \tilde{\mathbf{z}}_{t} + \tilde{\mathbf{v}}_{t}
\end{aligned} }
\end{equation}
- $\tilde{\mathbf{z}}_{t} = \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0) - \mathbf{H}_{t}\hat{\mathbf{x}}_{t|t-1}$
- $\tilde{\mathbf{v}}_{t} = \mathbf{H}_{\mathbf{v}}\mathbf{v}_{t} \sim \mathcal{N}(0, \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t} \mathbf{H}_{\mathbf{v}}^{\intercal})$
확률변수가 모두 가우시안 분포를 따른다고 가정하면 $p(\mathbf{x}_{t} \ | \ \mathbf{x}_{t-1}, \mathbf{u}_{t}), p(\mathbf{z}_{t} \ | \ \mathbf{x}_{t})$는 다음과 같이 나타낼 수 있다.
\begin{equation}
\begin{aligned}
& p(\mathbf{x}_{t} \ | \ \mathbf{x}_{t-1}, \mathbf{u}_{t}) && \sim \mathcal{N}(\mathbf{F}_{t}\mathbf{x}_{t-1} + \tilde{\mathbf{u}}_{t}, \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal} ) \\
& && = \frac{1}{ \sqrt{\text{det}(2\pi \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal} )}}\exp\bigg( -\frac{1}{2}(\mathbf{x}_{t} - \mathbf{F}_{t}\mathbf{x}_{t-1} - \tilde{\mathbf{u}}_{t})^{\intercal}( \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal} )^{-1}(\mathbf{x}_{t} - \mathbf{F}_{t}\mathbf{x}_{t-1} - \tilde{\mathbf{u}}_{t}) \bigg)\\
\end{aligned}
\end{equation}
\begin{equation} \label{eq:ekf4}
\begin{aligned}
& p(\mathbf{z}_{t} \ | \ \mathbf{x}_{t}) && \sim \mathcal{N}(\mathbf{H}_{t}\mathbf{x}_{t} + \tilde{\mathbf{z}}_{t}, \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t} \mathbf{H}_{\mathbf{v}}^{\intercal} ) \\
& && = \frac{1}{ \sqrt{\text{det}(2\pi \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t} \mathbf{H}_{\mathbf{v}}^{\intercal} )}}\exp\bigg( -\frac{1}{2}(\mathbf{z}_{t} - \mathbf{H}_{t}\mathbf{x}_{t} - \tilde{\mathbf{z}}_{t})^{\intercal}( \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t} \mathbf{H}_{\mathbf{v}}^{\intercal} )^{-1}(\mathbf{z}_{t}- \mathbf{H}_{t}\mathbf{x}_{t} - \tilde{\mathbf{z}}_{t}) \bigg)
\end{aligned}
\end{equation}
$\mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal}$는 선형화된 모션 모델의 노이즈를 의미하며 $\mathbf{H}_{\mathbf{v}}\mathbf{R}_{t} \mathbf{H}_{\mathbf{v}}^{\intercal}$은 선형화된 관측 모델의 노이즈를 의미한다. 다음으로 칼만 필터를 통해 구해야 하는 $\overline{\text{bel}}(\mathbf{x}_{t}), \text{bel}(\mathbf{x}_{t})$은 아래와 같이 나타낼 수 있다.
\begin{equation}
\begin{aligned}
& \overline{\text{bel}}(\mathbf{x}_{t}) = \int p(\mathbf{x}_{t} \ | \ \mathbf{x}_{t-1}, \mathbf{u}_{t})\text{bel}(\mathbf{x}_{t-1}) d \mathbf{x}_{t-1} \sim \mathcal{N}(\hat{\mathbf{x}}_{t|t-1}, \mathbf{P}_{t|t-1}) \\
& \text{bel}(\mathbf{x}_{t}) = \eta \cdot p( \mathbf{z}_{t} \ | \ \mathbf{x}_{t})\overline{\text{bel}}(\mathbf{x}_{t}) \sim \mathcal{N}(\hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t})
\end{aligned}
\end{equation}
EKF 또한 KF와 동일하게 prediction에서 이전 스텝의 값과 모션 모델을 사용하여 예측값 $\overline{\text{bel}}(\mathbf{x}_{t})$을 먼저 구한 후 correction에서 관측값과 관측 모델을 사용하여 보정된 값 $\text{bel}(\mathbf{x}_{t})$을 구하는 방식으로 동작한다. $p(\mathbf{x}_{t} | \mathbf{x}_{t-1}, \mathbf{u}_{t})$, $p(\mathbf{z}_{t} | \mathbf{x}_{t})$를 위 식에 대입하여 정리하면 prediction, correction 스텝의 평균과 공분산 $(\hat{\mathbf{x}}_{t|t-1}, \mathbf{P}_{t|t-1}), (\hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t})$을 각각 구할 수 있다. 자세한 유도 과정은 [13]의 3.2.4 "Mathematical Derivation of the KF" 섹션을 참조하면 된다.
초기값 $\text{bel}(\mathbf{x}_{0})$은 다음과 같이 주어진다.
\begin{equation}
\begin{aligned}
\text{bel}(\mathbf{x}_{0}) \sim \mathcal{N}(\hat{\mathbf{x}}_{0}, \mathbf{P}_{0})
\end{aligned}
\end{equation}
- $\hat{\mathbf{x}}_{0}$: 일반적으로 0으로 설정한다
- $\mathbf{P}_{0}$ : 일반적으로 작은 값(<1e-2)으로 설정한다.
Prediction step
Prediction은 $\overline{\text{bel}}(\mathbf{x}_{t})$를 구하는 과정을 말한다. 공분산 행렬을 구할 때 선형화된 자코비안 행렬 $\mathbf{F}_{t}$가 사용된다.
\begin{equation}
\boxed{ \begin{aligned}
& \hat{\mathbf{x}}_{t|t-1} = \mathbf{f}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{u}_{t} , 0 ) \\
& \mathbf{P}_{t|t-1} = \mathbf{F}_{t}\mathbf{P}_{t-1|t-1}\mathbf{F}_{t}^{\intercal} + \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal}
\end{aligned} }
\end{equation}
Correction step
Correction은 $\text{bel}(\mathbf{x}_{t})$를 구하는 과정을 말한다. 칼만 게인과 공분산 행렬을 구할 때 선형화된 자코비안 행렬 $\mathbf{H}_{t}$가 사용된다.
\begin{equation} \label{eq:ekf3}
\boxed{ \begin{aligned}
& \mathbf{K}_{t} = \mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal}(\mathbf{H}_{t}\mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal} + \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t} \mathbf{H}_{\mathbf{v}}^{\intercal} )^{-1} \\
& \hat{\mathbf{x}}_{t|t} = \hat{\mathbf{x}}_{t|t-1} + \mathbf{K}_{t}( \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0)) \\
& \mathbf{P}_{t|t} = (\mathbf{I} - \mathbf{K}_{t}\mathbf{H}_{t})\mathbf{P}_{t|t-1}
\end{aligned} }
\end{equation}
Summary
확장칼만필터를 함수로 표현하면 다음과 같다.
\begin{equation}
\boxed{ \begin{aligned}
& \text{ExtendedKalmanFilter}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{P}_{t-1|t-1}, \mathbf{u}_{t}, \mathbf{z}_{t}) \{ \\
& \quad\quad \text{(Prediction Step)}\\
& \quad\quad \hat{\mathbf{x}}_{t|t-1} = \mathbf{f}_{t}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{u}_{t} , 0 ) \\
& \quad\quad \mathbf{P}_{t|t-1} = \mathbf{F}_{t}\mathbf{P}_{t-1|t-1}\mathbf{F}_{t}^{\intercal} + \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal} \\
& \\
& \quad\quad \text{(Correction Step)} \\
& \quad\quad \mathbf{K}_{t} = \mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal}(\mathbf{H}_{t}\mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal} + \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t} \mathbf{H}_{\mathbf{v}}^{\intercal} )^{-1} \\
& \quad\quad \hat{\mathbf{x}}_{t|t} = \hat{\mathbf{x}}_{t|t-1} + \mathbf{K}_{t}( \mathbf{z}_{t} - \mathbf{h}_{t}(\hat{\mathbf{x}}_{t|t-1}, 0)) \\
& \quad\quad \mathbf{P}_{t|t} = (\mathbf{I} - \mathbf{K}_{t}\mathbf{H}_{t})\mathbf{P}_{t|t-1} \\
& \quad\quad \text{return} \ \ \hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t} \\
& \}
\end{aligned} }
\end{equation}
Error-state kalman filter (ESKF)
NOMENCLATURE of error-state kalman filter
- prediction: $\overline{\text{bel}}(\delta \mathbf{x}_{t}) \sim \mathcal{N}(\delta \hat{\mathbf{x}}_{t|t-1}, {\mathbf{P}}_{t|t-1})$
- $\delta \hat{\mathbf{x}}_{t|t-1}$ : $t-1$ 스텝의 correction 값이 주어졌을 때 $t$ 스텝의 평균. 일부 문헌은 $\delta \mathbf{x}^{-}_{t}$로도 표기함.
- $\hat{\mathbf{P}}_{t|t-1}$ : $t-1$ 스텝의 correction 값이 주어졌을 때 $t$ 스텝의 공분산. 일부 문헌은 $ \mathbf{P}^{-}_{t}$로도 표기함.
- correction: $\text{bel}(\delta \mathbf{x}_{t}) \sim \mathcal{N}(\delta \hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t})$
- $\delta \hat{\mathbf{x}}_{t|t}$ : $t$ 스텝의 prediction 값이 주어졌을 때 $t$ 스텝의 평균. 일부 문헌은 $\delta \mathbf{x}^{+}_{t}$로도 표기함.
- $\hat{\mathbf{P}}_{t|t}$ : $t$ 스텝의 prediction 값이 주어졌을 때 $t$ 스텝의 공분산. 일부 문헌은 $\mathbf{P}^{+}_{t}$로도 표기함.
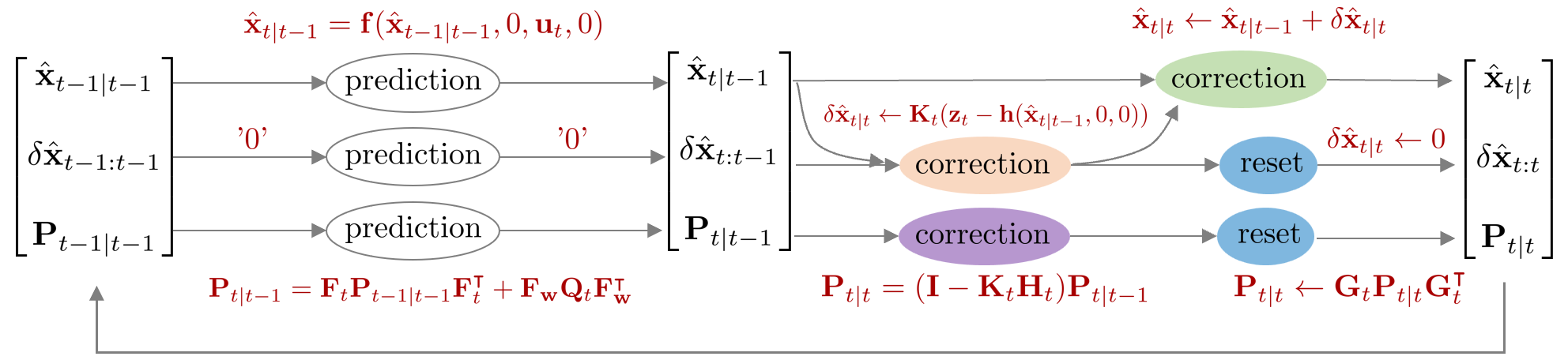
에러상태 칼만필터(error-state kalman filter, ESKF)는 기존의 상태 변수 $\mathbf{x}_{t}$의 평균과 분산을 추정하는 EKF와 달리 에러 상태 변수 $\delta \mathbf{x}_{t}$의 평균과 분산을 추정하는 칼만 필터 알고리즘을 말한다. 상태변수를 바로 추정하지 않고 에러상태를 통해 추정하기 때문에 indirect kalman filter라고도 불린다. 또다른 이름으로는 error-state extended kalman filter(ES-EKF)로도 불린다. ESKF는 기존 상태변수룰 true 상태 변수라고 부르며 이를 다음과 같이 명목(nominal) 상태와 에러(error) 상태의 합으로 표현한다.
\begin{equation} \label{eq:eskf33}
\begin{aligned}
\mathbf{x}_{\text{true},t} = \mathbf{x}_{t} + \delta \mathbf{x}_{t}
\end{aligned}
\end{equation}
- $\mathbf{x}_{\text{true},t}$: 기존 KF, EKF에서 업데이트된 $t$ 스텝의 true 상태변수
- $\mathbf{x}_{t}$: $t$ 스텝의 명목(nominal) 상태 변수. 에러가 없는 상태를 의미한다
- $\delta \mathbf{x}_{t}$: $t$ 스텝의 에러(error) 상태 변수
위 식을 해석하면 실제(true) 추정하고자 하는 상태 변수 $\mathbf{x}_{\text{true},t}$는 에러가 없는 명목(nominal) 상태 $\mathbf{x}_{t}$과 모델 및 센서 노이즈로 부터 발생하는 에러 상태 $\delta \mathbf{x}_{t}$의 합으로 나타낼 수 있다는 의미이다. 이 때, nominal 상태는 (상대적으로) 큰 값을 가지며 비선형성을 가진다. 반면에 에러 상태는 0 근처의 작은 값을 가지고 선형성을 가진다.
기존의 EKF는 비선형성이 큰 true (nominal + error) 상태 변수를 선형화하여 필터링하기 때문에 속도가 느리고 시간이 지날수록 에러 값이 누적되는 반면에, ESKF는 에러 상태만을 선형화하여 필터링하기 때문에 속도 및 정확성이 더욱 빠른 장점이 있다. 기존 EKF와 비교했을 때 ESKF이 가지는 장점들을 정리하면 다음과 같다(Madyastha el tal., 2011):
- 방향(orientation)에 대한 에러 상태 표현법이 최소한의 파라미터를 가진다. 즉, 자유도만큼의 최소 파라미터를 가지기 때문에 over-parameterized로 인해 발생하는 특이점(signularity) 같은 현상이 발생하지 않는다.
- 에러 상태 시스템은 항상 원점(origin) 근처에서만 동작하기 때문에 선형화하기 용이하다. 따라서 짐벌락 같은 파라미터 특이점 현상이 발생하지 않으며 항상 선형화를 수행할 수 있다.
- 에러 상태는 일반적으로 값이 작기 때문에 2차항 이상의 값들은 무시할 수 있다. 이는 자코비안 연산을 쉽고 빠르게 수행할 수 있도록 도와준다. 몇몇 자코비안은 상수화하여 사용하기도 한다.
다만 ESKF는 prediction 속도는 빠르지만 nominal 상태에서 일반적으로 비선형을 가진 큰 값들이 처리되므로 nominal 상태가 처리되는 correction 스텝의 속도가 느린 편이다[2].
ESKF의 모션 모델과 관측 모델은 다음과 같다.
\begin{equation}
\begin{aligned}
& \text{Error-state Motion Model: } & \mathbf{x}_{t} + \delta \mathbf{x}_{t} = \mathbf{f}(\mathbf{x}_{t-1}, \delta \mathbf{x}_{t-1},\mathbf{u}_{t}, \mathbf{w}_{t}) \\
& \text{Error-state Observation Model: } & \mathbf{z}_{t} = \mathbf{h}(\mathbf{x}_{t}, \delta \mathbf{x}_{t}, \mathbf{v}_{t})
\end{aligned}
\end{equation}
- $\mathbf{x}_{t}$: 모델의 nominal 상태 변수
- $\delta \mathbf{x}_{t}$: 모델의 에러 상태 변수
- $\mathbf{u}_{t}$: 모델의 입력(input)
- $\mathbf{z}_{t}$: 모델의 관측값(measurement)
- $\mathbf{f}(\cdot)$: 비선형 모션(motion) 모델 함수
- $\mathbf{h}(\cdot)$: 비선형 관측(observation) 모델 함수
- $\mathbf{w}_{t} \sim \mathcal{N}(0, \mathbf{Q}_{t})$: 에러 상태 모델의 노이즈. $\mathbf{Q}_{t}$는 $ \mathbf{w}_{t}$의 공분산 행렬을 의미
- $\mathbf{v}_{t} \sim \mathcal{N}(0, \mathbf{R}_{t})$: 관측 모델의 노이즈. $\mathbf{R}_{t}$는 $\mathbf{v}_{t}$의 공분산 행렬을 의미
$\mathbf{f}(\cdot), \mathbf{h}(\cdot)$에 각각 1차 테일러 근사를 수행하면 다음과 같다. 해당 전개는 [5]를 참고하여 작성하였다.
\begin{equation} \label{eq:33}
\begin{aligned}
& \mathbf{x}_{t} + \delta \mathbf{x}_{t} \approx \mathbf{f} ( \mathbf{x}_{t-1|t-1}, \delta \hat{\mathbf{x}}_{t-1|t-1},\mathbf{u}_{t}, 0) + \mathbf{F}_{t}(\delta \mathbf{x}_{t-1} - \delta
\hat{\mathbf{x}}_{t-1|t-1}) + \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t} \\
& \mathbf{z}_{t} \approx \mathbf{h}(
\mathbf{x}_{t|t-1}, \delta \hat{\mathbf{x}}_{t|t-1}, 0) + \mathbf{H}_{t}(\delta \mathbf{x}_{t} - \delta \hat{\mathbf{x}}_{t|t-1}) + \mathbf{H}_{\mathbf{v}} \mathbf{v}_{t}
\end{aligned}
\end{equation}
이 때, 두 자코비안 $\mathbf{F}_{t}, \mathbf{H}_{t}$ 모두 true 상태 $\mathbf{x}_{\text{true},t}$가 아닌 에러 상태 $\delta \mathbf{x}_{t}$에 대한 자코비안임에 유의한다. 해당 자코비안 부분이 EKF와 가장 다른 부분이다
\begin{equation} \label{eq:eskf36}
\boxed { \begin{aligned}
& \mathbf{F}_{t} = \frac{\partial \mathbf{f}} {\partial \delta \mathbf{x}_{t-1}}\bigg|_{\substack{ \delta \mathbf{x}_{t-1} = \delta \hat{\mathbf{x}}_{t-1|t-1} }} & \mathbf{F}_{\mathbf{w}} = \frac{\partial \mathbf{f}} {\partial \mathbf{w}_{t}}\bigg|_{\substack{ & \delta \mathbf{x}_{t-1} = \delta \hat{\mathbf{x}}_{t-1|t-1} \\ & \mathbf{w}_{t}=0}}
\end{aligned} }
\end{equation}
\begin{equation}
\boxed{ \begin{aligned}
& \mathbf{H}_{t} = \frac{\partial \mathbf{h}}{\partial \delta \mathbf{x}_{t}}\bigg|_{\delta \mathbf{x}_{t}= \delta \hat{\mathbf{x}}_{t|t-1}} & \mathbf{H}_{\mathbf{v}} = \frac{\partial \mathbf{h}}{\partial \mathbf{v}_{t}}\bigg|_{ \substack{ & \delta \mathbf{x}_{t}= \delta \hat{\mathbf{x}}_{t|t-1} \\ & \mathbf{v}_{t}=0 }}
\end{aligned} }
\end{equation}
$\mathbf{H}_{t}$는 다음과 같이 연쇄법칙을 통해 표현할 수 있다.
\begin{equation} \label{eq:eskf37}
\begin{aligned}
\mathbf{H}_{t} = \frac{\partial \mathbf{h}}{\partial \delta \mathbf{x}_{t}} = \frac{\partial \mathbf{h}}{\partial \mathbf{x}_{\text{true},t}} \frac{\partial \mathbf{x}_{\text{true},t}}{\partial \delta \mathbf{x}_{t}} \\
\end{aligned}
\end{equation}
이 중 앞 부분 $\frac{\partial \mathbf{h}}{\partial \mathbf{x}_{\text{true},t}}$은 EKF에서 구한 자코비안과 동일하지만 에러 상태 변수에 대한 자코비안 $\frac{\partial \mathbf{x}_{\text{true},t}}{\partial \delta \mathbf{x}_{t}}$이 추가되었다. 이에 대한 자세한 내용은 Quaternion kinematics for the error-state Kalman filter 내용 정리 포스트를 참고하면 된다.
($\ref{eq:33})$ 식을 전개하면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{x}_{t} + \delta \mathbf{x}_{t} & = \mathbf{F}_{t} \delta \mathbf{x}_{t-1} + \mathbf{f} ( \mathbf{x}_{t-1|t-1}, \delta \hat{\mathbf{x}}_{t-1|t-1},\mathbf{u}_{t}, 0) - \mathbf{F}_{t} \delta
\hat{\mathbf{x}}_{t-1|t-1} + \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t}
\end{aligned}
\end{equation}
이전 correction 스텝에서 항상 $\delta \hat{\mathbf{x}}_{t-1|t-1}=0$으로 초기화되므로 관련된 항에 0을 대입한다.
\begin{equation}
\begin{aligned}
\mathbf{x}_{t} + \delta \mathbf{x}_{t} & = \mathbf{F}_{t} \delta \mathbf{x}_{t-1} + \mathbf{f} ( \mathbf{x}_{t-1|t-1}, 0,\mathbf{u}_{t}, 0) + \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t}
\end{aligned}
\end{equation}
nominal 상태 변수 $\mathbf{x}_{t}$는 정의 상 노이즈가 없는 $\mathbf{f}(\mathbf{x}_{t-1}, 0, \mathbf{u}_{t}, 0)$과 동일하므로 서로 소거된다.
\begin{equation}
\boxed { \begin{aligned}
\delta \mathbf{x}_{t} & = \mathbf{F}_{t} \delta \mathbf{x}_{t-1} + \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t} \\
& = \mathbf{F}_{t} \delta \mathbf{x}_{t-1} + \tilde{\mathbf{w}}_{t} \\
& = 0 + \tilde{\mathbf{w}}_{t}
\end{aligned} }
\end{equation}
- $\tilde{\mathbf{w}}_{t} = \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t} \sim \mathcal{N}(0, \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal})$
관측 모델 함수도 동일하게 에러 상태 변수의 값을 0으로 치환하면 아래와 같이 전개된다.
\begin{equation} \label{eq:eskf-z}
\boxed{ \begin{aligned}
\mathbf{z}_{t} &= \mathbf{H}_{t} \delta \mathbf{x}_{t} + \mathbf{h}(
\mathbf{x}_{t|t-1}, \delta \hat{\mathbf{x}}_{t|t-1}, 0) - \mathbf{H}_{t} \delta \hat{\mathbf{x}}_{t|t-1} + \mathbf{H}_{\mathbf{v}} \mathbf{v}_{t} \\
& = \mathbf{h}( \mathbf{x}_{t|t-1}, 0, 0) + \mathbf{H}_{\mathbf{v}} \mathbf{v}_{t} \\
& = \tilde{\mathbf{z}}_{t} + \tilde{\mathbf{v}}_{t}
\end{aligned} }
\end{equation}
- $\tilde{\mathbf{z}}_{t} = \mathbf{h}( \mathbf{x}_{t|t-1}, 0, 0)$
- $\tilde{\mathbf{v}}_{t} = \mathbf{H}_{\mathbf{v}} \mathbf{v}_{t} \sim \mathcal{N}(0, \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t} \mathbf{H}_{\mathbf{v}}^{\intercal})$
확률 변수가 모두 가우시안 분포를 따른다고 가정하면 $p(\delta \mathbf{x}_{t} \ | \ \delta \mathbf{x}_{t-1}, \mathbf{u}_{t}), p(\mathbf{z}_{t} \ | \ \delta \mathbf{x}_{t})$는 다음과 같이 나타낼 수 있다.
\begin{equation}
\begin{aligned}
& p(\delta \mathbf{x}_{t} \ | \ \delta \mathbf{x}_{t-1}, \mathbf{u}_{t}) && \sim \mathcal{N}(0, \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal} ) \\
& && = \frac{1}{ \sqrt{\text{det}(2\pi \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal} )}}\exp\bigg( -\frac{1}{2}(\delta \mathbf{x}_{t} )^{\intercal} (\mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal})^{-1}(\delta \mathbf{x}_{t} ) \bigg)\\
\end{aligned}
\end{equation}
\begin{equation} \label{eq:eskf2}
\begin{aligned}
& p(\mathbf{z}_{t} \ | \ \delta \mathbf{x}_{t}) && \sim \mathcal{N}( \tilde{\mathbf{z}}_{t}, \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t}\mathbf{H}_{\mathbf{v}}^{\intercal}) \\
& && = \frac{1}{ \sqrt{\text{det}(2\pi \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t}\mathbf{H}_{\mathbf{v}}^{\intercal})}}\exp\bigg( -\frac{1}{2}(\mathbf{z}_{t} - \tilde{\mathbf{z}}_{t})^{\intercal} (\mathbf{H}_{\mathbf{v}}\mathbf{R}_{t}\mathbf{H}_{\mathbf{v}}^{\intercal})^{-1}(\mathbf{z}_{t} - \tilde{\mathbf{z}}_{t}) \bigg)
\end{aligned}
\end{equation}
$\mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal}$는 선형화된 에러 상태 모션 모델의 노이즈를 의미하며 $\mathbf{H}_{\mathbf{v}}\mathbf{R}_{t}\mathbf{H}_{\mathbf{v}}^{\intercal}$은 선형화된 관측 모델의 노이즈를 의미한다. 다음으로 칼만 필터를 통해 구해야 하는 $\overline{\text{bel}}(\delta \mathbf{x}_{t}), \text{bel}(\delta \mathbf{x}_{t})$은 아래와 같이 나타낼 수 있다.
\begin{equation}
\begin{aligned}
& \overline{\text{bel}}(\delta \mathbf{x}_{t}) = \int p(\delta \mathbf{x}_{t} \ | \ \delta \mathbf{x}_{t-1}, \mathbf{u}_{t})\text{bel}(\delta \mathbf{x}_{t-1}) d \mathbf{x}_{t-1} \sim \mathcal{N}(\delta \hat{\mathbf{x}}_{t|t-1}, \mathbf{P}_{t|t-1}) \\
& \text{bel}(\delta \mathbf{x}_{t}) = \eta \cdot p( \mathbf{z}_{t} \ | \ \delta \mathbf{x}_{t})\overline{\text{bel}}(\delta \mathbf{x}_{t}) \sim \mathcal{N}(\delta \hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t})
\end{aligned}
\end{equation}
ESKF 또한 EKF와 동일하게 prediction에서 이전 스텝의 값과 모션 모델을 사용하여 예측값 $\overline{\text{bel}}(\delta \mathbf{x}_{t})$을 먼저 구한 후 correction에서 관측값과 관측 모델을 사용하여 보정된 값 $\text{bel}(\delta \mathbf{x}_{t})$을 구하는 방식으로 동작한다. $p(\delta \mathbf{x}_{t} | \delta \mathbf{x}_{t-1}, \mathbf{u}_{t})$, $p(\mathbf{z}_{t} | \delta \mathbf{x}_{t})$를 위 식에 대입하여 정리하면 prediction, correction 스텝의 평균과 공분산 $(\delta \hat{\mathbf{x}}_{t|t-1}, \mathbf{P}_{t|t-1}), (\delta \hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t})$을 각각 구할 수 있다. 자세한 유도 과정은 [13]의 3.2.4 "Mathematical Derivation of the KF" 섹션을 참조하면 된다.
초기값 $\text{bel}(\delta \mathbf{x}_{0})$은 다음과 같이 주어진다.
\begin{equation}
\begin{aligned}
\text{bel}(\delta \mathbf{x}_{0}) \sim \mathcal{N}(0, \mathbf{P}_{0})
\end{aligned}
\end{equation}
- $\delta \hat{\mathbf{x}}_{0} = 0$ : 항상 0의 값을 가진다
- $\mathbf{P}_{0}$ : 일반적으로 작은 값(<1e-2)으로 설정한다.
Prediction step
Prediction은 $\overline{\text{bel}}(\delta \mathbf{x}_{t})$를 구하는 과정을 말한다. 공분산 행렬을 구할 때 선형화된 자코비안 행렬 $\mathbf{F}_{t}$가 사용된다.
\begin{equation} \label{eq:eskf-pred}
\boxed{ \begin{aligned}
& \delta \hat{\mathbf{x}}_{t|t-1} = \mathbf{F}_{t}\delta \hat{\mathbf{x}}_{t-1|t-1} = 0 {\color{Mahogany} \quad \leftarrow \text{Always 0} } \\
& \hat{\mathbf{x}}_{t|t-1} = \mathbf{f}(\hat{\mathbf{x}}_{t-1|t-1}, 0,\mathbf{u}_{t}, 0) \\
& \mathbf{P}_{t|t-1} = \mathbf{F}_{t}\mathbf{P}_{t-1|t-1}\mathbf{F}_{t}^{\intercal} + \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal}
\end{aligned} }
\end{equation}
위 식에서 $\mathbf{F}_{t}$는 에러 상태에 대한 자코비안임에 유의한다. 에러 상태 변수 $\delta \hat{\mathbf{x}}$는 매 correction 스텝이 끝나면 0으로 초기화된다. 여기에 선형 자코비안 $\mathbf{F}_{t}$를 곱해도 값은 0이 되기 때문에 prediction 스텝에서 $\delta \hat{\mathbf{x}}$ 값은 항상 0이 된다. 따라서 에러 상태 $\delta \hat{\mathbf{x}}_{t|t-1}$는 prediction 스텝에서는 변하지 않고 nominal 상태 $\hat{\mathbf{x}}_{t|t-1}$와 에러 상태의 공분산 $\mathbf{P}_{t|t-1}$만 업데이트된다.
Correction step
Correction은 $\text{bel}(\delta \mathbf{x}_{t})$를 구하는 과정을 말한다. 칼만 게인과 공분산 행렬을 구할 때 선형화된 자코비안 행렬 $\mathbf{H}_{t}$가 사용된다.
\begin{equation}
\boxed{ \begin{aligned}
& \mathbf{K}_{t} = \mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal}(\mathbf{H}_{t}\mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal} + \mathbf{H}_{\mathbf{v}} \mathbf{R}_{t} \mathbf{H}_{\mathbf{v}})^{-1} \\
& {\color{Mahogany} \delta \hat{\mathbf{x}}_{t|t} = \mathbf{K}_{t}( \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0,0)) } \\
& \hat{\mathbf{x}}_{t|t} = \hat{\mathbf{x}}_{t|t-1} + \delta \hat{\mathbf{x}}_{t|t} \\
& \mathbf{P}_{t|t} = (\mathbf{I} - \mathbf{K}_{t}\mathbf{H}_{t})\mathbf{P}_{t|t-1} \\
& \text{reset } \delta \hat{\mathbf{x}}_{t|t} \\
& \quad \quad \quad \delta \hat{\mathbf{x}}_{t|t} \leftarrow 0 \\
& \quad \quad \quad \mathbf{P}_{t|t} \leftarrow \mathbf{G}\mathbf{P}_{t|t}\mathbf{G}^{\intercal}
\end{aligned} } \label{eq:eskf1}
\end{equation}
위 식에서 $\mathbf{H}_{t}$는 관측 모델에 대한 true 상태 $\mathbf{x}_{\text{true},t}$의 자코비안이 아닌 에러 상태 $\delta \mathbf{x}_{t}$의 자코비안임에 유의한다. $\mathbf{P}_{t|t-1}, \mathbf{K}_{t}$ 또한 EKF와 기호만 같을 뿐 실제 값은 다름에 유의한다. 즉, 전체적인 공식은 EKF와 동일하지만 $\mathbf{F},\mathbf{H},\mathbf{P},\mathbf{K}$ 행렬이 에러 상태 $\delta \mathbf{x}_{t}$에 대한 값을 의미하는 점이 다르다.
Reset
nominal 상태가 정상적으로 업데이트되면 다음으로 에러 상태의 값을 0으로 리셋해야 한다. 리셋을 하는 이유는 새로운 nominal 상태에 대한 새로운 에러(new error)를 표현해야 하기 때문이다. 리셋으로 인해 에러 상태의 공분산 $\mathbf{P}_{t|t}$이 업데이트된다.
리셋 함수를 $\mathbf{g}(\cdot)$라고 하면 이는 다음과 같이 나타낼 수 있다. 이에 대한 자세한 내용은 Quaternion kinematics for the error-state Kalman filter 내용 정리 포스트의 챕터 6 내용을 참고하면 된다.
\begin{equation}
\begin{aligned}
& \delta \mathbf{x} \leftarrow \mathbf{g}(\delta \mathbf{x}) = \delta \mathbf{x} - \delta \hat{\mathbf{x}}_{t|t-1}
\end{aligned}
\end{equation}
ESKF의 리셋 과정은 다음과 같다.
\begin{equation}
\begin{aligned}
& \delta \hat{\mathbf{x}}_{t|t} \leftarrow 0 \\
& \mathbf{P}_{t|t} \leftarrow \mathbf{G}\mathbf{P}_{t|t}\mathbf{G}^{\intercal}
\end{aligned}
\end{equation}
$\mathbf{G}$는 다음과 같이 정의된 리셋에 대한 자코비안을 의미한다.
\begin{equation}
\begin{aligned}
\mathbf{G} = \left. \frac{\partial \mathbf{g}}{\partial \delta \mathbf{x}}\right\vert_{\delta \mathbf{x}_{t}=\delta \hat{\mathbf{x}}_{t|t}}
\end{aligned}
\end{equation}
Summary
ESKF를 함수로 표현하면 다음과 같다.
\begin{equation}
\boxed{ \begin{aligned}
& \text{ErrorStateKalmanFilter}( \hat{\mathbf{x}}_{t-1|t-1} , \delta \hat{\mathbf{x}}_{t-1|t-1}, \mathbf{P}_{t-1|t-1}, \mathbf{u}_{t}, \mathbf{z}_{t}) \{ \\
& \quad\quad \text{(Prediction Step)}\\
& \quad\quad \delta \hat{\mathbf{x}}_{t|t-1} = \mathbf{F}_{t}\hat{\mathbf{x}}_{t-1|t-1}= 0 {\color{Mahogany} \quad \leftarrow \text{Always 0} } \\
& \quad\quad \hat{\mathbf{x}}_{t|t-1} = \mathbf{f}(\hat{\mathbf{x}}_{t-1|t-1}, 0,\mathbf{u}_{t}, 0) \\
& \quad\quad \mathbf{P}_{t|t-1} = \mathbf{F}_{t}\mathbf{P}_{t-1|t-1}\mathbf{F}_{t}^{\intercal} + \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal}\\
& \\
& \quad\quad \text{(Correction Step)} \\
& \quad\quad \mathbf{K}_{t} = \mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal}(\mathbf{H}_{t}\mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal} + \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t} \mathbf{H}_{\mathbf{v}}^{\intercal})^{-1} \\
& \quad\quad \delta \hat{\mathbf{x}}_{t|t} = \mathbf{K}_{t}( \mathbf{z}_{t} - \mathbf{h}_{t}(\hat{\mathbf{x}}_{t|t-1},0,0)) \\
& \quad\quad \hat{\mathbf{x}}_{t|t} = \hat{\mathbf{x}}_{t|t-1} + \delta \hat{\mathbf{x}}_{t|t} \\
& \quad\quad \mathbf{P}_{t|t} = (\mathbf{I} - \mathbf{K}_{t}\mathbf{H}_{t})\mathbf{P}_{t|t-1} \\
& \quad \quad \text{reset } \delta \hat{\mathbf{x}}_{t|t} \\
& \quad \quad \quad \delta \hat{\mathbf{x}}_{t|t} \leftarrow 0 \\
& \quad \quad \quad \mathbf{P}_{t|t} \leftarrow \mathbf{G}\mathbf{P}_{t|t}\mathbf{P}^{\intercal} \\
& \quad\quad \text{return} \ \ \delta \hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t} \\
& \}
\end{aligned} }
\end{equation}
Iterated extended kalman filter (IEKF)
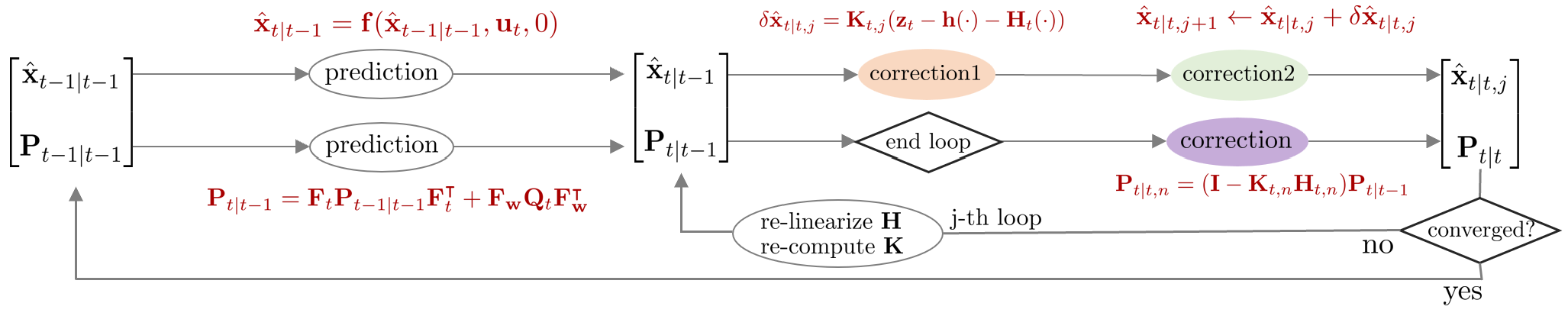
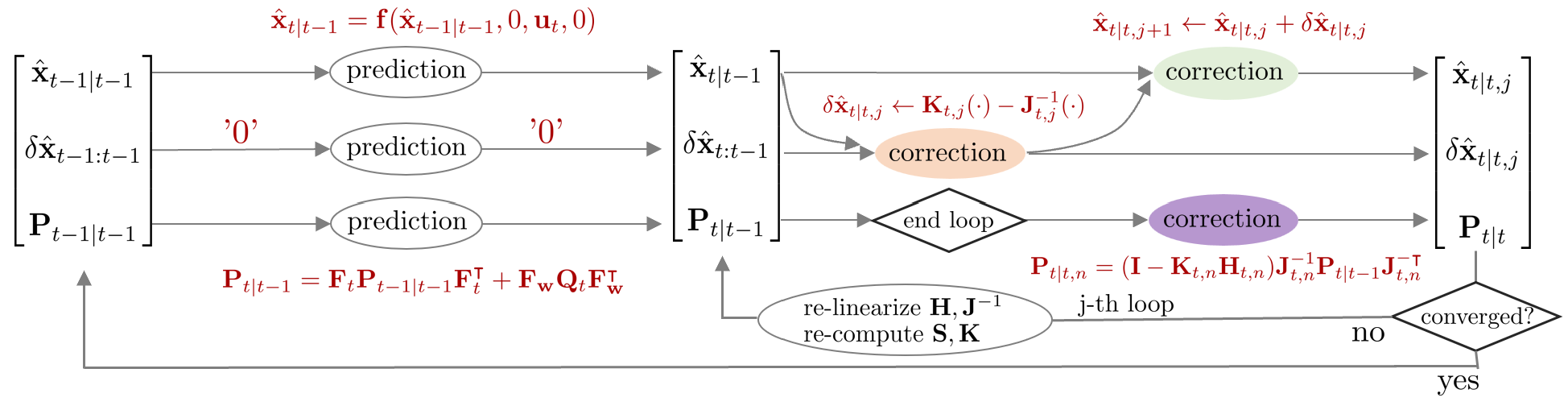
Iterated extended kalman filter (IEKF)는 EKF에서 correction 스텝 부분을 반복적으로 수행하는 알고리즘이다. EKF는 비선형 함수를 선형화하여 상태 변수를 추정하기 때문에 선형화 과정에서 필연적으로 오차가 발생할 수 밖에 없다. IEKF는 이러한 선형화 오차를 줄이기 위해서 correction 스텝이 종료된 후 업데이트 변화량 $\delta \hat{\mathbf{x}}_{t|t,j}$이 충분히 크다면 다시 선형화를 수행하여 반복적으로 correction 스텝을 진행한다.
이 때, $\delta \hat{\mathbf{x}}$는 문맥 상 에러 상태 변수가 아닌 업데이트 변화량으로 해석된다. 즉 $\hat{\mathbf{x}}_{t|t,j+1} \leftarrow \hat{\mathbf{x}}_{t|t,j} + \delta \hat{\mathbf{x}}_{t|t,j}$와 같이 j번째 posterior 값에 더해져서 j+1 번째 posterior 값을 업데이트하는 용도로만 사용된다. 다시 말하면, 상태 추정의 대상이 아니다.
Compare to EKF
Commonality 1
IEKF에서 모션 모델과 관측 모델은 다음과 같다. 이는 EKF와 완전히 동일하다.
\begin{equation}
\begin{aligned}
& \text{Motion Model: } & \mathbf{x}_{t} = \mathbf{f}(\mathbf{x}_{t-1}, \mathbf{u}_{t} , \mathbf{w}_{t}) \\
& \text{Observation Model: } & \mathbf{z}_{t} = \mathbf{h}(\mathbf{x}_{t}, \mathbf{v}_{t})
\end{aligned}
\end{equation}
- $\mathbf{x}_{t}$: 모델의 상태 변수(state variable)
- $\mathbf{u}_{t}$: 모델의 입력(input)
- $\mathbf{z}_{t}$: 모델의 관측값(measurement)
- $\mathbf{f}(\cdot)$: 비선형 모션(motion) 모델 함수
- $\mathbf{h}(\cdot)$: 비선형 관측(observation) 모델 함수
- $\mathbf{w}_{t} \sim \mathcal{N}(0, \mathbf{Q}_{t})$: 모션 모델의 노이즈. $\mathbf{Q}_{t}$는 $\mathbf{w}_{t}$의 공분산 행렬을 의미
- $\mathbf{v}_{t} \sim \mathcal{N}(0, \mathbf{R}_{t})$: 관측 모델의 노이즈. $\mathbf{R}_{t}$는 $\mathbf{v}_{t}$의 공분산 행렬을 의미
Commonality 2
다음으로 선형화 과정도 EKF의 ($\ref{eq:ekf1}$), ($\ref{eq:ekf2}$)와 완전히 동일하다.
\begin{equation}
\boxed{ \begin{aligned}
\mathbf{x}_{t} & = \mathbf{F}_{t}\mathbf{x}_{t-1} +
\mathbf{f}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{u}_{t} , 0 ) - \mathbf{F}_{t} \hat{\mathbf{x}}_{t-1|t-1} + \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t} \\
& = \mathbf{F}_{t}\mathbf{x}_{t-1} + \tilde{\mathbf{u}}_{t} + \tilde{\mathbf{w}}_{t}
\end{aligned} }
\end{equation}
- $\tilde{\mathbf{u}}_{t} = \mathbf{f}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{u}_{t} , 0 ) - \mathbf{F}_{t} \hat{\mathbf{x}}_{t-1|t-1}$
- $\tilde{\mathbf{w}}_{t} = \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t} \sim \mathcal{N}(0, \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal})$
\begin{equation} \label{eq:iekf1}
\boxed{ \begin{aligned}
\mathbf{z}_{t} & = \mathbf{H}_{t}\mathbf{x}_{t} + \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0) - \mathbf{H}_{t}\hat{\mathbf{x}}_{t|t-1} + \mathbf{H}_{\mathbf{v}}\mathbf{v}_{t} \\
& = \mathbf{H}_{t}\mathbf{x}_{t} + \tilde{\mathbf{z}}_{t} + \tilde{\mathbf{v}}_{t}
\end{aligned} }
\end{equation}
- $\tilde{\mathbf{z}}_{t} = \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0) - \mathbf{H}_{t}\hat{\mathbf{x}}_{t|t-1}$
- $\tilde{\mathbf{v}}_{t} = \mathbf{H}_{\mathbf{v}}\mathbf{v}_{t} \sim \mathcal{N}(0, \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t} \mathbf{H}_{\mathbf{v}}^{\intercal})$
Commonality 3
IEKF는 EKF와 동일하게 $\mathbf{F}, \mathbf{H}, \mathbf{K}$ 행렬이 true 상태 변수 $\mathbf{x}_{\text{true}}$에 대한 행렬을 사용한다.
Difference 1 (Iterative nature)
EKF: prediction 값으로부터 한 번에 correction 값이 나온다.
IEKF: correction 값이 다시 prediction 값이 되어 correction 스텝을 반복적으로 진행한다.
\begin{equation}
\boxed{ \begin{aligned}
& \text{EKF Correction : } \quad \hat{\mathbf{x}}_{t|t-1} \rightarrow \hat{\mathbf{x}}_{t|t} \\
& \text{IEKF Correction : } \quad \hat{\mathbf{x}}_{t|t,j} \leftrightarrows \hat{\mathbf{x}}_{t|t,j+1} \\
\end{aligned} }
\end{equation}
- $j$: $j$-th iteration
Difference 2 (Different innovation term)
($\ref{eq:iekf1}$) 식을 전개하여 innovation term $\mathbf{r}_{t}$을 만들어보면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{r}_{t} = \mathbf{z}_{t} - \mathbf{h} (\hat{\mathbf{x}}_{t|t-1}, 0) - \mathbf{H}_{t}(\mathbf{x}_{t} -\hat{\mathbf{x}}_{t|t-1})
\end{aligned}
\end{equation}
EKF의 경우 correction 스텝 ($\ref{eq:ekf3}$)의 두 번째 줄을 보면 칼만 게인 $\mathbf{K}_{t}$에 $\mathbf{r}_{t}$가 곱해져서 posterior를 계산하는 것을 볼 수 있다.
\begin{equation}
\begin{aligned}
\text{EKF correction : } \quad & \hat{\mathbf{x}}_{t|t} && = \hat{\mathbf{x}}_{t|t-1} + \mathbf{K}_{t}( \mathbf{r}_{t}) \\
& && = \hat{\mathbf{x}}_{t|t-1} + \mathbf{K}_{t}( \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0))
\end{aligned}
\end{equation}
EKF: $\mathbf{H}_{t}(\mathbf{x}_{t} -\hat{\mathbf{x}}_{t|t-1})$ 부분은 $\mathbf{x}_{t} = \hat{\mathbf{x}}_{t|t-1}$이 대입되어 소거되고 나머지 부분만 사용된다.
IEKF: 매 순간 correction 스텝을 반복하면서 새로운 상태(new operating point)에 대한 선형화를 수행하기 때문에 해당 부분이 소거되지 않는다.
\begin{equation}
\boxed{ \begin{aligned}
& \text{EKF innovation term : } \quad \mathbf{r}_{t} = \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0) \\
& \text{IEKF innovation term : } \quad \mathbf{r}_{t,j} = \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}, 0) - \mathbf{H}_{t,j}(\hat{\mathbf{x}}_{t|t-1} - \hat{\mathbf{x}}_{t|t,j}) \\
\end{aligned} }
\end{equation}
만약 첫 번째 iteration $j=0$의 경우 $\hat{\mathbf{x}}_{t|t,0} = \hat{\mathbf{x}}_{t|t-1}$이므로 소거되어 EKF와 동일한 식이 되지만 $j=1$ 이상부터는 다른 값이 되므로 소거되지 않는다.
Prediction step
Prediction은 $\overline{\text{bel}}(\mathbf{x}_{t})$를 구하는 과정을 말한다. 공분산 행렬을 구할 때 선형화된 자코비안 행렬 $\mathbf{F}_{t}$가 사용된다. 이는 EKF의 prediction 스텝과 완전히 동일하다.
\begin{equation}
\boxed{ \begin{aligned}
& \hat{\mathbf{x}}_{t|t-1} = \mathbf{f}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{u}_{t} , 0 ) \\
& \mathbf{P}_{t|t-1} = \mathbf{F}_{t}\mathbf{P}_{t-1|t-1}\mathbf{F}_{t}^{\intercal} + \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal}
\end{aligned} }
\end{equation}
Correction step
Correction은 $\text{bel}(\mathbf{x}_{t})$를 구하는 과정을 말한다. 칼만 게인과 공분산 행렬을 구할 때 선형화된 자코비안 행렬 $\mathbf{H}_{t}$가 사용된다. IEKF의 correction 스텝은 업데이트 변화량 $\delta \hat{\mathbf{x}}_{t|t,j}$가 충분히 작아질 때까지 반복적(iterative)으로 수행한다.
\begin{equation} \label{eq:iekf-cor}
\boxed {\begin{aligned}
& \text{set } \epsilon \\
& \text{start j-th loop } \\
& \quad \mathbf{K}_{t,j} = \mathbf{P}_{t|t-1} \mathbf{H}_{t,j}^{\intercal}(\mathbf{H}_{t,j}\mathbf{P}_{t|t-1} \mathbf{H}_{t,j}^{\intercal} + \mathbf{H}_{\mathbf{v},j}\mathbf{R}_{t}\mathbf{H}_{\mathbf{v},j}^{\intercal})^{-1} \\
& {\color{Mahogany} \quad \delta \hat{\mathbf{x}}_{t|t,j} = \mathbf{K}_{t,j} (\mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}, 0) - \mathbf{H}_{t}(\hat{\mathbf{x}}_{t|t-1} - \hat{\mathbf{x}}_{t|t,j})) } \\
& \quad \hat{\mathbf{x}}_{t|t, j+1} = \hat{\mathbf{x}}_{t|t, j} + \delta \hat{\mathbf{x}}_{t|t,j} \\
& \quad \text{iterate until } \delta \hat{\mathbf{x}}_{t|t,j} < \epsilon. \\
& \text{end loop} \\
& \mathbf{P}_{t|t,n} = (\mathbf{I} - \mathbf{K}_{t,n}\mathbf{H}_{t,n}) \mathbf{P}_{t|t-1} \\
\end{aligned} }
\end{equation}
Summary
IEKF를 함수로 표현하면 다음과 같다.
\begin{equation}
\boxed{ \begin{aligned}
& \text{IteratedExtendedKalmanFilter}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{P}_{t-1|t-1}, \mathbf{u}_{t}, \mathbf{z}_{t}) \{ \\
& \quad\quad \text{(Prediction Step)}\\
& \quad\quad \hat{\mathbf{x}}_{t|t-1} = \mathbf{f}_{t}(\hat{\mathbf{x}}_{t-1|t-1}, \mathbf{u}_{t} , 0 ) \\
& \quad\quad \mathbf{P}_{t|t-1} = \mathbf{F}_{t}\mathbf{P}_{t-1|t-1}\mathbf{F}_{t}^{\intercal} + \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal} \\
& \\
& \quad\quad \text{(Correction Step)} \\
& \quad\quad \text{set } \epsilon \\
& \quad\quad\text{start j-th loop } \\
& \quad\quad \quad \mathbf{K}_{t,j} = \mathbf{P}_{t|t-1} \mathbf{H}_{t,j}^{\intercal}(\mathbf{H}_{t,j}\mathbf{P}_{t|t-1} \mathbf{H}_{t,j}^{\intercal} + \mathbf{H}_{\mathbf{v},j}\mathbf{R}_{t}\mathbf{H}_{\mathbf{v},j}^{\intercal})^{-1} \\
& \quad\quad \quad \delta \hat{\mathbf{x}}_{t|t,j} = \mathbf{K}_{t,j} (\mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}, 0) - \mathbf{H}_{t}(\hat{\mathbf{x}}_{t|t-1} - \hat{\mathbf{x}}_{t|t,j})) \\
& \quad\quad \quad \hat{\mathbf{x}}_{t|t, j+1} = \hat{\mathbf{x}}_{t|t, j} + \delta \hat{\mathbf{x}}_{t|t,j} \\
& \quad\quad \quad \text{iterate until } \delta \hat{\mathbf{x}}_{t|t,j} < \epsilon. \\
& \quad\quad \text{end loop} \\
& \quad\quad \mathbf{P}_{t|t,n} = (\mathbf{I} - \mathbf{K}_{t,n}\mathbf{H}_{t,n}) \mathbf{P}_{t|t-1} \\
& \quad\quad \text{return} \ \ \hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t} \\
& \}
\end{aligned} }
\end{equation}
Iterated error-state kalman filter (IESKF)
IEKF가 correction 스텝에서 true 상태 변수 $\mathbf{x}_{\text{true}}$를 반복적으로 추정한다면 IESKF는 에러 상태 변수 $\delta \mathbf{x}_{t}$를 반복적으로 추정하는 알고리즘이다. 두 상태 변수 사이의 관계는 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{x}_{\text{true},t} = \mathbf{x}_{t} + \delta \mathbf{x}_{t}
\end{aligned}
\end{equation}
- $\mathbf{x}_{\text{true},t}$: 기존 KF, EKF에서 업데이트된 $t$ 스텝의 true 상태변수
- $\mathbf{x}_{t}$: $t$ 스텝의 명목(nominal) 상태 변수. 에러가 없는 상태를 의미한다
- $\delta \mathbf{x}_{t}$: $t$ 스텝의 에러(error) 상태 변수
반복적(iterative)으로 값이 업데이트 되는 IESKF 과정에서 $\mathbf{x}_{\text{true},t}$는 업데이트 된 이후 상태, nominal $\mathbf{x}_{t}$는 업데이트 되기 전 상태, 에러 상태 변수 $\delta \mathbf{x}_{t}$는 업데이트 변화량으로 해석하면 된다.
Compare to ESKF
Commonality 1
IESKF의 모션 모델과 관측 모델은 다음과 같다. 이는 ESKF와 완전히 동일하다.
\begin{equation}
\begin{aligned}
& \text{Error-state Motion Model: } & \mathbf{x}_{t} + \delta \mathbf{x}_{t} = \mathbf{f}(\mathbf{x}_{t-1}, \delta \mathbf{x}_{t-1},\mathbf{u}_{t}, \mathbf{w}_{t}) \\
& \text{Error-state Observation Model: } & \mathbf{z}_{t} = \mathbf{h}(\mathbf{x}_{t}, \delta \mathbf{x}_{t}, \mathbf{v}_{t})
\end{aligned}
\end{equation}
- $\mathbf{x}_{t}$: 모델의 nominal 상태 변수
- $\delta \mathbf{x}_{t}$: 모델의 에러 상태 변수
- $\mathbf{u}_{t}$: 모델의 입력(input)
- $\mathbf{z}_{t}$: 모델의 관측값(measurement)
- $\mathbf{f}(\cdot)$: 비선형 모션(motion) 모델 함수
- $\mathbf{h}(\cdot)$: 비선형 관측(observation) 모델 함수
- $\mathbf{w}_{t} \sim \mathcal{N}(0, \mathbf{Q}_{t})$: 에러 상태 모델의 노이즈. $\mathbf{Q}_{t}$는 $ \mathbf{w}_{t}$의 공분산 행렬을 의미
- $\mathbf{v}_{t} \sim \mathcal{N}(0, \mathbf{R}_{t})$: 관측 모델의 노이즈. $\mathbf{R}_{t}$는 $\mathbf{v}_{t}$의 공분산 행렬을 의미
Commonality 2
IESKF의 두 자코비안 $\mathbf{F}_{t}, \mathbf{H}_{t}$ 모두 true 상태 $\mathbf{x}_{\text{true},t}$가 아닌 ESKF와 동일하게 에러 상태 $\delta \mathbf{x}_{t}$에 대한 자코비안을 의미한다.
\begin{equation} \boxed { \begin{aligned}
& \mathbf{F}_{t} = \frac{\partial \mathbf{f}} {\partial \delta \mathbf{x}_{t-1}}\bigg|_{\substack{ \delta \mathbf{x}_{t-1} = \delta \hat{\mathbf{x}}_{t-1|t-1} }} & \mathbf{F}_{\mathbf{w}} = \frac{\partial \mathbf{f}} {\partial \mathbf{w}_{t}}\bigg|_{\substack{ & \delta \mathbf{x}_{t-1} = \delta \hat{\mathbf{x}}_{t-1|t-1} \\ & \mathbf{w}_{t}=0}}
\end{aligned} }
\end{equation}
\begin{equation}
\boxed{ \begin{aligned}
& \mathbf{H}_{t} = \frac{\partial \mathbf{h}}{\partial \delta \mathbf{x}_{t}}\bigg|_{\delta \mathbf{x}_{t}= \delta \hat{\mathbf{x}}_{t|t-1}} & \mathbf{H}_{\mathbf{v}} = \frac{\partial \mathbf{h}}{\partial \mathbf{v}_{t}}\bigg|_{ \substack{ & \delta \mathbf{x}_{t}= \delta \hat{\mathbf{x}}_{t|t-1} \\ & \mathbf{v}_{t}=0 }}
\end{aligned} }
\end{equation}
$\mathbf{H}_{t}$는 다음과 같이 연쇄법칙을 통해 표현할 수 있다.
\begin{equation}
\begin{aligned}
\mathbf{H}_{t} = \frac{\partial \mathbf{h}}{\partial \delta \mathbf{x}_{t}} = \frac{\partial \mathbf{h}}{\partial \mathbf{x}_{\text{true},t}} \frac{\partial \mathbf{x}_{\text{true},t}}{\partial \delta \mathbf{x}_{t}} \\
\end{aligned}
\end{equation}
Commonality 3
선형화된 에러 상태 변수 $\hat{\mathbf{x}}_{t}$ 또한 ESKF와 동일하게 구할 수 있다.
\begin{equation}
\boxed { \begin{aligned}
\delta \mathbf{x}_{t} & = \mathbf{F}_{t} \delta \mathbf{x}_{t-1} + \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t} \\
& = \mathbf{F}_{t} \delta \mathbf{x}_{t-1} + \tilde{\mathbf{w}}_{t} \\
& = 0 + \tilde{\mathbf{w}}_{t}
\end{aligned} }
\end{equation}
- $\tilde{\mathbf{w}}_{t} = \mathbf{F}_{\mathbf{w}} \mathbf{w}_{t} \sim \mathcal{N}(0, \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal})$
Difference (MAP-based derivation)
ESKF derivation:
ESKF의 correction 스텝은 아래 수식을 전개하여 평균 $\delta \hat{\mathbf{x}}_{t|t}$와 공분산 $\mathbf{P}_{t|t}$를 유도한다.
\begin{equation} \label{eq:ieskf1}
\begin{aligned}
\text{bel}(\delta \mathbf{x}_{t}) = \eta \cdot p(\mathbf{z}_{t} \ | \ \delta \mathbf{x}_{t}) \overline{\text{bel}}( \delta \mathbf{x}_{t}) \sim \mathcal{N}( \delta \hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t})
\end{aligned}
\end{equation}
- $p(\mathbf{z}_{t} \ | \ \delta \mathbf{x}_{t}) \sim \mathcal{N}( \tilde{\mathbf{z}}_{t}, \mathbf{H}_{\mathbf{v}}\mathbf{R}_{t}\mathbf{H}_{\mathbf{v}}^{\intercal})$ : (\ref{eq:eskf2}) 참조
- $\overline{\text{bel}}( \delta \mathbf{x}_{t}) \sim \mathcal{N}( \delta \hat{\mathbf{x}}_{t|t-1}, \mathbf{P}_{t|t-1})$
\begin{equation}
\boxed{ \begin{aligned}
& \delta \hat{\mathbf{x}}_{t|t} = \mathbf{K}_{t} ( \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0,0)) \\
& \mathbf{P}_{t|t} = (\mathbf{I} - \mathbf{K}_{t}\mathbf{H}_{t})\mathbf{P}_{t|t-1}
\end{aligned} }
\end{equation}
IESKF derivation:
IESKF는 maximum a posteriori(MAP)을 사용하여 correction 스텝을 유도한다. 이 때, MAP 추정을 위해 Gauss-Newton 최적화 방식이 사용된다. 보다 자세한 내용은 해당 섹션을 참조하면 된다. 해당 유도 과정은 [6],[7],[8],[9],[10],[11] 을 참고하여 작성하였다. 이 중 [6]이 가장 자세하게 IESKF 유도 과정에 대해 설명하고 있다.
EKF를 MAP 방식으로 유도하면 최종적으로 아래와 같은 식을 최적화해야 한다.
\begin{equation} \label{eq:ieskf2}
\begin{aligned}
\arg\min_{\mathbf{x}_{t}} \quad \left\| \mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{\text{true}, t}, 0) \right\|_{\mathbf{H}_{\mathbf{v}}\mathbf{R}^{-1}\mathbf{H}_{\mathbf{v}}^{\intercal}} + \left\| \mathbf{x}_{\text{true},t} - \hat{\mathbf{x}}_{t|t-1} \right\|_{\mathbf{P}_{t|t-1}^{-1}}
\end{aligned}
\end{equation}
위 식을 nominal 상태 $\mathbf{x}_{t}$와 에러 상태 $\delta \mathbf{x}_{t}$에 대한 식으로 표현하면 다음과 같다.
\begin{equation} \label{eq:ieskf7}
\begin{aligned}
\arg\min_{\delta \hat{\mathbf{x}}_{t|t}} \quad \left\| \mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t}, \delta \mathbf{x}_{t}, 0) \right\|_{\mathbf{H}_{\mathbf{v}}\mathbf{R}^{-1}\mathbf{H}_{\mathbf{v}}^{\intercal}} + \left\| \delta \hat{\mathbf{x}}_{t|t-1} \right\|_{\mathbf{P}_{t|t-1}^{-1}}
\end{aligned}
\end{equation}
Prediction 에러 상태 변수 $\delta \hat{\mathbf{x}}_{t|t-1}$은 다음과 같이 정의한다.
\begin{equation} \begin{aligned} \delta \hat{\mathbf{x}}_{t|t-1} & = \mathbf{x}_{\text{true}, t} - \hat{\mathbf{x}}_{t|t-1} \\ & \sim \mathcal{N}(0, \mathbf{P}_{t|t-1})
\end{aligned} \end{equation}
Posterior(=correction) 에러 상태 변수 $\delta \hat{\mathbf{x}}_{t|t}$는 다음과 같이 정의한다.
\begin{equation} \begin{aligned} & \delta \hat{\mathbf{x}}_{t|t} = \mathbf{x}_{\text{true}, t|t} - \hat{\mathbf{x}}_{t|t} \end{aligned} \end{equation}
위 식을 이항하면 아래 공식이 성립한다.
\begin{equation} \label{eq:ieskf3} \begin{aligned} & \mathbf{x}_{\text{true}, t|t} = \hat{\mathbf{x}}_{t|t} + \delta \hat{\mathbf{x}}_{t|t} \\ \end{aligned} \end{equation}
(\ref{eq:ieskf7})의 앞 부분은 (\ref{eq:eskf-z}) 선형화와 동일하게 진행하면 된다.
\begin{equation} \label{eq:ieskf5}
\begin{aligned}
\mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t|t-1}, \delta \hat{\mathbf{x}}_{t|t-1}, 0) \approx \mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t|t-1}, 0, 0) - \mathbf{H}_{t} \delta \mathbf{x}_{t}
\end{aligned}
\end{equation}
위 식에서 $\delta \mathbf{x}_{t}$는 ESKF에서는 항상 0이므로 제거하였으나 IESKF에서는 0이 아닌 값을 가지므로 제거하지 않는다. 다음으로 (\ref{eq:ieskf7})의 뒷 부분에 (\ref{eq:ieskf3})를 대입하면 아래와 같이 전개된다.
\begin{equation} \label{eq:ieskf4}
\begin{aligned}
\delta \hat{\mathbf{x}}_{t|t-1} & = \mathbf{x}_{\text{true},t} - \hat{\mathbf{x}}_{t|t-1} \\ &= (\hat{\mathbf{x}}_{t|t} + \delta \hat{\mathbf{x}}_{t|t}) - \hat{\mathbf{x}}_{t|t-1} \\
& \approx \hat{\mathbf{x}}_{t|t} - \hat{\mathbf{x}}_{t|t-1} + \mathbf{J}_{t} \delta \hat{\mathbf{x}}_{t|t} \\
& \sim \mathcal{N}(0, \mathbf{P}_{t|t-1})
\end{aligned}
\end{equation}
이 때, $\mathbf{J}_{t}$는 다음과 같이 정의된다.
\begin{equation}
\begin{aligned}
\mathbf{J}_{t} = \frac{\partial }{\partial \delta \hat{\mathbf{x}}_{t|t}} \bigg( (\hat{\mathbf{x}}_{t|t} + \delta \hat{\mathbf{x}}_{t|t}) - \hat{\mathbf{x}}_{t|t-1} \bigg) \bigg|_{\delta \hat{\mathbf{x}}_{t|t}=0}
\end{aligned}
\end{equation}
(\ref{eq:ieskf4})의 세 번째 줄과 네 번째 줄을 이항한 후 정리하면 아래와 같은 공식을 얻는다.
\begin{equation}
\begin{aligned}
\delta \hat{\mathbf{x}}_{t|t} \sim \mathcal{N}(-\mathbf{J}_{t}^{-1}(\hat{\mathbf{x}}_{t|t} - \hat{\mathbf{x}}_{t|t-1}), \ \mathbf{J}_{t}^{-1}\mathbf{P}_{t|t-1}\mathbf{J}_{t}^{-\intercal})
\end{aligned}
\end{equation}
지금까지 계산한 (\ref{eq:ieskf5}), (\ref{eq:ieskf4})를 (\ref{eq:ieskf7})에 대입하면 아래와 같은 MAP 추정 문제가 된다.
\begin{equation}
\begin{aligned}
\arg\min_{\delta \hat{\mathbf{x}}_{t|t}} \quad & \left\| \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0, 0) - \mathbf{H}_{t} \delta\hat{\mathbf{x}}_{t|t} \right\|_{\mathbf{H}_{\mathbf{v}}\mathbf{R}^{-1}\mathbf{H}_{\mathbf{v}}^{\intercal}} \\
& + \left\| \hat{\mathbf{x}}_{t|t} - \hat{\mathbf{x}}_{t|t-1} + \mathbf{J}_{t}\delta\hat{\mathbf{x}}_{t|t} \right\|_{\mathbf{P}_{t|t-1}^{-1}}
\end{aligned}
\end{equation}
IESKF는 이를 반복적으로(iterative)하게 추정함으로써 에러 상태 변수 $\delta \hat{\mathbf{x}}_{t|t}$가 특정 값 $\epsilon$ 이하로 수렴할 때까지 반복한다. $j$번째 iteration에 대한 표현은 다음과 같다.
\begin{equation}
\boxed{ \begin{aligned}
\delta \hat{\mathbf{x}}_{t|t,j} \sim \mathcal{N}(-\mathbf{J}_{t,j}^{-1}(\hat{\mathbf{x}}_{t|t,j} - \hat{\mathbf{x}}_{t|t-1}), \ \mathbf{J}_{t,j}^{-1}\mathbf{P}_{t|t-1}\mathbf{J}_{t,j}^{-\intercal})
\end{aligned} }
\end{equation}
\begin{equation} \label{eq:ieskf6}
\boxed{ \begin{aligned}
\arg\min_{\delta \hat{\mathbf{x}}_{t|t,j}} \quad & \left\| \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0, 0) - \mathbf{H}_{t} \delta\hat{\mathbf{x}}_{t|t,j} \right\|_{\mathbf{H}_{\mathbf{v}}\mathbf{R}^{-1}\mathbf{H}_{\mathbf{v}}^{\intercal}} \\
& + \left\| \hat{\mathbf{x}}_{t|t,j} - \hat{\mathbf{x}}_{t|t-1} + \mathbf{J}_{t,j}\delta\hat{\mathbf{x}}_{t|t,j} \right\|_{\mathbf{P}_{t|t-1}^{-1}}
\end{aligned} }
\end{equation}
위 수식으로부터 업데이트 수식을 유도하는 과정은 Derivation of IESKF update step 섹션을 참조하면 된다.
Prediction step
Prediction은 $\overline{\text{bel}}(\delta \mathbf{x}_{t})$를 구하는 과정을 말한다. 공분산 행렬을 구할 때 선형화된 자코비안 행렬 $\mathbf{F}_{t}$가 사용된다. 이는 ESKF와 완전히 동일하다.
\begin{equation}
\boxed{ \begin{aligned}
& \delta \hat{\mathbf{x}}_{t|t-1} = \mathbf{F}_{t}\delta \hat{\mathbf{x}}_{t-1|t-1} = 0 {\color{Mahogany} \quad \leftarrow \text{Always 0} } \\
& \hat{\mathbf{x}}_{t|t-1} = \mathbf{f}(\hat{\mathbf{x}}_{t-1|t-1}, 0,\mathbf{u}_{t}, 0) \\
& \mathbf{P}_{t|t-1} = \mathbf{F}_{t}\mathbf{P}_{t-1|t-1}\mathbf{F}_{t}^{\intercal} + \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal}
\end{aligned} }
\end{equation}
Correction step
Correction은 $\text{bel}(\mathbf{x}_{t})$를 구하는 과정을 말한다. 칼만 게인과 공분산 행렬을 구할 때 선형화된 자코비안 행렬 $\mathbf{H}_{t}$가 사용된다. IESKF의 correction 스텝은 업데이트 변화량 $\delta \hat{\mathbf{x}}_{t|t,j}$가 충분히 작아질 때까지 반복적(iterative)으로 수행한다. 앞서 유도한 (\ref{eq:ieskf6})을 미분한 후 0으로 설정하여 풀면 아래와 같은 공식을 얻는다. 보다 자세한 유도 과정은 Derivation of IESKF update step 섹션을 참조하면 된다.
\begin{equation} \label{eq:ieskf8}
\boxed{ \begin{aligned}
& \text{set } \epsilon \\
& \text{start j-th loop } \\
& \quad \mathbf{S}_{t,j} = \mathbf{H}_{t,j}\mathbf{J}^{-1}_{t,j} \mathbf{P}_{t|t-1} \mathbf{J}^{-\intercal}_{t,j}\mathbf{H}_{t,j}^{\intercal} + \mathbf{H}_{\mathbf{v},j}\mathbf{R}_{t}\mathbf{H}_{\mathbf{v},j}^{\intercal} \\
& \quad \mathbf{K}_{t,j} = \mathbf{J}^{-1}_{t,j} \mathbf{P}_{t|t-1} \mathbf{J}^{-\intercal}_{t,j}\mathbf{H}_{t,j}^{\intercal}\mathbf{S}_{t,j}^{-1} \\
& {\color{Mahogany} \quad \delta \hat{\mathbf{x}}_{t|t,j} = \mathbf{K}_{t,j} \bigg( \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}, 0 ,0) + \mathbf{H}_{t,j}\mathbf{J}^{-1}_{t,j}(\hat{\mathbf{x}}_{t|t,j} - \hat{\mathbf{x}}_{t|t-1}) \bigg) - \mathbf{J}^{-1}_{t,j}(\hat{\mathbf{x}}_{t|t,j} - \hat{\mathbf{x}}_{t|t-1}) } \\
& \quad \hat{\mathbf{x}}_{t|t, j+1} = \hat{\mathbf{x}}_{t|t, j} \boxplus \delta \hat{\mathbf{x}}_{t|t,j} \\
& \quad \text{iterate until } \delta \hat{\mathbf{x}}_{t|t,j} < \epsilon. \\
& \text{end loop} \\
& \mathbf{P}_{t|t,n} = (\mathbf{I} - \mathbf{K}_{t,n}\mathbf{H}_{t,n}) \mathbf{J}^{-1}_{t,n}\mathbf{P}_{t|t-1} \mathbf{J}_{t,n}^{-\intercal} \\
\end{aligned} }
\end{equation}
Summary
IESKF를 함수로 표현하면 다음과 같다.
\begin{equation}
\boxed{ \begin{aligned}
& \text{IteratedErrorStateKalmanFilter}(\hat{\mathbf{x}}_{t-1|t-1}, \delta \hat{\mathbf{x}}_{t-1|t-1}, \mathbf{P}_{t-1|t-1}, \mathbf{u}_{t}, \mathbf{z}_{t}) \{ \\
& \quad\quad \text{(Prediction Step)}\\
& \quad\quad \delta \hat{\mathbf{x}}_{t|t-1} = \mathbf{F}_{t}\hat{\mathbf{x}}_{t-1|t-1}= 0 {\color{Mahogany} \quad \leftarrow \text{Always 0} } \\
& \quad\quad \hat{\mathbf{x}}_{t|t-1} = \mathbf{f}(\hat{\mathbf{x}}_{t-1|t-1}, 0,\mathbf{u}_{t}, 0) \\
& \quad\quad \mathbf{P}_{t|t-1} = \mathbf{F}_{t}\mathbf{P}_{t-1|t-1}\mathbf{F}_{t}^{\intercal} + \mathbf{F}_{\mathbf{w}}\mathbf{Q}_{t} \mathbf{F}_{\mathbf{w}}^{\intercal}\\
& \\
& \quad\quad \text{(Correction Step)} \\
& \quad\quad \text{set } \epsilon \\
& \quad\quad \text{start j-th loop } \\
& \quad\quad \quad \mathbf{S}_{t,j} = \mathbf{H}_{t,j}\mathbf{J}^{-1}_{t,j} \mathbf{P}_{t|t-1} \mathbf{J}^{-\intercal}_{t,j}\mathbf{H}_{t,j}^{\intercal} + \mathbf{H}_{\mathbf{v},j}\mathbf{R}_{t}\mathbf{H}_{\mathbf{v},j}^{\intercal} \\
& \quad\quad \quad \mathbf{K}_{t,j} = \mathbf{J}^{-1}_{t,j} \mathbf{P}_{t|t-1} \mathbf{J}^{-\intercal}_{t,j}\mathbf{H}_{t,j}^{\intercal}\mathbf{S}_{t,j}^{-1} \\
& \quad\quad \quad \delta \hat{\mathbf{x}}_{t|t,j} = \mathbf{K}_{t,j} \bigg( \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}, 0 ,0) + \mathbf{H}_{t,j}\mathbf{J}^{-1}_{t,j}(\hat{\mathbf{x}}_{t|t,j} - \hat{\mathbf{x}}_{t|t-1}) \bigg) - \mathbf{J}^{-1}_{t,j}(\hat{\mathbf{x}}_{t|t,j} - \hat{\mathbf{x}}_{t|t-1})\\
& \quad\quad \quad \hat{\mathbf{x}}_{t|t, j+1} = \hat{\mathbf{x}}_{t|t, j} \boxplus \delta \hat{\mathbf{x}}_{t|t,j} \\
& \quad\quad \quad \text{iterate until } \delta \hat{\mathbf{x}}_{t|t,j} < \epsilon. \\
& \quad\quad \text{end loop} \\
& \quad\quad \mathbf{P}_{t|t,n} = (\mathbf{I} - \mathbf{K}_{t,n}\mathbf{H}_{t,n}) \mathbf{J}^{-1}_{t,n}\mathbf{P}_{t|t-1} \mathbf{J}_{t,n}^{-\intercal} \\
& \quad\quad \text{return} \ \ \hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t} \\
& \}
\end{aligned} }
\end{equation}
MAP, GN, and EKF relationship
Traditional EKF derivation
EKF의 관측 모델 함수가 다음과 같이 주어졌다고 하자. 전개의 편의를 위해 관측 노이즈 $\mathbf{v}_{t}$를 밖으로 위치하였다.
\begin{equation}
\begin{aligned}
& \text{Observation Model: } & \mathbf{z}_{t} = \mathbf{h}(\mathbf{x}_{t}) + \mathbf{v}_{t}
\end{aligned}
\end{equation}
EKF의 correction 스텝은 아래 수식을 전개하여 평균 $\hat{\mathbf{x}}_{t|t}$와 공분산 $\mathbf{P}_{t|t}$를 유도한다.
\begin{equation}
\begin{aligned}
\text{bel}( \mathbf{x}_{t}) = \eta \cdot p(\mathbf{z}_{t} \ | \ \mathbf{x}_{t}) \overline{\text{bel}}( \mathbf{x}_{t}) \sim \mathcal{N}(\hat{\mathbf{x}}_{t|t}, \mathbf{P}_{t|t})
\end{aligned}
\end{equation}
- $p(\mathbf{z}_{t} \ | \ \mathbf{x}_{t}) \sim \mathcal{N}( \mathbf{h}_{t}(\mathbf{x}_{t}) , \mathbf{R}_{t})$
- $\overline{\text{bel}}( \mathbf{x}_{t}) \sim \mathcal{N}( \hat{\mathbf{x}}_{t|t-1}, \mathbf{P}_{t|t-1})$
\begin{equation}
\boxed{ \begin{aligned}
& \hat{\mathbf{x}}_{t|t} = \mathbf{K}_{t} ( \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1})) \\
& \mathbf{P}_{t|t} = (\mathbf{I} - \mathbf{K}_{t}\mathbf{H}_{t})\mathbf{P}_{t|t-1}
\end{aligned} }
\end{equation}
MAP-based EKF derivation
Start from MAP estimator
Correction 스텝을 유도하는 방법으로 posterior의 확률을 최대화하는 maximum a posteriori(MAP) 추정을 사용할 수 있다. 자세한 내용은 [12]를 참고하여 작성하였다.
\begin{equation} \label{eq:map1}
\begin{aligned}
\hat{\mathbf{x}}_{t|t} & = \arg\max_{ \mathbf{x}_{t}} \text{bel}(\mathbf{x}_{t}) \\
& = \arg\max_{ \mathbf{x}_{t}} p(\mathbf{x}_{t} | \mathbf{z}_{1:t}, \mathbf{u}_{1:t}) \quad \cdots \text{posterior} \\
& \propto \arg\max_{ \mathbf{x}_{t}} p(\mathbf{z}_{t} | \mathbf{x}_{t}) \overline{\text{bel}}(\mathbf{x}_{t}) \quad \cdots \text{likelihood} \cdot \text{prior} \\
& \propto \arg\max_{\mathbf{x}_{t}} \exp \bigg( -\frac{1}{2} \bigg[ (\mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t}))^{\intercal} \mathbf{R}_{t}^{-1} (\mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t})) \\
& \quad\quad\quad \quad \quad \quad + ( \mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1})^{\intercal} \mathbf{P}_{t|t-1}^{-1} ( \mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1}) \bigg] \bigg)
\end{aligned}
\end{equation}
- $p(\mathbf{z}_{t} \ | \ \mathbf{x}_{t}) \sim \mathcal{N}( \mathbf{h}_{t}(\mathbf{x}_{t}) , \mathbf{R}_{t})$
- $\overline{\text{bel}}( \mathbf{x}_{t}) \sim \mathcal{N}( \hat{\mathbf{x}}_{t|t-1}, \mathbf{P}_{t|t-1})$
마이너스 부호를 제거하면 최대화(maximization) 문제가 최소화(minimization) 문제로 변하고 다음과 같은 최적화 식으로 정리할 수 있다.
\begin{equation} \label{eq:map2}
\begin{aligned}
\hat{\mathbf{x}}_{t|t} & \propto \arg\min_{\mathbf{x}_{t}} \exp \bigg( (\mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t}))^{\intercal} \mathbf{R}_{t}^{-1} (\mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t})) \\
& \quad\quad\quad\quad\quad\quad + ( \mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1} )^{\intercal} \mathbf{P}^{-1}_{t|t-1} ( \mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1} ) \bigg) \end{aligned}
\end{equation}
\begin{equation} \label{eq:map3}
\boxed{ \begin{aligned}
\hat{\mathbf{x}}_{t|t} & = \arg\min_{\mathbf{x}_{t}} \left\| \mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t}) \right\|_{\mathbf{R}_{t}^{-1}} + \left\| \mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1} \right\|_{\mathbf{P}_{t|t-1}^{-1}}
\end{aligned} }
\end{equation}
- $\left\| \mathbf{a} \right\|_{\mathbf{B}} = \mathbf{a}^{\intercal}\mathbf{B}\mathbf{a}$ : Mahalanobis norm
(\ref{eq:map3}) 내부의 식을 전개하고 cost function $\mathbf{C}_{t}$라고 정의하면 다음과 같다. 이 때, $\mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1}$의 순서를 바꿔도 전체 값에는 영향을 주지 않는다.
\begin{equation}
\begin{aligned}
\mathbf{C}_{t} = (\mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t}))^{\intercal} \mathbf{R}_{t}^{-1} (\mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t})) + ( \hat{\mathbf{x}}_{t|t-1} - \mathbf{x}_{t} )^{\intercal} \mathbf{P}^{-1}_{t|t-1} ( \hat{\mathbf{x}}_{t|t-1} - \mathbf{x}_{t} )
\end{aligned}
\end{equation}
이를 행렬 형태로 표현하면 다음과 같다.
\begin{equation} \label{eq:map4}
\begin{aligned}
\mathbf{C}_{t} = \begin{bmatrix} \hat{\mathbf{x}}_{t|t-1} - \mathbf{x}_{t} \\ \mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t})\end{bmatrix}^{\intercal} \begin{bmatrix} \mathbf{P}^{-1}_{t|t-1} & \mathbf{0} \\ \mathbf{0} & \mathbf{R}^{-1}_{t} \end{bmatrix} \begin{bmatrix} \hat{\mathbf{x}}_{t|t-1} - \mathbf{x}_{t} \\ \mathbf{z}_{t} - \mathbf{h}(\mathbf{x}_{t})\end{bmatrix}
\end{aligned}
\end{equation}
MLE of new observation function
위 식을 만족하는 새로운 관측 함수를 다음과 같이 정의할 수 있다.
\begin{equation}
\boxed{ \begin{aligned}
\mathbf{y}_{t} & = \mathbf{g}(\mathbf{x}_{t}) + \mathbf{e}_{t} \\
& \sim \mathcal{N}(\mathbf{g}(\mathbf{x}_{t}), \mathbf{P}_{\mathbf{e}})
\end{aligned} }
\end{equation}
- $\mathbf{y}_{t} = \begin{bmatrix} \hat{\mathbf{x}}_{t|t-1} \\ \mathbf{z}_{t} \end{bmatrix}$
- $\mathbf{g}(\mathbf{x}_{t}) = \begin{bmatrix} \mathbf{x}_{t} \\ \mathbf{h}(\mathbf{x}_{t}) \end{bmatrix}$
- $\mathbf{e}_{t} \sim \mathcal{N}(0, \mathbf{P}_{\mathbf{e}})$
- $\mathbf{P}_{\mathbf{e}} = \begin{bmatrix} \mathbf{P}_{t|t-1} & \mathbf{0} \\ \mathbf{0} & \mathbf{R}_{t} \end{bmatrix}$
비선형 함수 $\mathbf{g}(\mathbf{x}_{t})$는 다음과 같이 선형화할 수 있다.
\begin{equation}
\begin{aligned}
\mathbf{g}(\mathbf{x}_{t}) & \approx \mathbf{g}(\hat{\mathbf{x}}_{t|t-1}) + \mathbf{J}_{t}(\mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1}) \\
& = \mathbf{g}(\hat{\mathbf{x}}_{t|t-1}) + \mathbf{J}_{t}\delta \hat{\mathbf{x}}_{t|t-1}
\end{aligned}
\end{equation}
자코비안 $\mathbf{J}_{t}$는 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{J}_{t} & = \frac{\partial \mathbf{g}}{\partial \mathbf{x}_{t}}\bigg|_{\mathbf{x}_{t} = \hat{\mathbf{x}}_{t|t-1}} \\
& \frac{\partial \begin{bmatrix} \mathbf{x}_{t} \\ \mathbf{h}(\mathbf{x}_{t}) \end{bmatrix} }{\partial \mathbf{x}_{t}}\bigg|_{\mathbf{x}_{t} = \hat{\mathbf{x}}_{t|t-1}} \\
& \frac{\partial \begin{bmatrix} \mathbf{x}_{t} \\ \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}) + \mathbf{H}_{t} (\mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1}) \end{bmatrix} }{\partial \mathbf{x}_{t}}\bigg|_{\mathbf{x}_{t} = \hat{\mathbf{x}}_{t|t-1}} \\
& = \begin{bmatrix} \mathbf{I} \\ \mathbf{H}_{t} \end{bmatrix}
\end{aligned}
\end{equation}
따라서 다음과 같이 $\mathbf{y}_{t}$에 대한 likelihood를 전개할 수 있다.
\begin{equation} \label{eq:map5}
\begin{aligned}
p(\mathbf{y}_{t} | \mathbf{x}_{t}) & \sim \mathcal{N}(\mathbf{g}(\mathbf{x}_{t}), \mathbf{P}_{\mathbf{e}}) \\
& = \eta \cdot \exp\bigg( -\frac{1}{2}(\mathbf{y}_{t} - \mathbf{g}(\mathbf{x}_{t}))^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1}(\mathbf{y}_{t} - \mathbf{g}(\mathbf{x}_{t})) \bigg)
\end{aligned}
\end{equation}
즉, 기존의 $\text{bel}(\mathbf{x}_{t})$에 대한 maximum a posteriori(MAP) 문제는 $p(\mathbf{y}_{t} | \mathbf{x}_{t})$에 대한 maximum likelihood estimation(MLE) 문제를 푸는 것으로 귀결된다. (\ref{eq:map5}) 식을 MLE로 풀면 다음과 같다.
\begin{equation} \label{eq:map6}
\begin{aligned}
\hat{\mathbf{x}}_{t|t} & = \arg\max_{\mathbf{x}_{t}} p(\mathbf{y}_{t} | \mathbf{x}_{t}) \\
& \propto \arg\min_{\mathbf{x}_{t}} -\ln p(\mathbf{y}_{t} | \mathbf{x}_{t}) \\
& \propto \arg\min_{\mathbf{x}_{t}} \frac{1}{2} (\mathbf{y}_{t} - \mathbf{g}(\mathbf{x}_{t}))^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1}(\mathbf{y}_{t} - \mathbf{g}(\mathbf{x}_{t})) \\
& \propto \arg\min_{\mathbf{x}_{t}} \left\| \mathbf{y}_{t} - \mathbf{g}(\mathbf{x}_{t}) \right\|_{\mathbf{P}_{\mathbf{e}}^{-1}}
\end{aligned}
\end{equation}
Gauss-Newton Optimization
(\ref{eq:map6}) 식은 최소제곱법의 형태를 지닌다. 특히 가중치 $\mathbf{P}_{\mathbf{e}}^{-1}$가 중간에 곱해지므로 weighted least squares(WLS)라고도 부른다. 식을 선형화한 후 다시 정리하면 아래와 같다.
\begin{equation}
\begin{aligned}
\hat{\mathbf{x}}_{t|t} & = \arg\min_{\mathbf{x}_{t}} \left\| \mathbf{y}_{t} - \mathbf{g}(\mathbf{x}_{t}) \right\|_{\mathbf{P}_{\mathbf{e}}^{-1}} \\
& = \arg\min_{\mathbf{x}_{t}} \left\| \mathbf{y}_{t} - \mathbf{g}(\hat{\mathbf{x}}_{t|t-1}) - \mathbf{J}_{t} \delta \hat{\mathbf{x}}_{t|t-1} \right\|_{\mathbf{P}_{\mathbf{e}}^{-1}} \\
& = \arg\min_{\mathbf{x}_{t}} \left\| \mathbf{J}_{t} \delta \hat{\mathbf{x}}_{t|t-1} - (\mathbf{y}_{t} - \mathbf{g}(\hat{\mathbf{x}}_{t|t-1}) ) \right\|_{\mathbf{P}_{\mathbf{e}}^{-1}} \\
& = \arg\min_{\mathbf{x}_{t}} \left\| \mathbf{J}_{t} \delta \hat{\mathbf{x}}_{t|t-1} - \mathbf{r}_{t} \right\|_{\mathbf{P}_{\mathbf{e}}^{-1}} \\
\end{aligned}
\end{equation}
- $\delta \hat{\mathbf{x}}_{t|t-1} = \mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1}$ : 표현의 편의를 위해 $\mathbf{x}_{t}$를 true 상태로 표현
선형화된 residual term $\mathbf{r}_{t}$는 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{r}_{t} & = \mathbf{y}_{t} - \mathbf{g}(\hat{\mathbf{x}}_{t|t-1}) \\
& = \mathbf{J}_{t} \delta \hat{\mathbf{x}}_{t|t-1} + \mathbf{e} \\ & \sim \mathcal{N}(0, \mathbf{P}_{\mathbf{e}})
\end{aligned}
\end{equation}
GN의 정규방정식으로 통해 해를 구하면 다음과 같다.
\begin{equation}
\begin{aligned}
& (\mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbf{J}_{t}) \delta \hat{\mathbf{x}}_{t|t-1} = \mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbf{r}_{t} \\
\end{aligned}
\end{equation}
\begin{equation}
\boxed{ \begin{aligned} & \therefore \delta \hat{\mathbf{x}}_{t|t-1} = (\mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1}\mathbf{J}_{t})^{-1} \mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbf{r}_{t}
\end{aligned} }
\end{equation}
위 식에서 $(\mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbf{J}_{t})$ 부분을 일반적으로 근사 헤시안(approximate hessian) 행렬 $\tilde{\mathbf{H}}$이라고 부른다.
Posterior covariance matrix $\mathbf{P}_{t|t}$
$\mathbf{P}_{t|t}$는 다음과 같이 구할 수 있다.
\begin{equation}
\boxed{ \begin{aligned}
\mathbf{P}_{t|t}
=& \mathbb{E}[(\mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1})(\mathbf{x}_{t} - \hat{\mathbf{x}}_{t|t-1})^{\intercal}] \\
=& \mathbb{E}(\delta \hat{\mathbf{x}}_{t|t-1}\delta \hat{\mathbf{x}}_{t|t-1}^{\intercal}) \\
=& \mathbb{E}\bigg[
(\mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbf{J}_{t})^{-1} \mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbf{r}_{t}
\mathbf{r}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-\intercal} \mathbf{J}_{t} (\mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbf{J}_{t})^{-\intercal} \bigg] \\
=&
(\mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbf{J}_{t})^{-1} \mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbb{E}(\mathbf{r}_{t}
\mathbf{r}_{t}^{\intercal}) \mathbf{P}_{\mathbf{e}}^{-\intercal} \mathbf{J}_{t} (\mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbf{J}_{t})^{-\intercal} \quad {\color{Mahogany}\leftarrow \mathbb{E}(\mathbf{r}_{t}\mathbf{r}_{t}^{\intercal}) = \mathbf{P}_{\mathbf{e}} } \\
=& \left(
{\color{Mahogany}{\mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbf{J}_{t}}}
\right)^{-1} \\
=& \left(
\begin{bmatrix} \mathbf{I} & \mathbf{H}_{t}^{\intercal} \end{bmatrix}
\begin{bmatrix} \mathbf{P}_{t|t-1} & \mathbf{0} \\ \mathbf{0} & \mathbf{R}_{t} \end{bmatrix}^{-1}
\begin{bmatrix} \mathbf{I} \\ \mathbf{H}_{t} \end{bmatrix}
\right)^{-1} \\
=& \left( \mathbf{P}_{t|t-1}^{-1} + \mathbf{H}_{t}^{\intercal}\mathbf{R}_{t}^{-1}\mathbf{H}_{t} \right)^{-1} \\
=& \mathbf{P}_{t|t-1} - \mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal} (\mathbf{H}_{t}\mathbf{P}_{t|t-1}\mathbf{H}_{t}^{\intercal} + \mathbf{R}_{t})^{-1} \mathbf{H}_{t} \mathbf{P}_{t|t-1} \quad {\color{Mahogany} \leftarrow \text{matrix inversion lemmas} } \\
=& {\color{Mahogany}{(\mathbf{I} - \mathbf{K}_{t}\mathbf{H}_{t}) \mathbf{P}_{t|t-1}}}
\end{aligned} }
\end{equation}
위 식의 다섯번 째 줄에서 보다시피 GN을 통해 구한 근사 헤시안 행렬의 역함수 $\tilde{\mathbf{H}}^{-1}$와 EKF의 posterior 공분산 $\mathbf{P}_{t|t}$는 같은 값을 가지는 것을 알 수 있다.
\begin{equation}
\begin{aligned}
\tilde{\mathbf{H}}^{-1} = (\mathbf{J}_{t}^{\intercal} \mathbf{P}_{\mathbf{e}}^{-1} \mathbf{J}_{t})^{-1} = \mathbf{P}_{t|t}
\end{aligned}
\end{equation}
Posterior mean $\mathbf{x}_{t|t}$
GN을 반복적으로 수행함에 따라 $j$번째 $\mathbf{x}_{t|t, j}$는 다음과 같이 구할 수 있다.
\begin{equation}
\boxed{ \begin{aligned}
\hat{\mathbf{x}}_{t|t,j+1}
=& \hat{\mathbf{x}}_{t|t,j} + \delta \hat{\mathbf{x}}_{t|t,j} \\
=& \hat{\mathbf{x}}_{t|t,j} + (\mathbf{J}_{t}^{\intercal} \mathbf{P}_{t|t-1}^{-1} \mathbf{J}_{t})^{-1} (\mathbf{J}_{t}^{\intercal} \mathbf{P}_{t|t-1}^{-1} \mathbf{r}_{t}) \\
=& (\mathbf{J}_{t}^{\intercal} \mathbf{P}_{t|t-1}^{-1} \mathbf{J}_{t})^{-1} \mathbf{J}_{t}^{\intercal} \mathbf{P}_{t|t-1}^{-1} (\mathbf{y}_{t} - \mathbf{g}(\hat{\mathbf{x}}_{t|t,j}) + \mathbf{J}_{t} \hat{\mathbf{x}}_{t|t,j}) \quad {\color{Mahogany} \leftarrow \mathbf{r}_{t} = \mathbf{y}_{t} - \mathbf{g}(\hat{\mathbf{x}}_{t|t,j}) }\\
=&
\left( \mathbf{P}_{t|t-1}^{-1} + \mathbf{H}_{t}^{\intercal}\mathbf{R}_{t}^{-1} \mathbf{H}_{t} \right)^{-1}
\begin{bmatrix} \mathbf{P}_{t|t-1}^{-1} & \mathbf{H}_{t}^{\intercal}\mathbf{R}_{t}^{-1} \end{bmatrix}
\begin{bmatrix}
\hat{\mathbf{x}}_{t|t-1} \\
\mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}) + \mathbf{H}_{t} \hat{\mathbf{x}}_{t|t,j}
\end{bmatrix} \quad {\color{Mahogany} \leftarrow \text{expand } \mathbf{J}_{t} } \\
=&
\left( \mathbf{P}_{t|t-1}^{-1} + \mathbf{H}_{t}^{\intercal}\mathbf{R}_{t}^{-1} \mathbf{H}_{t} \right)^{-1}
\left(
\mathbf{H}_{t}^{\intercal}\mathbf{R}_{t}^{-1}(\mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}) + \mathbf{H}_{t} \hat{\mathbf{x}}_{t|t,j}) + \mathbf{P}_{t|t-1}^{-1} \hat{\mathbf{x}}_{t|t-1}
\right) \\
=&
\left( \mathbf{P}_{t|t-1}^{-1} + \mathbf{H}_{t}^{\intercal}\mathbf{R}_{t}^{-1} \mathbf{H}_{t} \right)^{-1}
\left(
\mathbf{H}^{\intercal}\mathbf{R}_{t}^{-1}(\mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}) - \mathbf{H}_{t}(\hat{\mathbf{x}}_{t|t-1} - \hat{\mathbf{x}}_{t|t,j}) + \mathbf{H}_{t} \hat{\mathbf{x}}_{t|t-1}) + \mathbf{P}_{t|t-1}^{-1} \hat{\mathbf{x}}_{t|t-1}
\right) \\
=&
\left( \mathbf{P}_{t|t-1}^{-1} + \mathbf{H}_{t}^{\intercal}\mathbf{R}_{t}^{-1} \mathbf{H}_{t} \right)^{-1}
\left(
\mathbf{H}^{\intercal}\mathbf{R}_{t}^{-1}(\mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}) - \mathbf{H}_{t}(\hat{\mathbf{x}}_{t|t-1} - \hat{\mathbf{x}}_{t|t,j})) + \underbrace{(\mathbf{P}_{t|t-1}^{-1} + \mathbf{H}_{t}^{\intercal}\mathbf{R}_{t}^{-1} \mathbf{H}_{t} )\hat{\mathbf{x}}_{t|t-1}}_{\hat{\mathbf{x}}_{t|t-1}}
\right) \\
=&
\hat{\mathbf{x}}_{t|t-1} +
{\color{Mahogany}{
\left( \mathbf{P}_{t|t-1}^{-1} + \mathbf{H}_{t}^{\intercal}\mathbf{R}_{t}^{-1} \mathbf{H}_{t} \right)^{-1} \mathbf{H}_{t}^{\intercal}\mathbf{R}_{t}^{-1}
}}
(\mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}) - \mathbf{H}_{t}(\hat{\mathbf{x}}_{t|t-1} - \hat{\mathbf{x}}_{t|t,j})) \\
=&
\hat{\mathbf{x}}_{t|t-1} + {\color{Mahogany}{ \mathbf{K}_{t} }} (\mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}) - \mathbf{H}_{t}(\hat{\mathbf{x}}_{t|t-1} - \hat{\mathbf{x}}_{t|t,j}))
\end{aligned} }
\end{equation}
위 식은 IEKF의 (\ref{eq:iekf-cor}) 식과 동일하다. 마지막 식에서 보다시피 Gauss-Newton을 통해 EKF의 해를 추정하는 것과 IEKF를 통해 해를 추정하는 것은 동일한 의미를 지닌다. 만약 처음 iteration $j=0$인 경우 $\hat{\mathbf{x}}_{t|t,0} = \hat{\mathbf{x}}_{t|t-1}$이 되어서 식은 다음과 같이 정리된다.
\begin{equation}
\boxed{ \begin{aligned}
\hat{\mathbf{x}}_{t|t} = \hat{\mathbf{x}}_{t|t-1} + \mathbf{K}_{t} (\mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}))
\end{aligned} }
\end{equation}
이는 EKF의 해와 동일하다. 즉, EKF는 GN iteration=1과 동일한 의미를 지니며 IEKF는 GN과 동일한 연산을 수행하는 것을 알 수 있다.
Derivation of IESKF update step
본 섹션에서는 IESKF 과정 중 업데이트 스텝부터 $\delta \hat{\mathbf{x}}$를 구하는 중간 유도 과정에 대해 설명한다. 이는 주로 링크의 내용을 참고하여 유도하였다. 우선 (\ref{eq:ieskf6}) 업데이트 공식부터 다시 살펴보자
\begin{equation}
\boxed{ \begin{aligned}
\arg\min_{\delta \hat{\mathbf{x}}_{t|t,j}} \quad & \left\| \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0, 0) - \mathbf{H}_{t} \delta\hat{\mathbf{x}}_{t|t,j} \right\|_{\mathbf{H}_{\mathbf{v}}\mathbf{R}^{-1}\mathbf{H}_{\mathbf{v}}^{\intercal}} + \left\| \hat{\mathbf{x}}_{t|t,j} - \hat{\mathbf{x}}_{t|t-1} + \mathbf{J}_{t,j}\delta\hat{\mathbf{x}}_{t|t,j} \right\|_{\mathbf{P}_{t|t-1}^{-1}}
\end{aligned} }
\end{equation}
위 식의 기호를 단순화하여 다음과 같이 나타낸다
\begin{equation*} \begin{aligned}
\mathbf{x}
= \arg\min_{\mathbf{x}} \quad \left\| \mathbf{z} - \mathbf{H}\mathbf{x} \right\|^{2}_{\mathbf{R}} + \left\| \mathbf{c} + \mathbf{J}\mathbf{x} \right\|^{2}_{\mathbf{P}}
\end{aligned}
\end{equation*}
- $\mathbf{z} = \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0, 0)$
- $\mathbf{c} = \hat{\mathbf{x}}_{t|t,j} - \hat{\mathbf{x}}_{t|t-1}$
- $\mathbf{R} = \mathbf{H}_{\mathbf{v}}\mathbf{R}^{-1}\mathbf{H}_{\mathbf{v}}^{\intercal}$
- $\mathbf{x} = \delta \hat{\mathbf{x}}$
위 식에서 norm을 전개하면 다음과 같다.
\begin{equation*} \begin{aligned}
\mathbf{x} = \arg\min_{\mathbf{x}} \ \bigg[ \underbrace{ (\mathbf{z} - \mathbf{H}\mathbf{x})^{\intercal}\mathbf{R}^{-1}(\mathbf{z} - \mathbf{H}\mathbf{x}) + (\mathbf{c} + \mathbf{J}\mathbf{x})^{\intercal}\mathbf{P}^{-1}(\mathbf{c} + \mathbf{J}\mathbf{x}) }_{\mathbf{r}} \bigg]
\end{aligned}
\end{equation*}
위 식에서 $\mathbf{r}$ 부분만 따로 전개하면 다음과 같다.
\begin{equation}
\begin{aligned}
\mathbf{r} & = \mathbf{z}^{\intercal}\mathbf{R}^{-1}\mathbf{z} {\color{Mahogany} - \mathbf{x}^{\intercal}\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{z}- \mathbf{z}^{\intercal}\mathbf{R}^{-1}\mathbf{H}\mathbf{x} } + \mathbf{x}^{\intercal}\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{H}\mathbf{x} + \mathbf{c}^{\intercal}\mathbf{P}^{-1}\mathbf{c} + {\color{Mahogany} \mathbf{x}^{\intercal}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c} + \mathbf{c}^{\intercal}\mathbf{P}^{-1}\mathbf{J}\mathbf{x} } + \mathbf{x}^{\intercal}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{J}\mathbf{x} \\
& = \mathbf{z}^{\intercal}\mathbf{R}^{-1}\mathbf{z} {\color{Mahogany} - 2\mathbf{x}^{\intercal}\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{z} } + \mathbf{x}^{\intercal}\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{H}\mathbf{x} + \mathbf{c}^{\intercal}\mathbf{P}^{-1}\mathbf{c} {\color{Mahogany} + 2\mathbf{x}^{\intercal}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c} } + \mathbf{x}^{\intercal}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{J}\mathbf{x}
\end{aligned}
\end{equation}
$\mathbf{r}$을 $\mathbf{x}$에 대해 편미분하면 다음과 같다.
\begin{equation} \label{eq:deriveieskf1}
\begin{aligned}
\frac{\partial \mathbf{r}}{\partial {\mathbf{x}}} = - \mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{z} + \mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{H}\mathbf{x} +\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c} + \mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{J}\mathbf{x} & = 0 \\
{\color{Mahogany} (\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{H} + \mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{J}) } \mathbf{x} & =
\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{z} - \mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c} \\
\mathbf{x} & = {\color{Mahogany}(\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{H} + \mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{J})^{-1} } (
\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{z} - \mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c})
\end{aligned}
\end{equation}
$(\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{H} + \mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{J})^{-1}$ 부분은 matrix inversion lemma를 통해 다음과 같이 전개할 수 있다.
\begin{equation}
\begin{aligned}
{\color{Mahogany}(\underbrace{\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{J}}_{\bar{\mathbf{P}}^{-1}} +\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{H})^{-1} = (\bar{\mathbf{P}} -\bar{\mathbf{P}}\mathbf{H}^{\intercal}(\mathbf{R} + \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal})^{-1}\mathbf{H}\bar{\mathbf{P}} }
\end{aligned}
\end{equation}
- $\bar{\mathbf{P}} = \mathbf{J}^{-1}\mathbf{P}\mathbf{J}^{-\intercal}$로 치환
Matrix Inversion Lemma
$(\mathbf{A}+\mathbf{UCV})^{-1}=\mathbf{A}^{-1}-\mathbf{A}^{-1}\mathbf{U}(\mathbf{C}^{-1}+\mathbf{VA}^{-1}\mathbf{U})^{-1}\mathbf{VA}^{-1}$
위 식을 (\ref{eq:deriveieskf1}) 식에 대입하면 다음과 같다.
\begin{equation}
\begin{aligned}
{\mathbf{x}} = {\color{Mahogany}(\bar{\mathbf{P}} -\bar{\mathbf{P}}\mathbf{H}^{\intercal}(\mathbf{R} + \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal})^{-1}\mathbf{H}\bar{\mathbf{P}})} (
\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{z} - \mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c})
\end{aligned}
\end{equation}
위 식을 전개하면 다음과 같다
\begin{equation}
\begin{aligned}
{\mathbf{x}} & = (\bar{\mathbf{P}} -\bar{\mathbf{P}}\mathbf{H}^{\intercal}(\mathbf{R} + \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal})^{-1}\mathbf{H}\bar{\mathbf{P}})(
\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{z} - \mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c}) \\
& = \bar{\mathbf{P}}\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{z} - \bar{\mathbf{P}}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c}
-\bar{\mathbf{P}}\mathbf{H}^{\intercal}(\mathbf{R} + {\color{Mahogany} \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal})^{-1} } \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal}\mathbf{R}^{-1} \mathbf{z} +\bar{\mathbf{P}}\mathbf{H}^{\intercal}(\mathbf{R} + \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal})^{-1}\mathbf{H}\bar{\mathbf{P}}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c} \\
& = \bar{\mathbf{P}}\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{z} - \bar{\mathbf{P}}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c}
-\bar{\mathbf{P}}\mathbf{H}^{\intercal} \cancel{ (\mathbf{R} + \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal})^{-1} } ({\color{Mahogany} \cancel{ (\mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal}+\mathbf{R})} \mathbf{R}^{-1} - \mathbf{I}) } \mathbf{z} +\bar{\mathbf{P}}\mathbf{H}^{\intercal}(\mathbf{R} + \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal})^{-1}\mathbf{H}\bar{\mathbf{P}}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c} \\
& = \cancel{ \bar{\mathbf{P}}\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{z} } - \bar{\mathbf{P}}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c}
- \cancel{ \bar{\mathbf{P}}\mathbf{H}^{\intercal}\mathbf{R}^{-1}\mathbf{z} } + \bar{\mathbf{P}}\mathbf{H}^{\intercal}(\mathbf{R} + \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal})^{-1}\mathbf{z} +\bar{\mathbf{P}}\mathbf{H}^{\intercal}(\mathbf{R} + \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal})^{-1}\mathbf{H}\bar{\mathbf{P}}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c} \\
& = - \bar{\mathbf{P}}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c}
+ \bar{\mathbf{P}}\mathbf{H}^{\intercal}(\mathbf{R} + \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal})^{-1}\mathbf{z} +\bar{\mathbf{P}}\mathbf{H}^{\intercal}(\mathbf{R} + \mathbf{H}\bar{\mathbf{P}}\mathbf{H}^{\intercal})^{-1}\mathbf{H}\bar{\mathbf{P}}\mathbf{J}^{\intercal}\mathbf{P}^{-1}\mathbf{c} \\
& = - \mathbf{J}^{-1}\underbrace{\mathbf{P}\mathbf{J}^{-\intercal}\mathbf{J}^{\intercal}\mathbf{P}^{-1}}_{\mathbf{I}} \mathbf{c}
+ {\color{Cyan} \mathbf{J}^{-1}\mathbf{P}\mathbf{J}^{-\intercal}\mathbf{H}^{\intercal}( \underbrace{\mathbf{R} + \mathbf{H}\mathbf{J}^{-1}\mathbf{P}\mathbf{J}^{-\intercal}\mathbf{H}^{\intercal}}_{\mathbf{S}})^{-1} } \mathbf{z} +{\color{Cyan} \mathbf{J}^{-1}\mathbf{P}\mathbf{J}^{-\intercal}\mathbf{H}^{\intercal}(\underbrace{\mathbf{R} + \mathbf{H}\mathbf{J}^{-1}\mathbf{P}\mathbf{J}^{-\intercal}\mathbf{H}^{\intercal}}_{\mathbf{S}})^{-1} } \mathbf{HJ}^{-1}\underbrace{\mathbf{PJ}^{-\intercal}\mathbf{J}^{\intercal}\mathbf{P}^{-1}}_{\mathbf{I}} \mathbf{c} \\
& = {\color{Cyan} \mathbf{K} } \mathbf{z} + {\color{Cyan} \mathbf{K} } \mathbf{H}\mathbf{J}^{-1}\mathbf{c} - \mathbf{J}^{-1}\mathbf{c}
\end{aligned}
\end{equation}
- $\mathbf{K} = \mathbf{J}^{-1}\mathbf{PJ}^{-\intercal}\mathbf{H}^{\intercal}\mathbf{S}^{-1}$
위 마지막 줄의 식에서 치환했던 기호를 복원하면 다음과 같이 최종 업데이트 식 (\ref{eq:ieskf8})를 얻을 수 있다.
\begin{equation}
\boxed{ \begin{aligned}
\therefore \delta \hat{\mathbf{x}}_{t|t,j} = \mathbf{K}_{t,j} \bigg( \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t,j}, 0 ,0) + \mathbf{H}_{t,j}\mathbf{J}^{-1}_{t,j}(\hat{\mathbf{x}}_{t|t,j} - \hat{\mathbf{x}}_{t|t-1}) \bigg) - \mathbf{J}^{-1}_{t,j}(\hat{\mathbf{x}}_{t|t,j} - \hat{\mathbf{x}}_{t|t-1})
\end{aligned} }
\end{equation}
- $\mathbf{z} = \mathbf{z}_{t} - \mathbf{h}(\hat{\mathbf{x}}_{t|t-1}, 0, 0)$
- $\mathbf{c} = \hat{\mathbf{x}}_{t|t,j} - \hat{\mathbf{x}}_{t|t-1}$
- $\mathbf{R} = \mathbf{H}_{\mathbf{v}}\mathbf{R}^{-1}\mathbf{H}_{\mathbf{v}}^{\intercal}$
- $\mathbf{x} = \delta \hat{\mathbf{x}}$
지금까지의 유도 과정을 그림으로 나타내면 다음과 같다.


Wrap-up
지금까지 설명한 KF, EKF, ESKF, IEKF, IESKF를 한 장의 슬라이드로 표현하면 다음과 같다. 클릭하면 큰 그림으로 볼 수 있다.
Kalman Filter (KF)
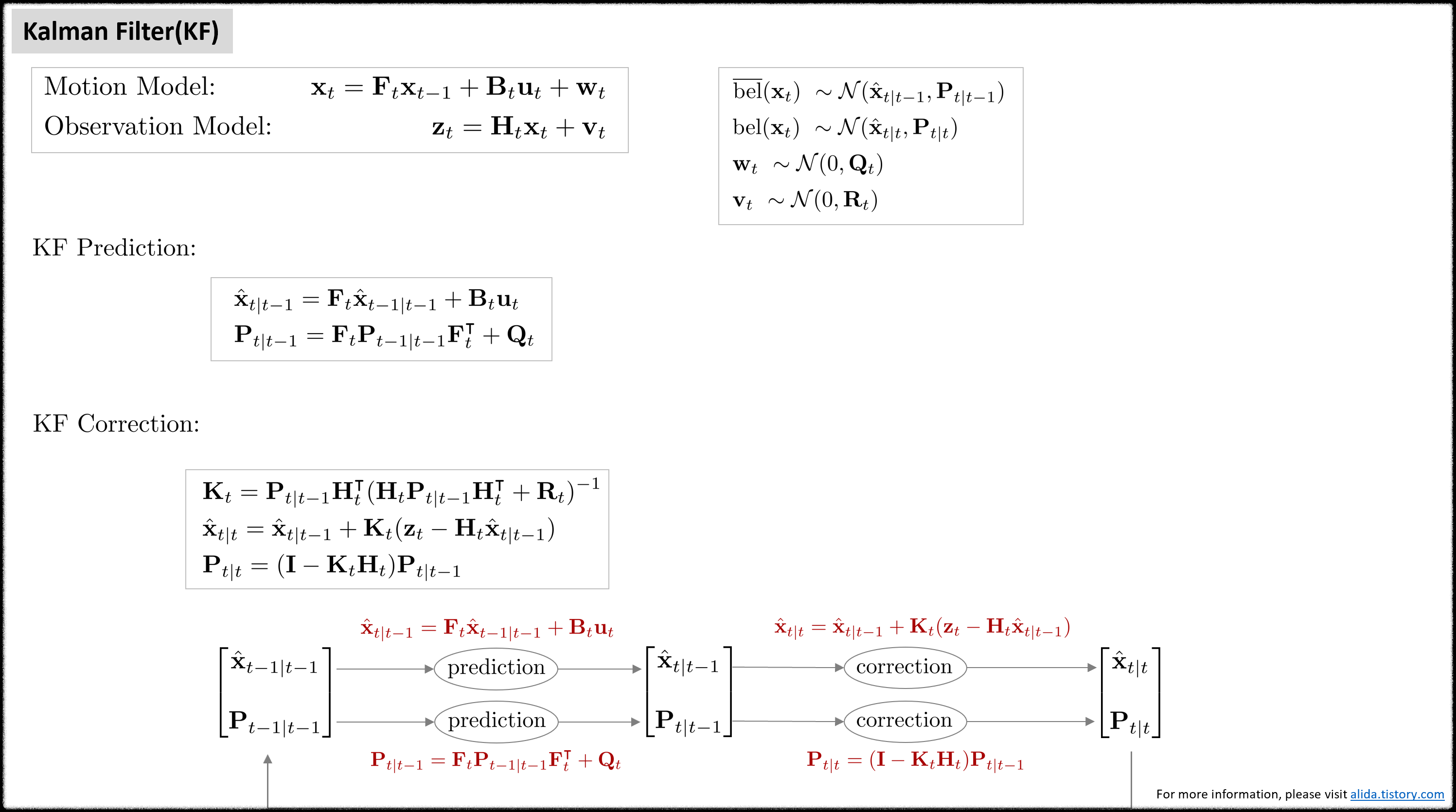
Extended Kalman Filter (EKF)

Error-state Kalman Filter (ESKF)
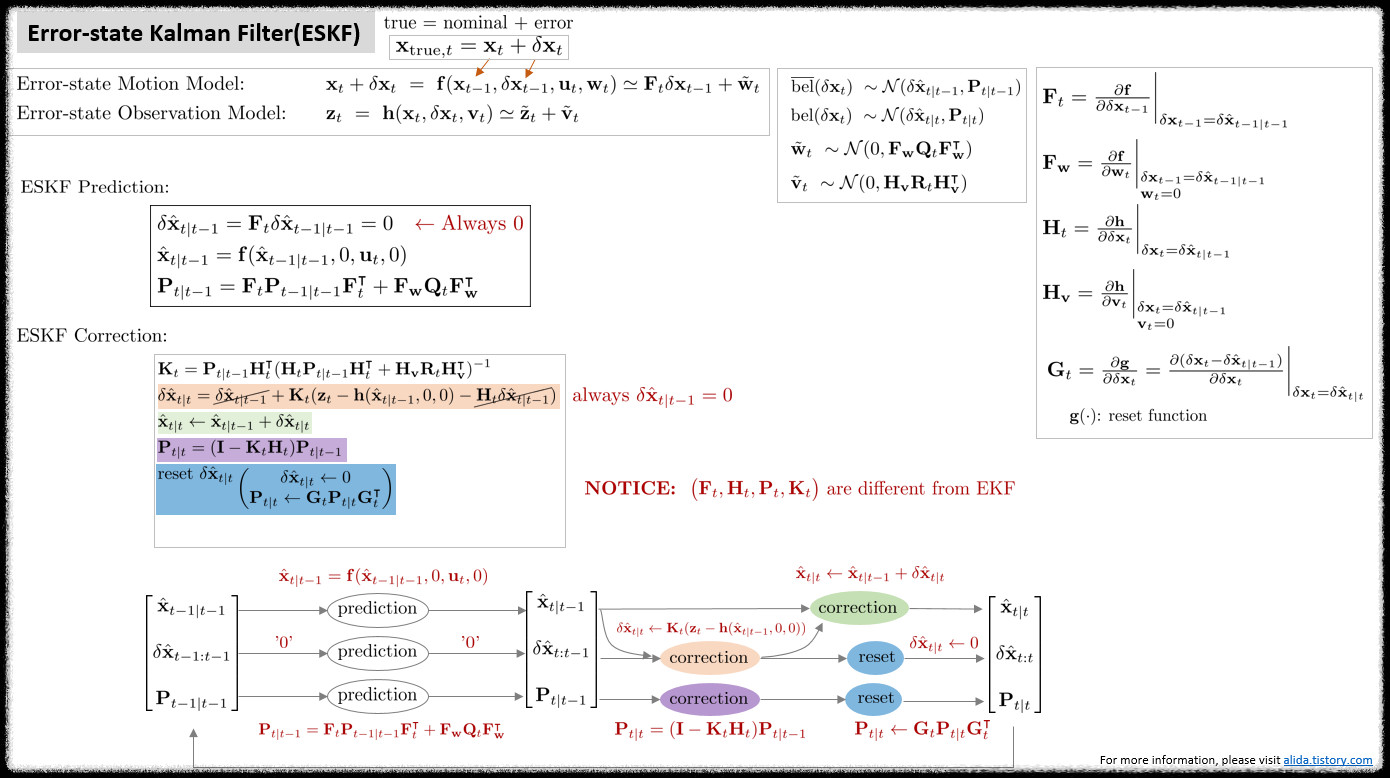
Iterated Extended Kalman Filter (IEKF)
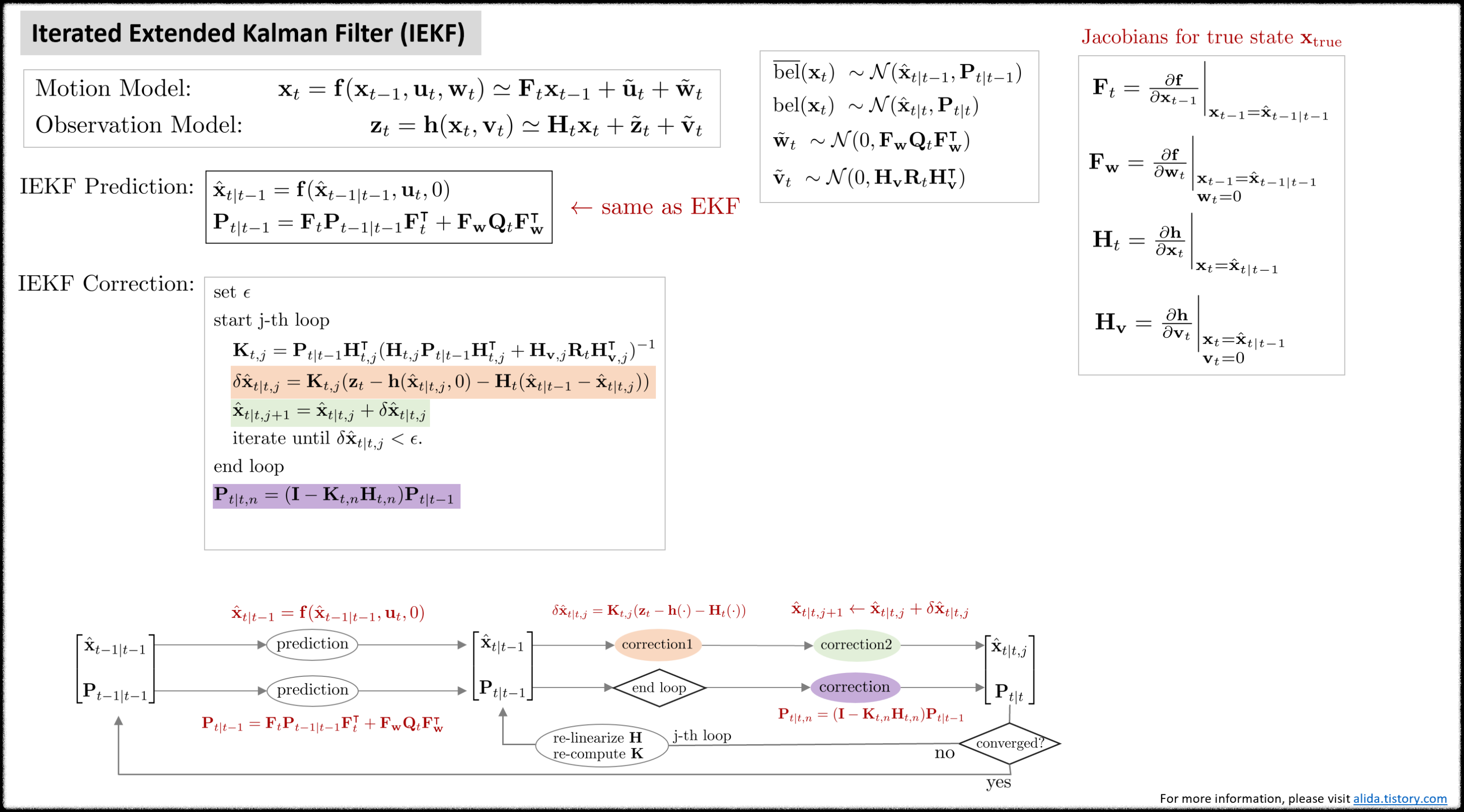
Iterated Error-state Kalman Filter (IESKF)
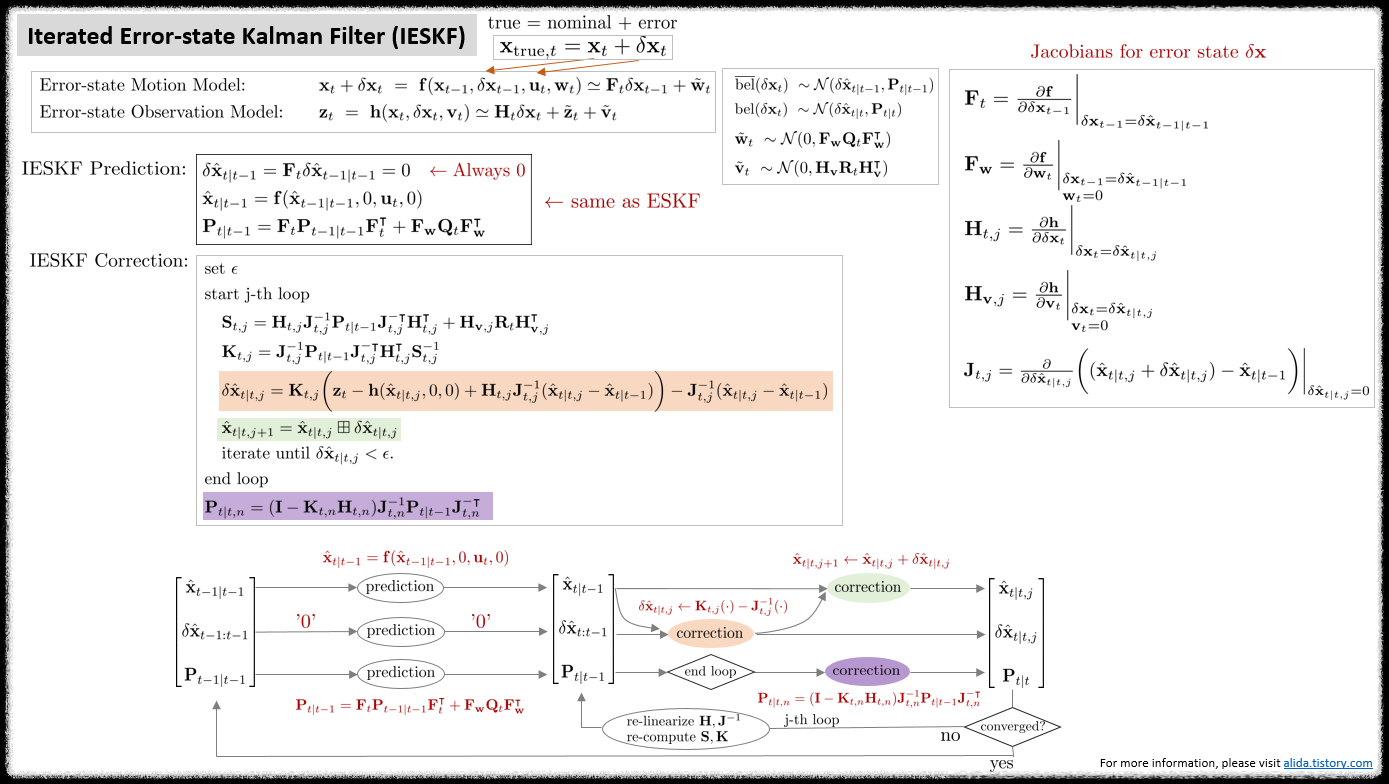
References
[1] Kalman Filter - Wikipedia
[2] (Paper) Sola, Joan. "Quaternion kinematics for the error-state Kalman filter." arXiv preprint arXiv:1711.02508 (2017).
[3] (Youtube) Robot Mapping Coure - Freiburg Univ
[4] (Blog) [SLAM] Kalman filter and EKF(Extended Kalman Filter) - jinyongjeong
[5] (Blog) Error-State Kalman Filter understanding and formula derivation - CSDN
[6] (Paper) He, Dongjiao, Wei Xu, and Fu Zhang. "Kalman filters on differentiable manifolds." arXiv preprint arXiv:2102.03804 (2021).
[7] (Book) SLAM in Autonomous Driving book (SAD book)
[8] (Paper) Xu, Wei, and Fu Zhang. "Fast-lio: A fast, robust lidar-inertial odometry package by tightly-coupled iterated kalman filter." IEEE Robotics and Automation Letters 6.2 (2021): 3317-3324.
[9] (Paper) Huai, Jianzhu, and Xiang Gao. "A Quick Guide for the Iterated Extended Kalman Filter on Manifolds." arXiv preprint arXiv:2307.09237 (2023).
[10] (Paper) Bloesch, Michael, et al. "Iterated extended Kalman filter based visual-inertial odometry using direct photometric feedback." The International Journal of Robotics Research 36.10 (2017): 1053-1072.
[11] (Paper) Skoglund, Martin A., Gustaf Hendeby, and Daniel Axehill. "Extended Kalman filter modifications based on an optimization view point." 2015 18th International Conference on Information Fusion (Fusion). IEEE, 2015.
[12] (Blog) From MAP, MLE, OLS, GN to IEKF, EKF
[13] (Book) Thrun, Sebastian. "Probabilistic robotics." Communications of the ACM 45.3 (2002): 52-57.
'Fundamental' 카테고리의 다른 글
| Quaternion kinematics for the error-state Kalman filter 내용 정리 Part 2 (5) | 2022.08.31 |
|---|---|
| Quaternion kinematics for the error-state Kalman filter 내용 정리 Part 1 (4) | 2022.08.27 |
| 선형대수학 (Linear Algebra) 개념 정리 Part 2 (0) | 2022.06.18 |
| [SLAM] Optical Flow와 Direct Method 개념 및 코드 리뷰 (0) | 2022.06.16 |
| [SLAM] Bundle Adjustment 개념 리뷰 (3) | 2022.06.10 |





